






一、何谓引用计数
1.1 引用计数
引用计数是一种简单高效的垃圾回收机制,当一个新的引用指向对象的时候,增加引用计数;去掉一个引用,就减小一个引用计数;当引用计数减到0的时候,就释放掉这个引用计数。
1.2 引用计数的增减
对于一个引用计数的对象,最核心的操作就是引用计数的增减。但是,在一个并发场景下,必须保证引用计数增减的原子性。最简单的实现方法如下:
private static class AtomicIntSync implements Atomic {
private int i = 0;
public AtomicIntSync(int i) {
this.i = i;
}
@Override
public synchronized int incrementAndGet() {
return ++i;
}
}这种方法通过synchonized关键字,为自增操作加锁,而且java对这个关键字做了很多的优化,相对而言性能还是挺高的。
稍微复杂一点的方式是使用CAS(Compare and swap)的方式,CAS的语义是“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”,实现如下:
private static class AtomicIntCas implements Atomic {
private volatile int i = 0;
private static final Unsafe unsafe;
private static long off;
static {
Unsafe tmp = null;
try {
//获取unsafe
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
tmp = (Unsafe) field.get(null);
//获取i字段在类中的偏移
off = tmp.fieldOffset(AtomicIntCas.class.getDeclaredField("i"));
} catch (Throwable e) {
e.printStackTrace();
}
unsafe = tmp;
}
public AtomicIntCas(int i) {
this.i = i;
}
@Override
public int incrementAndGet() {
for (;;) {
int m = i;
int add = m + 1;
if (unsafe.compareAndSwapInt(this, off, m, add)) {
return add;
}
}
}
}
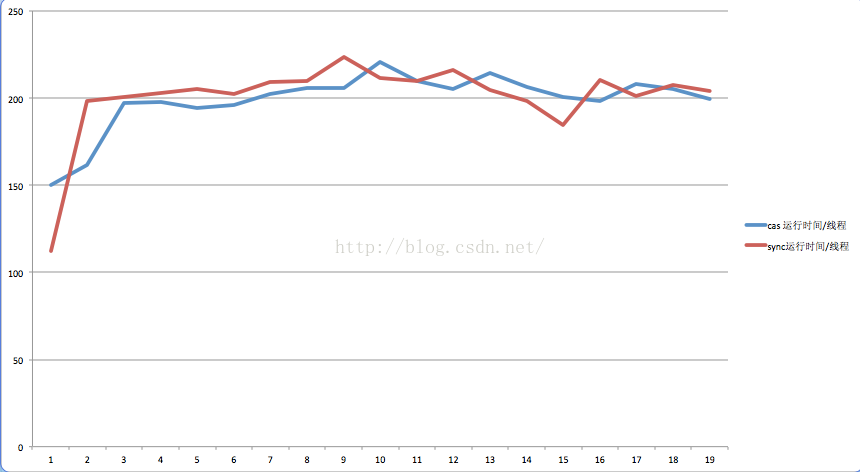
由上图可知,CAS方式整体性能是好于使用synchronized的这种锁的方式的。
二、引用计数的应用
引用计数的应用非常多,大名鼎鼎的Python语言其简单对象的垃圾回收机制就用的引用计数,netty的大量数据结构也使用的是引用计数。因为引用计数的垃圾回收实现简单,而且非常高效,特别是在分布式环境中,其性能真心杠杠的。
三、引用计数的局限
引用计数很难解决的场景是:A引用B,B同时引用A,当A和B都不使用了,A和B的引用都会是1,导致这种场景下的引用计数无法变成0,导致A和B都不能被释放。
四、netty的引用计数的实现
netty的引用计数的接口为io.netty.util.ReferenceCounted,netty很多重要的数据结构都是继承这个接口,比如ByteBuf,其核心实现参考:io.netty.util.AbstractReferenceCounted,其实现方式和上面的CAS的实现方法原理基本一致。
过程是:
1、通过Unsafe的方法,计算引用计数字段在AbstractReferenceCounted类中的偏移
2、通过Unsafe提供的CAS方法,将新的数据搬迁到引用计数字段所在的位置(AbstractReferenceCounted对象的地址+偏移)
3、如果CAS操作成功,就返回;否则计算新的引用计数,然后调用步骤2
五、netty的内存泄露检查
详见下一篇文章~
六、netty的引用计数的使用举例














 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









