







logistic回归分类的主要思想:根据现有的数据对分类边界线建立回归公式,以此分类,这里“回归”源于最佳拟合,表示要找到最佳拟合参数集。训练分类器时就是寻找最佳拟合参数。
Sigmoid函数:
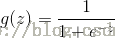
Sigmoid函数的输入记为z,且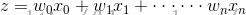
为了实现logistic回归分类器,我们可以在每个特征上乘以一个回归系数W,再把所有的相乘结果相加,然后将总和带入Sigmoid函数中,得到一个0到1之间的数值,如果该值大于0.5,那么该数据被分入1类,小于0.5的即归为0类。所以logistic回归也可以被看成一种概率估计。
我们假设预测函数为:
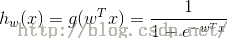
由此可知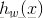
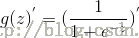
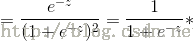
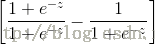
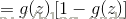
我们记:
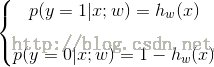
两式可以合并为:
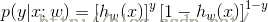
那么怎么求解最优参数?一般地对参数W求其最大似然估计即可,但是对于此处无法令其对数似然函数为0,因为它不为0,因此,可以通过迭代来求解。那么怎么才可以快速达到最大值,那么就利用梯度上升,即:
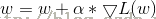
因为朝着梯度方向,上升最快,其中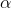
假定n个训练样本是相互独立的,那么对于参数w的最大似然估计为:
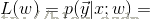
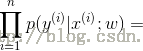
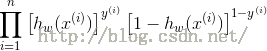
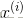
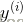
两端取对数:
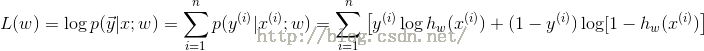
(错误:此处L(w)应该为小写l(w)),对于一个训练样本(x, y),有:
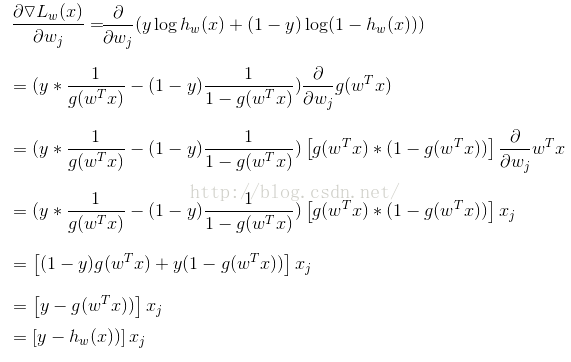
(错误:上式第一行应该把下三角梯度符号去掉,L(w)为小写l(w))。因此:给出随机梯度上升规则为,这也是代码实现时,比较那么理解的一部分:
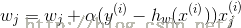
其中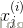
Python代码实现:
1、读取数据并处理数据
def LoadDataSet():
data_list = []
label_list = []
fr = open("testSet.txt")
for line in fr.readlines():
line_arr = line.strip().split()
data_list.append([1.0, float(line_arr[0]), float(line_arr[1])])
label_list.append(int(line_arr[2]))
return data_list, label_list
def SigmoidFuction(inx):
return 1.0/(1+exp(-inx))
def GradientAscent(data_list, label_list):
data_matrix = mat(data_list)#100*3
label_matrix = mat(label_list).transpose() #100*1
row, col = shape(data_matrix)
weights = ones((col, 1))
alpha = 0.01
max_cycles = 500
for i in xrange(max_cycles):
h = SigmoidFuction(data_matrix*weights)#100*1
error = label_matrix - h#100*1
weights = weights + alpha*data_matrix.transpose()*error
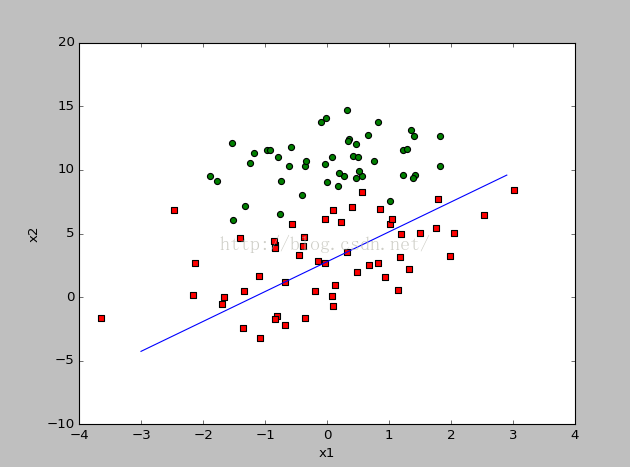
return weights4、把样本全部画出来,以及分类界线
def PlotBestFit(weights):
import matplotlib.pyplot as plt
data_list, label_list = LoadDataSet()
data_array = array(data_list)
row = shape(data_array)[0]
xcord1 = []; ycord1 = []#1类样本的坐标
xcord2 = []; ycord2 = []#0类样本的坐标
for i in xrange(row):#存储样本的坐标
if int(label_list[i]) == 1:
xcord1.append(data_array[i, 1]); ycord1.append(data_array[i, 2])
else:
xcord2.append(data_array[i, 1]); ycord2.append(data_array[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s = 30, c = 'red', marker = 's')
ax.scatter(xcord2, ycord2, s = 30, c = 'green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]#根据w0*x0+w1*x1+w2*x2 = 0,其中x0 = 1, x1 = x,则可算出x2,即y
ax.plot(x, y)#分类界线
plt.xlabel('x1'); plt.ylabel('x2')
plt.show()
5、由于在更新系数的时候,整个数据集都要参与运算,因此当数据比较大的时候,计算代价会非常大,因此对梯度上升法提出改进,称之为随机梯度上升法。
def StocGradientAscent0(data_matrix, label_list):
row, col = shape(data_matrix)
#print row, col
alpha = 0.01
weights = ones(col)
for i in xrange(row):
h = SigmoidFuction(sum(data_matrix[i]*weights))
error = label_list[i] - h
weights = weights + alpha * error * data_matrix[i]
return weights
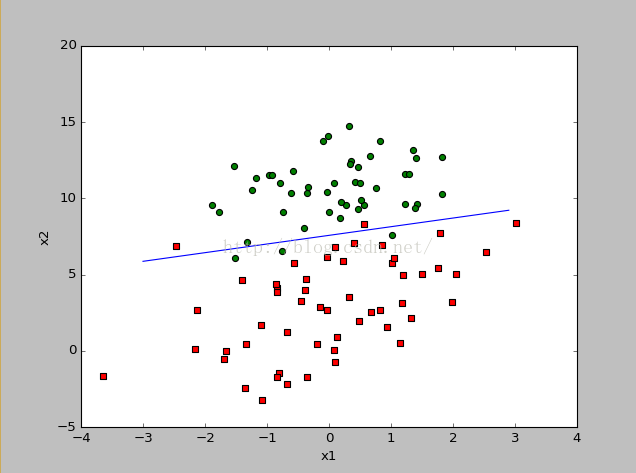
6、改进随机梯度上升方法
def StocGradientAscent1(data_matrix, label_list, num_iteration):
row, col = shape(data_matrix)
weights = ones(col)
for j in xrange(num_iteration):
data_index = range(row)
for i in xrange(row):
alpha = 4/(1.0+j+i) + 0.01
rand_index = int(random.uniform(0, len(data_index)))
h = SigmoidFuction(sum(data_matrix[rand_index]*weights))
error = label_list[rand_index] - h
weights = weights + alpha * error * data_matrix[rand_index]
del(data_index[rand_index])
return weights
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 05 22:18:59 2016
@author: G
"""
from numpy import*
def LoadDataSet():
data_list = []
label_list = []
fr = open("testSet.txt")
for line in fr.readlines():
line_arr = line.strip().split()
data_list.append([1.0, float(line_arr[0]), float(line_arr[1])])
label_list.append(int(line_arr[2]))
return data_list, label_list
def SigmoidFuction(inx):
return 1.0/(1+exp(-inx))
def GradientAscent(data_list, label_list):
data_matrix = mat(data_list)#100*3
label_matrix = mat(label_list).transpose() #100*1
row, col = shape(data_matrix)
weights = ones((col, 1))
alpha = 0.01
max_cycles = 500
for i in xrange(max_cycles):
h = SigmoidFuction(data_matrix*weights)#100*1
error = label_matrix - h#100*1
weights = weights + alpha*data_matrix.transpose()*error
return weights
def PlotBestFit(weights):
import matplotlib.pyplot as plt
data_list, label_list = LoadDataSet()
data_array = array(data_list)
row = shape(data_array)[0]
xcord1 = []; ycord1 = []#1类样本的坐标
xcord2 = []; ycord2 = []#0类样本的坐标
for i in xrange(row):#存储样本的坐标
if int(label_list[i]) == 1:
xcord1.append(data_array[i, 1]); ycord1.append(data_array[i, 2])
else:
xcord2.append(data_array[i, 1]); ycord2.append(data_array[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s = 30, c = 'red', marker = 's')
ax.scatter(xcord2, ycord2, s = 30, c = 'green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2] #根据w0*x0+w1*x1+w2*x2 = 0,其中x0 = 1, x1 = x,则可算出x2,即y
ax.plot(x, y) #分类界线
plt.xlabel('x1'); plt.ylabel('x2')
plt.show()
def StocGradientAscent0(data_matrix, label_list):
row, col = shape(data_matrix)
#print row, col
alpha = 0.01
weights = ones(col)
for i in xrange(row):
h = SigmoidFuction(sum(data_matrix[i]*weights))
error = label_list[i] - h
weights = weights + alpha * error * data_matrix[i]
return weights
def StocGradientAscent1(data_matrix, label_list, num_iteration):
row, col = shape(data_matrix)
weights = ones(col)
for j in xrange(num_iteration):
data_index = range(row)
for i in xrange(row):
alpha = 4/(1.0+j+i) + 0.01
rand_index = int(random.uniform(0, len(data_index)))
h = SigmoidFuction(sum(data_matrix[rand_index]*weights))
error = label_list[rand_index] - h
weights = weights + alpha * error * data_matrix[rand_index]
del(data_index[rand_index])
return weights
data_list, label_list = LoadDataSet()
#weights = GradientAscent(data_list, label_list)
weights = StocGradientAscent1(array(data_list), label_list, 150)
print weights
PlotBestFit(weights)
'''
weights = StocGradientAscent1(array(data_list), label_list, 100)
PlotBestFit(weights)
'''














 1920
1920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









