







mongodb是一种文档型数据库,作为一个适用于敏捷开发的数据库,mongodb的数据模式可以随着应用程序的发展而灵活地更新。但是mongodb适合一次查询的需求,对于统计、分析(尤其是在需要跨表、跨库的情况下)并不是太方便,我们可以用spark来处理mongodb数据。架构图如下:
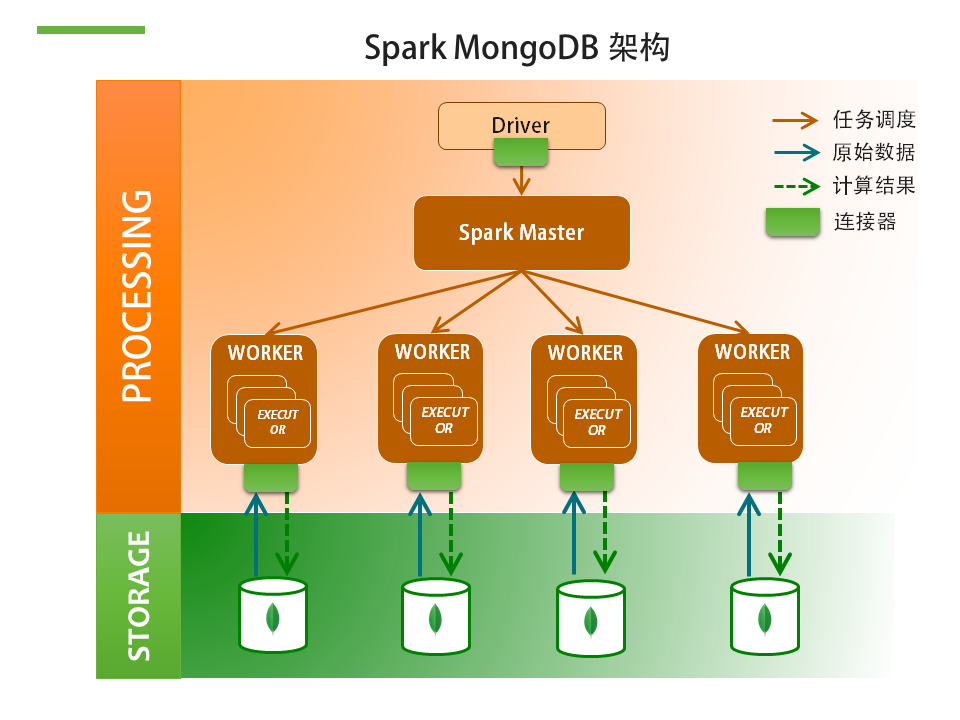
我使用的spark版本是spark-1.6.2,mongodb版本是3.2。我主要接触了以下两种连接器:
1、mongodb官方连接器
github地址:https://github.com/mongodb/mongo-spark
mongodb官方文档:https://docs.mongodb.com/spark-connector/
api文档(java版):https://www.javadoc.io/doc/org.mongodb.spark/mongo-spark-connector_2.11/2.0.0
加载mongodb数据的方式如下:
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.types import *
sc = SparkContext()
ctx = SQLContext(sc)
test_collection = ctx.read.format("com.mongodb.spark.sql").options(uri="mongodb://192.168.0.1:27017", database="test_db", collection="test_collection").load()test_collection.printSchema()
test_collection.first()上面的这种方式加载时间较长,因为spark需要判断各个字段的类型,需要抽取部分数据判断(或者扫描整个表,我没有具体的研究过,总之比较慢)。而且这种方式会将所有的数据加载进来,有些字段我并不需要获取到。可以用下面的代码改进:
fields_list = "name age sex grade exp"
fields = [StructField(field_name, StringType(), True) for field_name in fields_list.split()]
schema = StructType(fields)
test_collection = job_ctx.read.schema(schema).format("com.mongodb.spark.sql").optio 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









