







一、Scrapy 简介
Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。它的优势在于它是一个框架,任何人可以根据需求方便进行更改。
二、HTML 和 XPath
在学习爬虫之前,我们需要先对网站的结构有一些基本的了解。
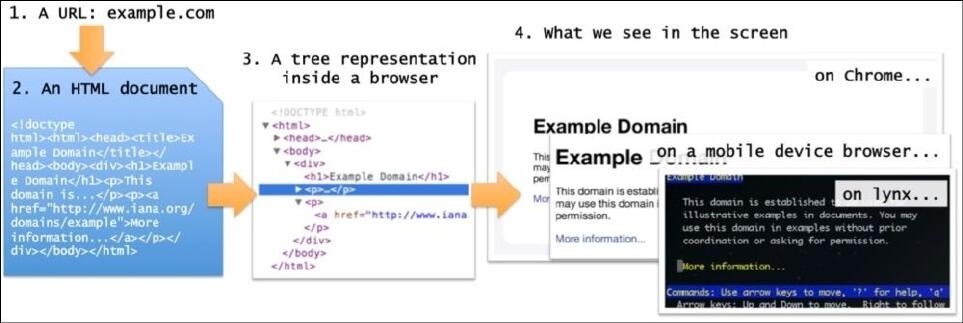
从输入网址(或点击一个链接)到网页在浏览器中呈现出来需要4个步骤:
1. 将URL输入给浏览器。URL的第一部分(域名,比如gumtree.com)是用来在web上找到对应的服务器。该URL以及一其他数据,(例如cookie)形成发送到该服务器的请求。
2. 服务器返回一个HTML页面给浏览器。要注意一些服务器也许会返回其它格式,比如XML,JSON...现在只考虑HTML。
3. HTML被浏览器转换成一个内部树表示,通常叫做:Document Object Model(DOM)。
4. 基于一些布局规则,内部表示最终被呈现为在屏幕上看到的视觉表示。















 5837
5837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









