









Adaboost 算法wiki简介
AdaBoost,是英文"AdaptiveBoosting"(自适应增强)的缩写,是一种机器学习方法,由YoavFreund和RobertSchapire提出。[1]AdaBoost方法的自适应在于:前一个分类器分错的样本会被用来训练下一个分类器。AdaBoost方法对于噪声数据和异常数据很敏感。但在一些问题中,AdaBoost方法相对于大多数其它学习算法而言,不会很容易出现过拟合现象。AdaBoost方法中使用的分类器可能很弱(比如出现很大错误率),但只要它的分类效果比随机好一点(比如两类问题分类错误率略小于0.5),就能够改善最终得到的模型。而错误率高于随机分类器的弱分类器也是有用的,因为在最终得到的多个分类器的线性组合中,可以给它们赋予负系数,同样也能提升分类效果。
AdaBoost方法是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。每一个训练样本都被赋予一个权重,表明它被某个分类器重视的概率。如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它被重视的程度会比较轻(因为前面的分类器可以比较好的描述它了);相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。通过这样的方式,AdaBoost方法能“聚焦于”那些较难分的样本上。在具体实现上,最初令每个样本的权重都相等,对于第k次迭代操作,我们就根据这些权重来处理样本点,进而训练分类器Ck。然后就根据这个分类器,来提高被它分错的的样本的权重,并降低被正确分类的样本权重。然后,权重更新过的样本集被用于训练下一个分类器Ck[2]。整个训练过程如此迭代地进行下去。
Adaboost算法基本思想与流程
1. 为数据集里的每个样本赋予相同的权重(一般情况),然后开始依据一定的分类标准来对该数据集分类,从而得到第一个Classifier[1](弱分类器)。同时由此可得此次分类中被分错的样本,提高他们的权重,用于下一个Classifier[2]的训练。
2. 依据上一次Classifier训练更新样本权重后的样本集,来训练此次Classifier[2]。其中可以依据样本权重来影响此次训练的错误率来使此次Classifier[2]足够重视之前错分的样本。这样我们可以得到对于上次分错的样本有较好分类能力的Classifier[2],然后提高本次分类中被分错的样本的权重。重复此过程,得到若干的弱分类器Classifier[i]。
3. 为1、2步中得到的Classifier[i]确定在最终的强分类器中的权重(此权重的确定也可以在1、2步中确定)。Strong_Classifier = ∑( weight[i] *Classifier[i])(弱分类器的线性组合),计算Strong_Classifier的错误率,然后综合考虑程序迭代次数来判断是否继续重复1-3步迭代训练。
上述描述表示如下(摘自wiki):

注意:
1. 样本的权重可以影响该Classifier的错误率。提高错误点的权值,当此次分类器再次分错了这些点之后,会提高该分类器整体的错误率。
2.该Classifier的错误率将影响其在最终的Strong_Classifier中的权重,从而使好的弱分类器在最终强分类器中所占比重大。
3.Adaboost自我提升的能力来源于分类器对之前分类器分类错误的样本的重视。
4.其中弱分类器的弱只是相对于最终的强分类器而言,所以弱分类器可能性能仅比随机分类高一点,但是也可能弱分类器本身的分类能力已经足够强。
5.从这里看出,Adaboost比较合适应用于分类问题。
Adaboost算法解决数字简单分类实例分析

代码简介
Adaboost.cpp完整代码地址:
https://github.com/YIWANFENG/Algorithm-github
//定义训练样本结构体
struct Sample
{
intnumber; //标号
intfeature; //特征
intlabel; //类别
floatweight; //权重
};
//弱分类器基本信息,此即为弱分类器
struct BoostNode
{
intindex; //弱分类器的数目
floatthreshold; //每个弱分类器对应的阈值
intp; //每个弱分类器对应的不等号方向
floatalpha; //每个弱分类器的权重alpha
BoostNode*next; //下一个节点
};
BoostNode *adaboost(Sample *sam,int n)
{
intind = 0;
//floatmin_error = 1.0;
intnum_misclassification = n; //统计分错样本数
//头指针是一个标志指针,未存入实际的值
BoostNode*head = (BoostNode *) malloc (sizeof(BoostNode));
BoostNode*tp = head;
BoostNode*tmp;
//候选阈值存放位置
float*threshold = (float *) malloc ((n + 1) * sizeof(float));
//找所有的阈值
generate_threshold(threshold,sam, n);
//每个分类器阈值对应的错误率
float*error = (float *) malloc ((n + 1) * sizeof(float));
intnum_min_error_classifier;
doublealp;
int*p = (int *) malloc ((n + 1) * sizeof(int));
float*est = (float *) malloc (n * sizeof(float)); //评估正确率;
for(int i = 0; i < n; i++)
{
est[i]= 0.0;
}
while(ind < 10 && num_misclassification > 0)
{
ind++;
for(int i = 0; i < n + 1; i++)
{
p[i]= 1;
}
//计算所有阈值对应的分类器的错误率
compute_error(sam,threshold, p, error, n);
//错误率最小对应的阈值标号
num_min_error_classifier= find_Min_Error(error, n);
//计算此次分类器在强分类器中的权重
alp= comp_Alpha(error[num_min_error_classifier]);
tmp= (BoostNode *) malloc (sizeof(BoostNode));
tmp->alpha= alp;
tmp->threshold= threshold[num_min_error_classifier];
tmp->index= ind;
tmp->p= p[num_min_error_classifier];
tp->next= tmp;
tp= tp->next;
update(sam,num_min_error_classifier, threshold, error, est, p, alp, n);
//使用sign(符号函数)判断强分类分错的样本数目
num_misclassification= judge_Classify(sam, est, n);
// cout << "更新后的样本权重为:" << endl;
// for (int i = 0; i < n; i++)
// {
// cout << sam[i].weight << "";
// }
// cout << endl;
}
tp->next= NULL;
returnhead;
}图示说明

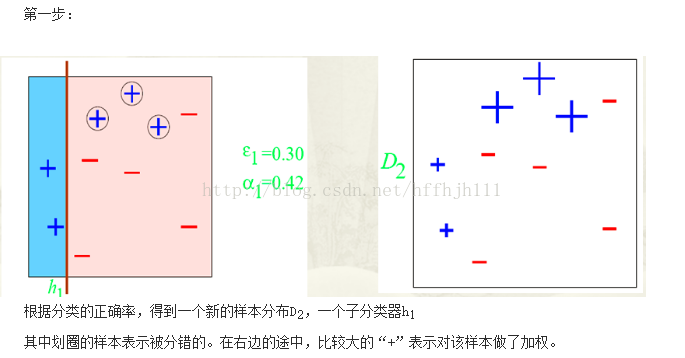
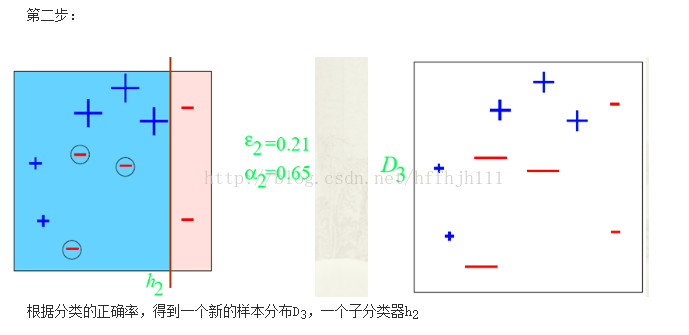
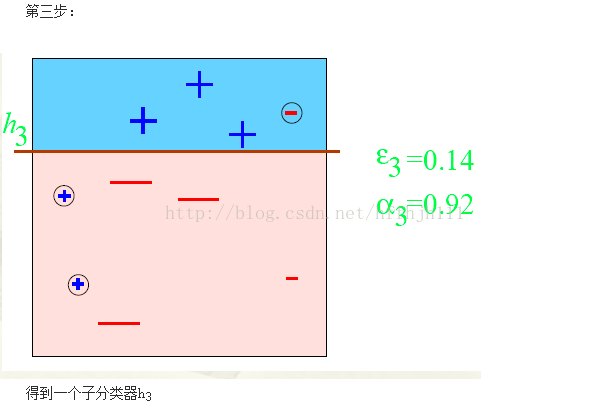

关于Adaboost算法数学分析推荐
错误率下降与很少过拟合特点的数学分析参考:
http://baidutech.blog.51cto.com/4114344/743809/
最终强分类器的误差分析:
http://www.360doc.com/content/14/1109/12/20290918_423780183.shtml
数字简单分类示例详细解析参考:
http://blog.csdn.net/tiandijun/article/details/48036025














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









