







本文记录zookeeper+hadoop+hbase+kafka+storm集群的搭建过程。
准备工作
硬件环境
3台物理主机
192.168.0.191 – dc01
192.168.0.192 – dc02
192.168.0.193 – dc03
系统全部为centos6.8.软件环境
1) jdk1.8.0_121
2) zookeeper-3.4.10
3) hadoop-2.6.5
4) hbase-1.2.6
5) kafka_2.11-0.10.2.0
6) apache-storm-1.1.0jdk的安装在此不做赘述,有疑问可自行百度。
设置主机名
三台机器都需设置,后面所有操作都通过主机名连接。vim /etc/sysconfig/networkip为192.168.0.191的机器修改为如下内容:
NETWORKING=yes HOSTNAME=dc01其他两台机器分别设置为dc02和dc03。
修改host文件
vim /etc/hosts在末尾追加如下内容:
192.168.0.191 dc01 192.168.0.192 dc02 192.168.0.193 dc03三台机器做相同操作。
设置ssh免密码登录
以dc01为例,执行以下命令ssh-keygen -t rsa # 连续三次回车,即在本地生成了公钥和私钥,不设置密码 ssh-copy-id root@dc01 # 按提示输入dc01的密码 ssh-copy-id root@dc02 # 按提示输入dc02的密码 ssh-copy-id root@dc03 # 按提示输入dc03的密码如果端口不是默认的22则参照此处设置。
dc02和dc03重复dc01的操作,设置完成后任意两台机器之间不需要密码可直接登录,例如从dc01登录到dc03,只需在dc01输入”ssh dc03”即可。
开始安装
所有软件安装目录为/usr/local/
安装zookeeper
下载zookeeper安装文件zookeeper-3.4.10.tar.gz到/usr/local/下
执行以下命令:
#解压文件
tar -zxvf zookeeper-3.4.10.tar.gz
#修改文件夹名称
mv zookeeper-3.4.10 zookeeper
cd zookeeper/
#zookeeper配置文件名为zoo.cfg
cp conf/zoo_sample.cfg conf/zoo.cfg编辑zoo.cfg
vim conf/zoo.cfg修改后文件内容如下(主要添加最后三行):
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=dc01:2888:3888
server.2=dc02:2888:3888
server.3=dc03:2888:3888在zookeeper下新建data目录
mkdir data新增myid文件,该文件内容与zoo.cfg最后三行内容有关,server.x=host:port1:port2,myid中写入的就是x对应的值,不同主机文件内容不同。
echo '1' > data/myid使用scp命令将dc01上已配置好的zookeeper文件复制到其他两台机器
scp -r /usr/local/zookeeper root@dc02:/usr/local/zookeeper
scp -r /usr/local/zookeeper root@dc03:/usr/local/zookeeper操作完成后将dc02上的myid文件内容改为2,dc03中的myid内容改为3。
启动zookeeper
$zookeeper_home/bin/zkServer.sh start三个节点做同样操作,启动完成后可使用”zkServer.sh status”查看运行状态。
还有一个地方需要修改,默认情况下启动zookeeper后会在当前路径下生成一个zookeeper.out的日志文件,如果我们需要指定输出到固定路径,那么可以修改bin下的zkEnv.sh文件,找到ZOO_LOG_DIR并修改为指定路径即可。
安装hadoop
hbase基于hdfs存储,所以安装hbase前必须先安装hadoop,不同版本hbase对应的hadoop版本不同,安装前请确认兼容性。
下面开始安装:
在/usr/local/下新建hadoop目录,hadoop下再创建hdfs目录。
cd /usr/local/
mkdir -p hadoop/hdfs下载hadoop安装文件hadoop-2.6.5.tar.gz,放入hadoop目录下
tar -zxvf hadoop-2.6.5.tar.gz修改配置文件
cd hadoop-2.6.5/etc/hadoop/需要修改的配置文件有四个,hadoop-env.sh、core-site.xml、hdfs-site.xml、slaves,因为暂时不使用map-reduce所以不用配置yarn相关文件。
1、修改hadoop-env.sh
vim hadoop-env.sh修改JAVA_HOME为jdk安装路径(如果没有则添加一行)
export JAVA_HOME=/usr/local/java/jdk1.8.0_121
# 如果机器端口不是默认的22,还需要添加下面这一行指定端口号
# export HADOOP_SSH_OPTS="-p 1122"
# 1122为端口号,如果不添加执行./sbin/start-dfs.sh时会报如下错误:
# ssh: connect to host .. port 22: Connection refused2、修改 core-site.xml
vim core-site.xml修改后内容如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://dc01:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹,目录无需预先创建,会自动创建</description>
</property>
</configuration>
3、修改hdfs-site.xml
vim hdfs-site.xml修改后内容如下:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据,目录无需预先创建,会自动创建 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置,目录无需预先创建,会自动创建</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
4、修改slaves
vim slaves将原来的localhost改成如下内容:
dc02
dc03修改完成后将安装目录copy到其他两台机器上:
scp -r /usr/local/hadoop root@dc02:/usr/local/hadoop
scp -r /usr/local/hadoop root@dc03:/usr/local/hadoop启动集群(只需在dc01操作)
第一次启动时需要先格式化,以后无需进行此操作。
cd /usr/local/hadoop/hadoop-2.6.5
#格式化
./bin/hdfs namenode -format
#启动集群
./sbin/start-dfs.sh启动成功后可使用jps命令查看,dc01有NameNode和SecondaryNameNode进程,dc02和dc03有DataNode进程则集群启动成功。
安装hbase
集群机器划分:dc01作为NameNode节点,dc02和dc03作为DataNode节点。
下载hbase安装文件并放入/usr/local/目录下
1、解压并修改文件夹名称:
tar -zxvf hbase-1.2.6-bin.tar.gz
mv hbase-1.2.6 hbase2、修改配置文件,配置hbase集群需要修改三个配置文件,分别为hbase-env.sh、hbase-site.xml、regionservers。
cd hbase/conf/1)修改hbase-env.sh
vim hbase-env.sh需要修改两行内容
修改JAVA_HOME的值为jdk的安装目录,修改后如下:
export JAVA_HOME=/usr/local/java/jdk1.8.0_121修改HBASE_MANAGES_ZK,该行默认被注释掉了,默认使用hbase自带的zookeeper协调集群,我们需要把注释去掉并修改值为false,表示使用自己安装的zookeeper。修改如下:
export HBASE_MANAGES_ZK=false2)修改hbase-site.xml
vim hbase-site.xml在 中添加如下内容:
<property>
<name>hbase.rootdir</name>
<!-- 数据存储位置,需要和hadoop配置文件core-site.xml中的fs.default.name值一致 -->
<value>hdfs://dc01:9000/hbase</value>
</property>
<property>
<!-- 设置是否分布式环境,false表示单机,默认为false -->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<!-- 此处配置主机名 -->
<value>dc01,dc02,dc03</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hbase/data/zookeeper</value>
</property>3)修改regionservers
vim regionservers该文件配置数据存储在哪个节点,即DataNode节点的位置。默认为localhost,表示数据存储在本机,需要修改为两个DataNode节点的主机名,修改后内容如下:
dc02
dc03上述操作完成后使用scp命令将hbase所有文件复制到dc02和dc03。
scp -r /usr/local/hbase root@dc02:/usr/local/hbase
scp -r /usr/local/hbase root@dc03:/usr/local/hbase3、启动hbase
#启动
./bin/start-hbase.sh启动完成后可通过jps命令查看,dc01有HMaster进程,dc02和dc03有HRegionServer进程则表示集群启动成功。如果任一节点没有对应的进程则表示集群启动失败,可查看日志查找失败原因。此处需要注意一点,三台机器的系统时间相差不能太大,否则会出现启动失败的情况,同步系统时间后重试即可。
4、连接hbase
hbase提供了shell操作接口,使用一些命令连接hbase
./bin/hbase shell连接后可通过相应的shell命令操作hbase,hbase的操作此处不做讨论,请自行google。
hbase还可以通过第三方插件apache-phoenix进行连接,该插件支持以sql的方式操作hbase。下载和hbase版本对应的phoenix安装包,解压后将phoenix-[phoenix版本]-HBase-[hbase版本]-server.jar(本例中使用的为phoenix-4.10.0-HBase-1.2-server.jar)复制到hbase的lib目录下重启hbase即可(每个节点都需要进行此操作),phoenix操作方法请自行搜索资料学习。
安装kafka
下载kafka安装文件并放入/usr/local/目录下,解压
tar -zxvf kafka_2.11-0.10.2.0.tgz
mv kafka_2.11-0.10.2.0 kafkakafka的配置比较简单,只需修改config/下的server.properties文件即可,需要修改三处位置。
vim ./config/server.properties1)修改broker.id
该值在各个节点中不能重复,推荐使用机器ip地址最后一位,如dc01上该值为1,dc02上为2,dc03上为3。
2)修改log.dirs
该值表示日志文件存储位置,默认为/tmp/kafka-logs,使用该配置时机器重启后文件会被清空,需要修改为其他位置,建议修改为:
log.dirs=/usr/local/kafka/kafka-logs3)修改zookeeper.connect
这一项比较重要,表示kafka数据在zookeeper中的存储位置,以后连接kafka时会使用该值。本例中修改为:
zookeeper.connect=dc01:2181,dc02:2181,dc03:2181/kafka4)配置topic是否可删除,默认该项是被注释的,如需要支持topic删除请放开该注释
delete.topic.enable=true5)配置是否自动创建topic,默认情况下Producer往一个不存在的Topic发送message时会自动创建这个Topic
auto.create.topics.enable=false注:修改完成后将整个kafka目录复制到dc02和dc03中即完成集群配置(不要忘记修改broker.id,不同机器不能重复)。
启动kafka
nohup ./bin/kafka-server-start.sh ./config/server.properties &停止kafka
./bin/kafka-server-stop.sh &注:kafka的启动和停止需要分别在每个节点操作。
安装storm
下载storm安装文件放入/usr/local/目录,解压
tar -zxvf apache-storm-1.1.0.tar.gz
mv apache-storm-1.1.0 stormstorm配置比较简单,只需修改storm.yaml
cd storm/conf/
vim storm.yaml添加以下内容:
# 注意:严格遵守ymal格式,相同层级关系必须左对齐
storm.zookeeper.servers:
- "dc01"
- "dc02"
- "dc03"
nimbus.seeds: ["dc01"]
drpc.servers:
- "dc01"
storm.local.dir: "/usr/local/storm/local-dir"
上述配置storm.zookeeper.servers表示zookeeper节点,nimbus.seeds表示nimbus服务在dc01节点,drpc.servers表示drpc服务在dc01节点,storm.local.dir表示日志文件位置。
配置完成后将storm安装目录复制到dc02和dc03上。
scp -r /usr/local/storm/ root@dc02:/usr/local/storm/
scp -r /usr/local/storm/ root@dc03:/usr/local/storm/启动storm集群
在dc01上执行以下命令
cd /usr/local/storm
./bin/storm nimbus > /dev/null 2>&1 &
./bin/storm ui > /dev/null 2>&1 &
./bin/storm drpc > /dev/null 2>&1 &在dc02和dc03上执行以下命令:
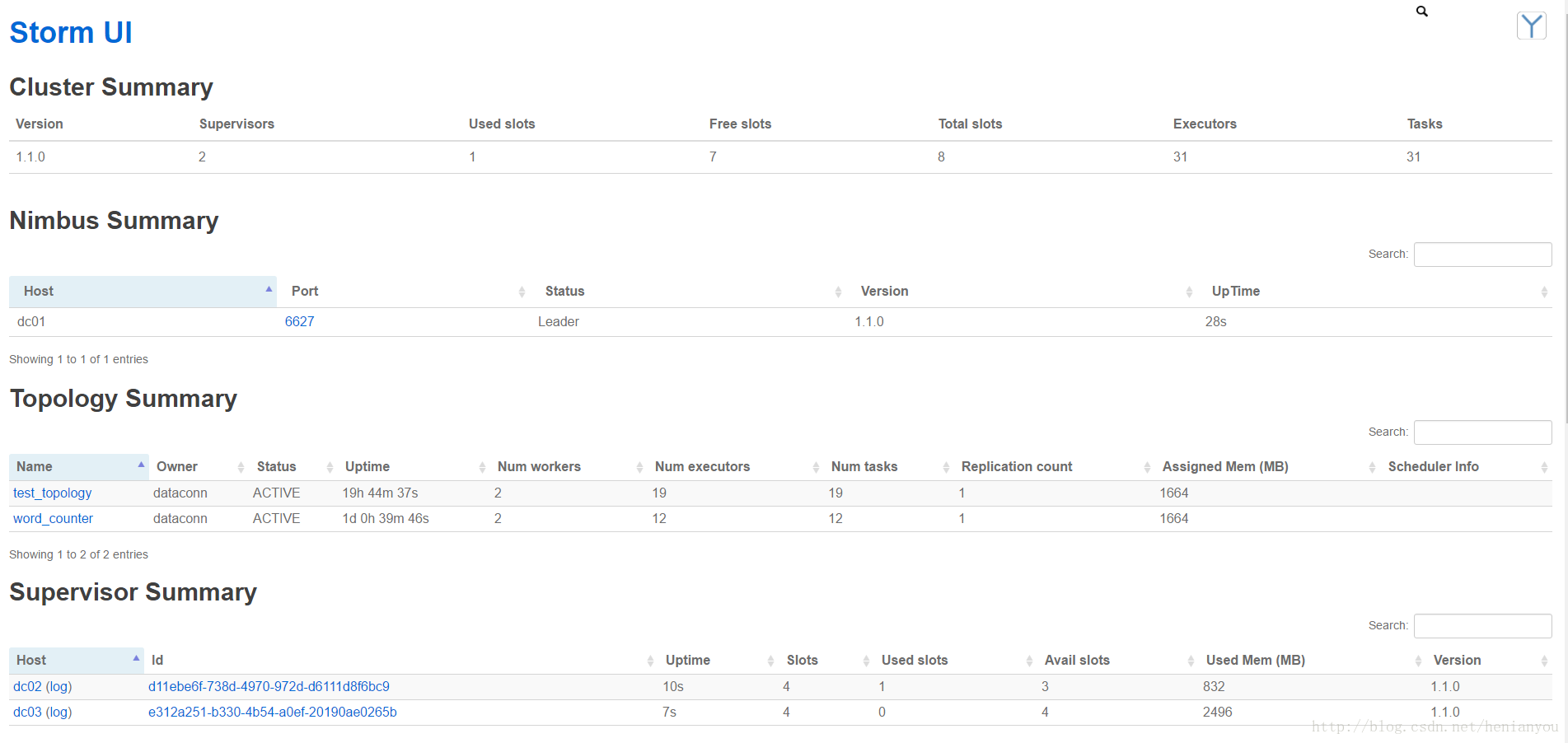
./bin/storm supervisor > /dev/null 2>&1 &等待启动完成后可通过浏览器访问http://dc01:8080查看集群运行状态。
启动成功界面:
总结
由于hbase需要基于zookeeper和hadoop运行,kafka和storm需要基于zookeeper运行。所以启动顺序应该为zookeeper->hadoop->hbase->kafka->storm,停止顺序相反。
本文内容比较粗略,有错误或遗漏的地方欢迎各位指正。














 1388
1388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









