







HDFS是存取数据的分布式文件系统,那么对HDFS的操作,就是对文件系统的基本操作,即文件及文件夹的增删改查、权限修改,HDFS提供了一套自己的shell命令来进行操作,类似于我们linux系统中的shell命令。
我们在执行HDFS 的shell命令时,要确认hadoop是正常运行的,可以通过命令jps来查看进程,查看hadoop当前是否是正常运行。
执行如下命令,我们来查看一下HDFS 的shell 支持的所有命令
$ hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]在浏览器中访问hadoop(http://node1:50070),选择Browse the file system,查看hadoop的文件系统
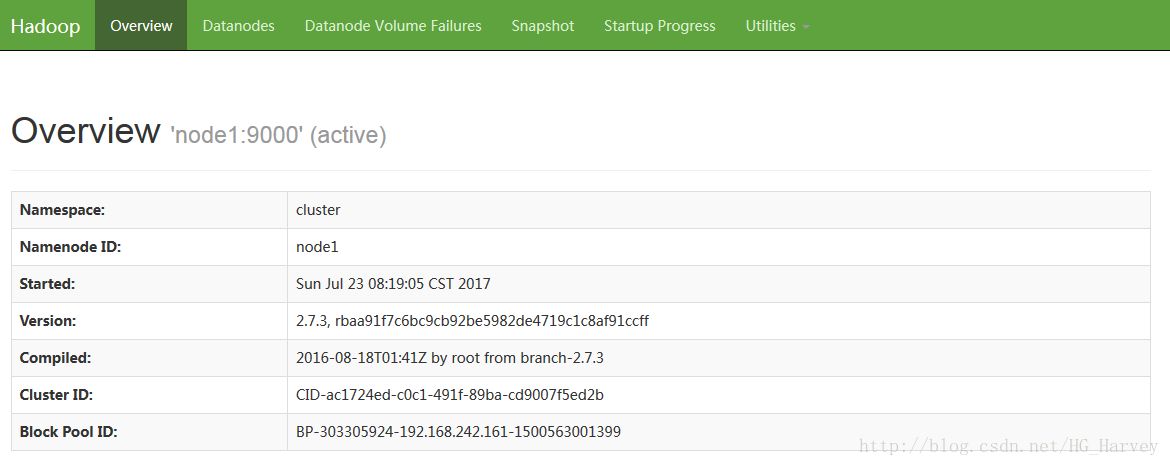
上图中可以看到目前hdfs中目前是没有任务文件的,之后我们操作的文件它都是存放在了datanode节点上,对应的目录如下(红色部分为hadoop的安装目录)
/usr/local/hadoop/tmp/dfs/data/current/BP-303305924-192.168.242.161-1500563001399/current/finalized
Shell 常用命令
1-ls:显示当前目录结构
如果命令选项后没有路径,那么会访问/usr/<用户>目录,创建该目录后就不会再提示没有文件或目录
[hadoop@node1 ~]$ hadoop fs -ls
ls: `.': No such file or directory
查看hdfs文件系统根目录下的目录和文件
[hadoop@node1 ~]$ hadoop fs -ls /查看hdfs文件系统所有的目录和文件
[hadoop@node1 ~]$ hadoop fs -ls -R /2 -put:上传文件
[hadoop@node1 ~]$ echo hello hadoop ha cluster > hello.txt # 在linux上创建一个hello.txt文件
[hadoop@node1 ~]$ ll
总用量 4
-rw-rw-r-- 1 hadoop hadoop 24 7月 22 18:50 hello.txt
[hadoop@node1 ~]$ hadoop fs -put hello.txt / # 将本地文件hello.txt上传到hdfs的根目录下
[hadoop@node1 ~]$ hadoop fs -ls / # 查看hdfs根目录下所有文件
Found 1 items
-rw-r--r-- 3 hadoop supergroup 24 2017-07-22 18:51 /hello.txt在浏览器图形界面中查看
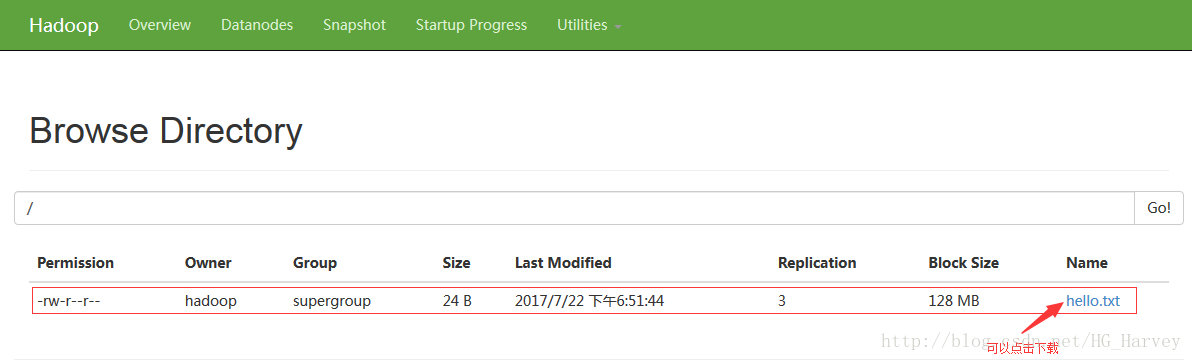
3-cat:查看文件内容
[hadoop@node1 ~]$ hadoop fs -cat /hello.txt # 查看hello.txt文件内容
hello hadoop ha clusterhdfs文件存放在datanode节点上,我们来看下(文件块的数据备份个数,默认是3,在hdfs-site.xml中配置dfs.replication来修改副本数量)
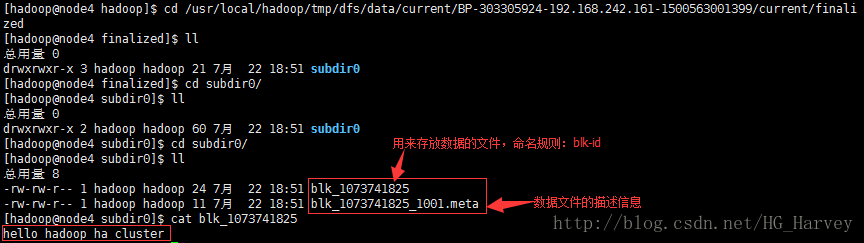
上图中可以看到文件的所有内容,但文件并没有被切块,即分块存储,原因是因为hadoop2.x版本中文件超过128M后,才会分块存储,下面我们来上传一个大文件。上传jdk安装包到hdfs根目录下
[hadoop@node1 ~]$ ll
总用量 166000
-rw-r--r-- 1 hadoop hadoop 169983496 5月 7 17:07 jdk-8u131-linux-x64.rpm
[hadoop@node1 ~]$ hadoop fs -put jdk-8u131-linux-x64.rpm /查看上传完成后的文件
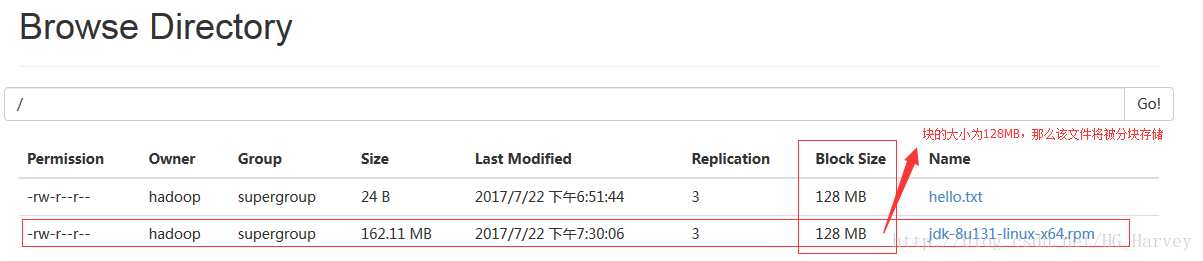
然后我们再去datanode节点中查看该文件是否已被分块存储(被分成两个块存储)

我们上传后的文件超过了128M,hdfs会帮我们分块存储,即将0-128M之间的文件内容存放到一个文件中,128M-162M的内容存放到另一个文件中。
4-get:下载文件
我们刚刚把本地的jdk安装包上传到了hdfs,现在把本地的删除,从hdfs上下载到本地
从hdfs下载jdk文件时,hdfs并没有返回给我两个块文件,而是返回了一个jdk的安装包文件,其实我们在下载的过程中hdfs是先从第一个文件传输,第一个文件传输完成后,再传输第二个文件。最终我们获得了一个完整的jdk安装包文件。
[hadoop@node1 ~]$ hadoop fs -get /jdk-8u131-linux-x64.rpm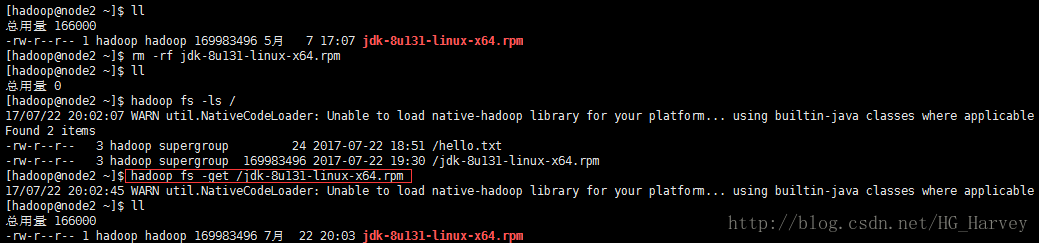
5-mkdir:创建文件夹
如果是多级目录需要加 -p 参数
在hdfs中创建文件夹 /workcount/input
[hadoop@node1 ~]$ hadoop fs -mkdir -p /workcount/input6-moveFromLocal:从本地剪切粘贴到 hdfs
将本地demo.txt文件剪切粘贴到 hdfs 根目录下
$ hadoop fs -moveFromLocal demo.txt /
7-appendToFile:将一个文件中的内容追加到hdfs中的文件
将文件context.txt中的内容追加到hdfs中的demo.txt文件中
$ hadoop fs -appendToFile context.txt /demo.txt
8-chmod:修改权限
将demo.txt文件的拥有者、所属组及其它用户添加可执行权限
$ hadoop fs -chmod ugo+x /demo.txt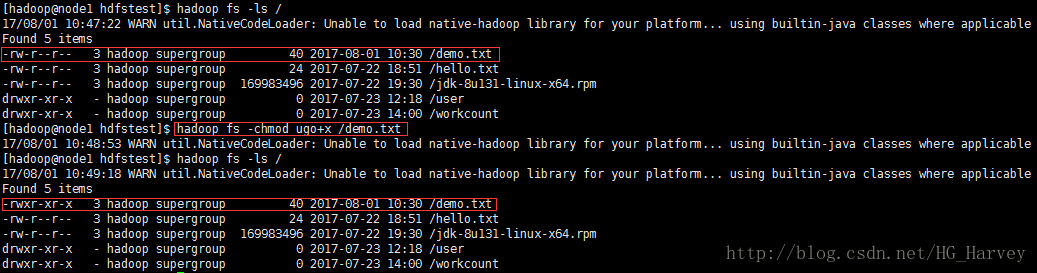
9-chown:修改拥有者及所属组
修改hello.txt 文件的拥有者及所属者均为root
$ hadoop fs -chown root:root /hello.txt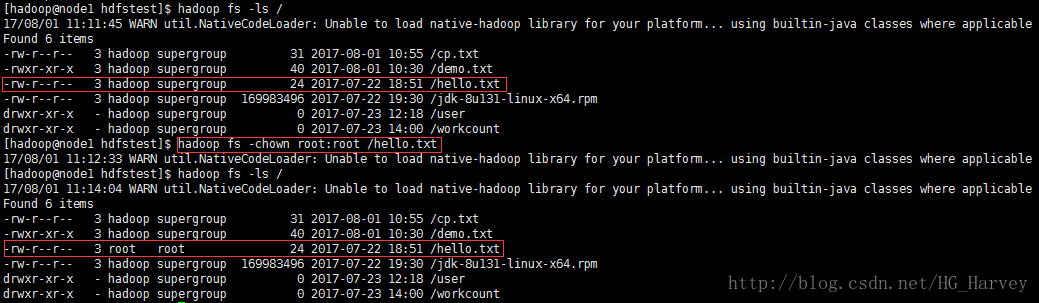
10-copyFromLocal:从本地文件系统中拷贝文件到hdfs中(等同于-put)
拷贝文件cp.txt到hdfs的根目录下
$ hadoop fs -copyFromLocal cp.txt /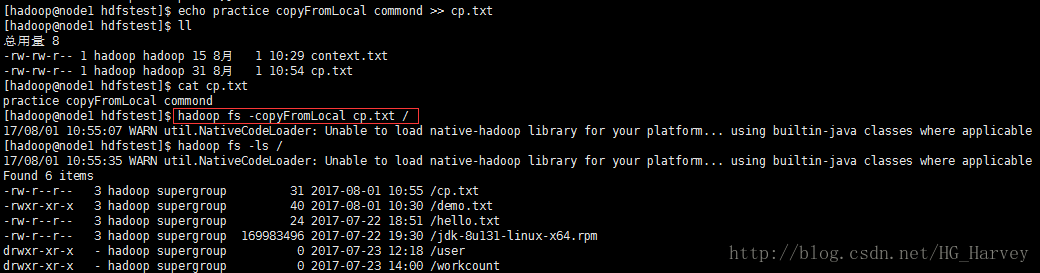
11 -copyToLoal:从hdfs文件系统拷贝到本地(等同于-get)
从hdfs将hello.txt文件拷贝到本地
$ hadoop fs -copyToLocal /hello.txt /home/hadoop/hdfstest/
12 -cp:在hdfs文件系统中进行文件的拷贝
将cp.txt 文件拷贝到workcount/input目录下并重命名为b.txt
$ hadoop fs -cp /cp.txt /workcount/input/c.txt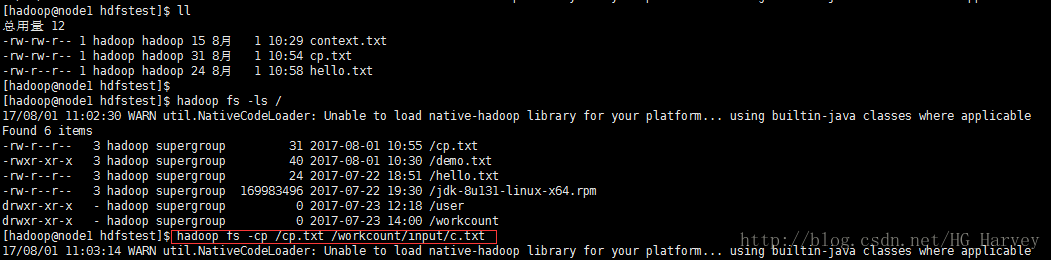
13 -mv:在hdfs文件系统在进行文件的移动
将work/input目录下的c.txt文件移动到/user/hadoop目录下
$ hadoop fs -mv /workcount/input/c.txt .
14 -getmerge:从hdfs合并下载多个文件
将hdfs中的/workcount/input下的所有文件合并下载到本地的名为merg.txt文件中
hadoop fs -getmerge /workcount/input/*.* /home/hadoop/hdfstest/merg.txt
15 -rm:删除文件或文件夹(递归删除加-r参数)
$ hadoop fs -rm /demo.txt # 删除demo.txt文件
$ hadoop fs -rm -r /workcount/output # 递归删除16 -df:统计文件系统的可用空间信息
$ hadoop fs -df -h /
17 -du:统计文件夹的大小信息
$ hadoop fs -du -s -h hdfs://node1:9000/*
18 -setrep:设置hdfs中文件的副本数量
$ hadoop fs -setrep 10 /cp.txt # 设置cp.txt的副本数量为10设置前:

设置后:

注意:这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量














 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









