









文章摘要:
支持向量机具体理论在前面已经进行了一定的总结,此处主要是根据理论的一个一个结果进行编码。运用SMO算法进行实现。
SVM的理论框架
SVM的学习问题可以转化为下面的对偶问题:
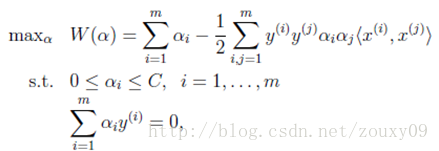
需要满足的KKT条件:
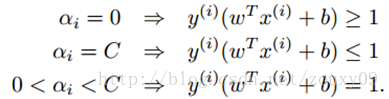
也就是说找到一组αi可以满足上面的这些条件的就是该目标的一个最优解。所以我们的优化目标是找到一组最优的αi*。一旦求出这些αi*,就很容易计算出权重向量w*和b,并得到分隔超平面了。
而预测则是:训练好了SVM。那来一个新的样本x后,就可以这样分类了:
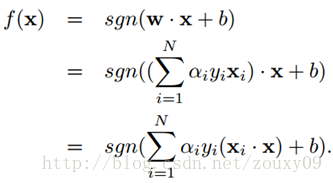
SMO高效优化算法
SMO坐标上升
假设要求解下面的优化问题:
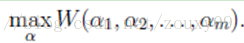
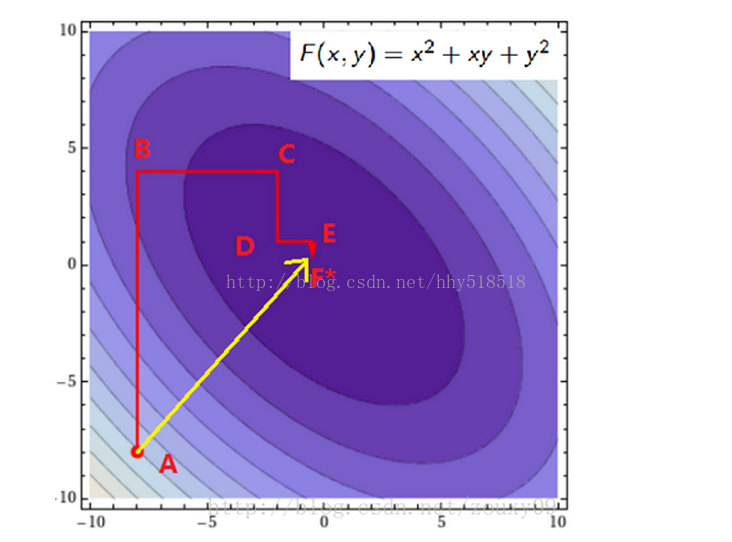
在这里,我们需要求解m个变量αi,一般来说是通过梯度下降(这里是求最大值,所以应该叫上升)等算法每一次迭代对所有m个变量αi也就是α向量进行一次性优化。通过误差每次迭代调整α向量中每个元素的值。而坐标上升法(坐标上升与坐标下降可以看做是一对,坐标上升是用来求解max最优化问题,坐标下降用于求min最优化问题)的思想是每次迭代只调整一个变量αi的值,其他变量的值在这次迭代中固定不变。

最里面语句的意思是固定除αi之外的所有αj(i不等于j),这时W可看作只是关于αi的函数,那么直接对αi求导优化即可。这里我们进行最大化求导的顺序i是从1到m,可以通过更改优化顺序来使W能够更快地增加并收敛。如果W在内循环中能够很快地达到最优,那么坐标上升法会是一个很高效的求极值方法。
我们回到这个优化问题。我们可以看到这个优化问题存在着一个约束,也就是
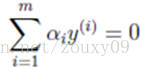
假设我们首先固定除α1以外的所有参数,然后在α1上求极值。但需要注意的是,因为如果固定α1以外的所有参数,由上面这个约束条件可以知道,α1将不再是变量(可以由其他值推出),因为问题中规定了:
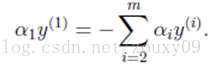
因此,我们需要一次选取两个参数做优化,比如αi和αj,此时αi可以由αj和其他参数表示出来。
这样回代入W中,W就只是关于α j 的函数了,这时候就可以只对α j 进行优化了。在这里就是对α j 进行求导,令导数为0就可以解出这个时候最优的α j 了。然后也可以得到α i 。这就是一次的迭代过程,一次迭代只调整两个拉格朗日乘子α i 和α j 。SMO之所以高效就是因为在固定其他参数后,对一个参数优化过程很高效(对一个参数的优化可以通过解析求解,而不是迭代。虽然对一个参数的一次最小优化不可能保证其结果就是所优化的拉格朗日乘子的最终结果,但会使目标函数向极小值迈进一步,这样对所有的乘子做最小优化,直到所有满足KKT条件时,目标函数达到最小)。总结下来是:
重复下面过程直到收敛{
(1)选择两个拉格朗日乘子αi和αj;
(2)固定其他拉格朗日乘子αk(k不等于i和j),只对αi和αj优化w(α);
(3)根据优化后的αi和αj,更新截距b的值;
}
那训练里面这两三步骤到底是怎么实现的,需要考虑什么呢?下面我们来具体分析下:
(1)选择αi和αj:该检验是在ε范围内进行的。在检验过程中,外层循环首先遍历所有满足条件0<αj<C的样本点,即在间隔边界上的支持向量点,检验他们是否满足KKT条件,然后选择违反KKT条件最严重的αi。如果这些样本点都满足KKT条件,那么遍历整个训练集,检验他们是否满足KKT条件,然后选择违反KKT条件最严重的αi。
优先选择遍历非边界数据样本,因为非边界数据样本更有可能需要调整,边界数据样本常常不能得到进一步调整而留在边界上。由于大部分数据样本都很明显不可能是支持向量,因此对应的α乘子一旦取得零值就无需再调整。遍历非边界数据样本并选出他们当中违反KKT 条件为止。当某一次遍历发现没有非边界数据样本得到调整时,遍历所有数据样本,以检验是否整个集合都满足KKT条件。如果整个集合的检验中又有数据样本被进一步进化,则有必要再遍历非边界数据样本。这样,不停地在遍历所有数据样本和遍历非边界数据样本之间切换,直到整个样本集合都满足KKT条件为止。以上用KKT条件对数据样本所做的检验都以达到一定精度ε就可以停止为条件。如果要求十分精确的输出算法,则往往不能很快收敛。
对整个数据集的遍历扫描相当容易,而实现对非边界αi的扫描时,首先需要将所有非边界样本的αi值(也就是满足0<αi<C)保存到新的一个列表中,然后再对其进行遍历。同时,该步骤跳过那些已知的不会改变的αi值
2)第二个变量αj的选择:
在选择第一个αi后,算法会通过一个内循环来选择第二个αj值。因为第二个乘子的迭代步长大致正比于|Ei-Ej|,所以我们需要选择能够最大化|Ei-Ej|的第二个乘子(选择最大化迭代步长的第二个乘子)。在这里,为了节省计算时间,我们建立一个全局的缓存用于保存所有样本的误差值,而不用每次选择的时候就重新计算。我们从中选择使得步长最大或者|Ei-Ej|最大的αj。
优化αi和αj:

选择这两个拉格朗日乘子后,我们需要先计算这些参数的约束值。然后再求解这个约束最大化问题。
首先,我们需要给αj找到边界L<=αj<=H,以保证αj满足0<=αj<=C的约束。这意味着αj必须落入这个盒子中。由于只有两个变量(αi, αj),约束可以用二维空间中的图形来表示,如下图:
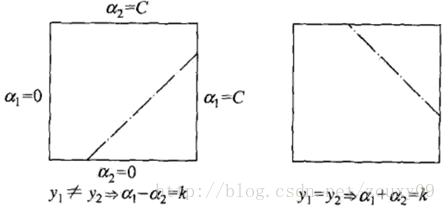
不等式约束使得(αi,αj)在盒子[0, C]x[0, C]内,等式约束使得(αi, αj)在平行于盒子[0, C]x[0, C]的对角线的直线上。因此要求的是目标函数在一条平行于对角线的线段上的最优值。这使得两个变量的最优化问题成为实质的单变量的最优化问题。由图可以得到,αj的上下界可以通过下面的方法得到:
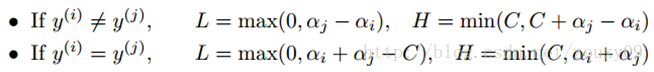
我们优化的时候,αj必须要满足上面这个约束。也就是说上面是αj的可行域。然后我们开始寻找αj,使得目标函数最大化。通过推导得到αj的更新公式如下:
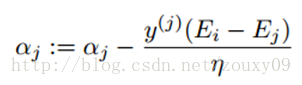
这里Ek可以看做对第k个样本,SVM的输出与期待输出,也就是样本标签的误差。
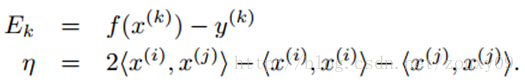
而η实际上是度量两个样本i和j的相似性的。在计算η的时候,我们需要使用核函数,那么就可以用核函数来取代上面的内积。这个更新公式推导如下:
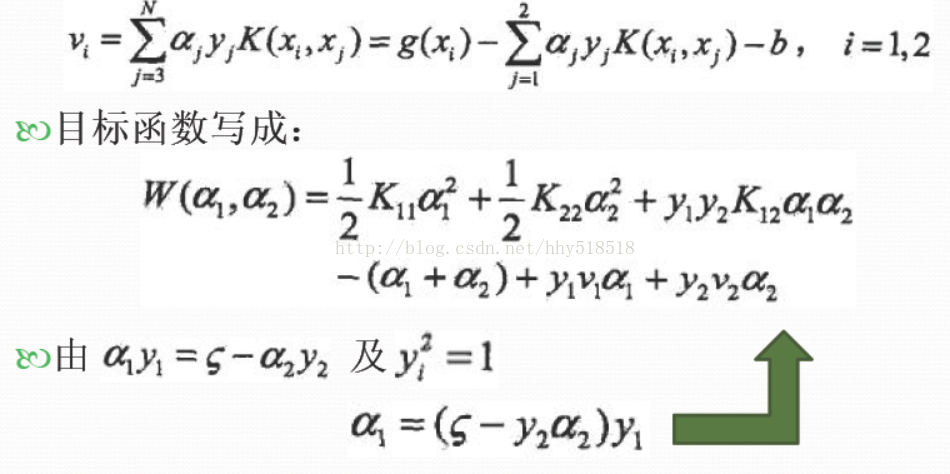

得到新的αj后,我们需要保证它处于边界内。换句话说,如果这个优化后的值跑出了边界L和H,我们就需要简单的裁剪,将αj收回这个范围:
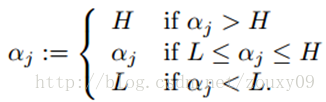
最后,得到优化的αj后,我们需要用它来计算αi:
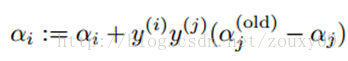
到这里,αi和αj的优化就完成了。
(3)计算阈值b:
优化αi和αj后,我们就可以更新阈值b,使得对两个样本i和j都满足KKT条件。如果优化后αi不在边界上(也就是满足0<αi<C,这时候根据KKT条件,可以得到yigi(xi)=1,这样我们才可以计算b),那下面的阈值b1是有效的,因为当输入xi时它迫使SVM输出yi。
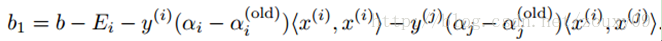
同样,如果0<αj<C,那么下面的b2也是有效的:
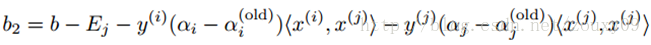
如果0<αi<C和0<αj<C都满足,那么b1和b2都有效,而且他们是相等的。如果他们两个都处于边界上(也就是αi=0或者αi=C,同时αj=0或者αj=C),那么在b1和b2之间的阈值都满足KKT条件,一般我们取他们的平均值b=(b1+b2)/2。所以,总的来说对b的更新如下:
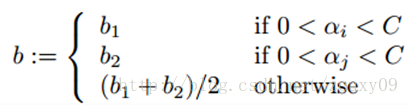
每做完一次最小优化,必须更新每个数据样本的误差,以便用修正过的分类面对其他数据样本再做检验,在选择第二个配对优化数据样本时用来估计步长。、
SMO算法的基本思路是:如果说有变量的解都满足此最优化问题的KKT条件,那么这个最优化问题的解就得到了。因为KKT条件是该最优化问题的充分必要条件(证明请参考文献)。所以我们可以监视原问题的KKT条件,所以所有的样本都满足KKT条件,那么就表示迭代结束了。但是由于KKT条件本身是比较苛刻的,所以也需要设定一个容忍值,即所有样本在容忍值范围内满足KKT条件则认为训练可以结束
工作原理:每次循环轩两个alpha进行优化,一旦找到一对合适的alpha然后增大其中一个减小另外一个。
简化版本的:首先数据集上遍历每一个alpha然后剩下的一个在集合中随机选择
具体原理可以看《统计学习方法》 已经该博客http://www.cnblogs.com/JustForCS/p/5283489.html
首先是一些辅助函数的实现
def loadDataSet(fileName):
dataMat=[];labelMat=[]
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append(float(lineArr[0]),float(lineArr[1]))
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
def selectJrand(i,m):
j = i
while(j==i):
j = int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):
if aj>H:
aj = H
if L>aj:
aj = L
return ajdataArr,labelArr = svmMLiA.loadDataSet('testSet.txt') print labelArr
[-1.0, -1.0, 1.0, -1.0, 1.0, 1.0, 1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, 1.0, -1.0, 1.0, 1.0, -1.0, 1.0, -1.0, -1.0, -1.0, 1.0, -1.0, -1.0, 1.0, 1.0, -1.0, -1.0, -1.0, -1.0, 1.0, 1.0, 1.0, 1.0, -1.0, 1.0, -1.0, -1.0, 1.0, -1.0}
可以发现所有类别是1,0和-1.0
那么SMO算法的步骤如下:
创建一个aplha向量初始化为0
迭代次数小于最大迭代次数的
对数据集的每个数据向量:
如果该数据向量可以被优化
随机选择一个另外一个数据向量
同时优化两个向量
不能被优化则退出内循环
如果所有向量都没被优化增加迭代次数
简易实现
def smoSimple(dataMatIn,classLabels,C,toler,maxIter):
dataMatrix = mat(dataMatIn);labelMat = mat(classLabels).transpose()
b= 0;m,n =shape(dataMatrix)
alphas = <span style="font-family: 宋体; font-size: 9.6pt; background-color: rgb(255, 255, 255);">mat(zeros((m,</span><span style="font-family: 宋体; font-size: 9.6pt; color: rgb(0, 0, 255);">1</span><span style="font-family: 宋体; font-size: 9.6pt; background-color: rgb(255, 255, 255);">)))</span>
iter = 0
while(iter<maxIter):
alphaPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T))+b# sigma(aiyi<xi,x> +b
Ei = fXi - float(labelMat[i]) #测试是否违反了KKT条件
if((labelMat[i]*Ei<-toler)and (alphas[i]<C))or((labelMat[i]*Ei>toler)and(alphas[i]>0)):#是否违反了KKT
j = selectJrand(i,m)
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T))+b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy();alphaJold = alphas[j].copy()
if(labelMat[i]!=labelMat[j]):
L = max(0,alphas[j]-alphas[i])
H = min(C,C+alphas[j]-alphas[i])
else:
L = max(0,alphas[j]+alphas[i]-C)
H = min(C,alphas[j]+alphas[i])
if L==H:print "L==H";continue
eta = 2.0*dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta>=0:print "eta>=0";continue
alphas[j]-=labelMat[j]*(Ei-Ej)/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if(abs(alphas[j]-alphaJold)<0.00001):print "j not moving enought";continue
alphas[i]+=labelMat[j]*labelMat[i]*(alphaJold-alphas[j])
b1 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[ i,:] * dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if(0<alphas[i])and(C>alphas[i]):b = b1
elif(0<alphas[j])and(C>alphas[j]):b = b2
else:b = (b1+b2)/2.0#有一个是C或者0
alphaPairsChanged+=1
print "iter:%d i:%d ,pairs changed %d"%(iter,i,alphaPairsChanged)
if(alphaPairsChanged==0):iter+=1
else:iter = 0
print "iteration number:%d"%iter
return b,alphas具体的算式可以参照上面的论文。主要讲解下这个程序。每次循环的时候alphaPairsChanged = 0,用于记录alpha是否可以优化,计算出对应的误差Ei,如果这个误差足够大违反了KKT条件那么就可以进行优化,选择第二个alpha,而alpha更新的时候需要用copy函数因为是引用,同时需要裁剪到0到C之间。同时需要衡量最优修改量eta的值如果是等于0就退出。最后是对alpha[i]和alpha[J]进行修改,一个是增加一个是减小。程序结束条件是alpha不发生任何变化都满足kkt条件同时遍历maxiter次后退出。
测试如下:
b,alphas = svmMLiA.smoSimple(dataArr,labelArr,0.6,0.001,40)同时可以获得支持向量:
for i in range(100): if alphas[i]>0.0:print dataArr[i],labelArr[i]
[4.658191, 3.507396] -1.0
[3.457096, -0.082216] -1.0
[2.893743, -1.643468] -1.0
[6.080573, 0.418886] 1.0
完整的SMO算法加速优化
由于简化版的SMO只能处理小规模的数据集,运行速度在很大规模的时候会变慢。而唯一的不同的就是alpha的选择。需要用到一些启发式的方法,其实就是选择j后我们建立一个全局的缓存,然后选择使得Ei-Ej最大的alpha的值
class smoStruct:
def __init__(self,dataMatIn,classLabels,C,toler):
self.X = dataMatIn
self.labelMat = classLabels
self.C = C #这个参数是松弛变量的惩罚项系数也属于KKT条件一个
self.tol = toler#容错率,若误差很大就认为是最违反KKT条件的
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))#关键alpha是languarge的参数也是对偶问题的开始求解
self.eCache = mat(zeros((self.m,2)))#期望值和真实值误差在smo更新时候用
self.b = 0
#根据alpha计算预测值的公式y = sigma(alphai*yi*<x,xi>) + b
def getEk(oS,k):#统一为矩阵
#fxK = float(multiply(oS.alphas,oS.labelMat).T*\
# (oS.X*oS.X[k:].T)) + oS.b
fXk = float(multiply(oS.alphas, oS.labelMat).T * (oS.X * oS.X[k, :].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
#更新第k个的误差以及是否满足kkt
def updateEk(oS,k):
Ek = getEk(oS,k)
oS.eCache[k] = [1,Ek]
def clipAlpha(aj,H,L):
if aj>H:
aj = H
if L>aj:
aj = L
return aj
def selectJrand(i,m):
j = i
while (j==i):
j = int(random.uniform(0,m))
return j
#选择具有最大步长的J
def selectJ(i,oS,Ei):
maxK = -1;maxDeltaE = 0;Ej = 0
oS.eCache[i] = [1,Ei]#0表示i是否违反了KKT限制条件
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList))>1:
for k in validEcacheList:
if k==i:continue
Ek = getEk(oS,k)
deltaE = abs(Ei-Ek)
if (deltaE>maxDeltaE):#更新最大步长
maxK = k;maxDeltaE = deltaE;Ej = Ek
return maxK,Ej #返回使得目标函数更新最大的步长对应Ej
else:#如果个数不够的话随机选择J
j = selectJrand(i,oS.m)
Ej = getEk(oS,j)
return j,Ej
#寻找j的函数
def findJ(i,oS):
Ei = getEk(oS,i)
#启发式搜索的方法
#如果组合后误差率大于设定值同时是非边界值alphai的时候
if ((oS.labelMat[i]*Ei<-oS.tol)and (oS.alphas[i]<oS.C)) or\
((oS.labelMat[i]*Ei>oS.tol)and(oS.alphas[i]>0)):
j,Ej = selectJ(i,oS,Ei)
alphaIold = oS.alphas[i].copy();alphaJold=oS.alphas[j].copy()
#求出边界值L,H对于alphaj来说
if (oS.labelMat[i]!=oS.labelMat[j]):
L = max(0,oS.alphas[j]-oS.alphas[i])
H = min(oS.C,oS.C+oS.alphas[j]-oS.alphas[i])
else:
L = max(0,oS.alphas[j]+oS.alphas[i]-oS.C)
H = min(oS.C,oS.alphas[j]+oS.alphas[i])
if L==H:return 0
eta = 2.0*oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T- \
oS.X[j,:]*oS.X[j,:].T #相似度
if eta>=0: print "相关性大退出:";return 0
oS.alphas[j] -=oS.labelMat[j]*(Ei-Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)#裁剪边界
updateEk(oS,j)#alphaj更新为满足KKT条件
if (abs(oS.alphas[j]-alphaJold)<0.00001):#基本没更新J
return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*\
(alphaJold-oS.alphas[j])
updateEk(oS,i)
b1 = oS.b - Ei - oS.labelMat[i]*(oS.alphas[i]-alphaIold)*\
oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*\
(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * \
oS.X[i, :] * oS.X[j, :].T - oS.labelMat[j] *\
(oS.alphas[j] - alphaJold) * oS.X[j, :] * oS.X[j, :].T
if (0<oS.alphas[i]) and(oS.C>oS.alphas[i]):oS.b = b1
elif (0<oS.alphas[j]) and (oS.C>oS.alphas[j]):oS.b = b2
else:oS.b = (b1+b2)/2.0#如果都处于alpha的边界上
return 1
else:return 0
def trainBySMO(dataMatIn,classLabels,C,toler,maxIter,kTup={'lin',0}):
startTime = time.time()
oS = smoStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0
alphaPairsChanged = 0;
entireSet = True;#是遍历整个边界还是遍历整个数据集寻找违犯KKT条件的
#退出条件是如果遍历整个数据集都没有修改的话就跳出循环
while (iter<maxIter) and ((alphaPairsChanged>0)or(entireSet)):
alphaPairsChanged = 0
if entireSet:#遍历整个数据集优先
for i in range(oS.m):
alphaPairsChanged+=findJ(i,oS)
print "遍历整个数据集,迭代轮数: %d 同时改变了几次 %d" %\
(iter,alphaPairsChanged)
iter+=1
else:#遍历非边界值寻找0<ai<C的就是支持向量那些值
nonBoundIts = nonzero((oS.alphas.A>0)*(oS.alphas.A<C))[0]
for i in nonBoundIts:
alphaPairsChanged += findJ(i,oS)
print "遍历非边界数据就是支持向量 ,迭代轮数: %d 同时改变了几次 %d" %\
(iter,alphaPairsChanged)
iter+=1
if entireSet:entireSet = False
elif (alphaPairsChanged==0):entireSet = True#如果遍历的是非边界并没有违反KKT条件又回到挣个数据集
print "iteration遍历轮数: %d" % iter
print "training Complete! Took %fs"%(time.time()-startTime)
return oS.b,oS.alphas
定义一个绘制函数:
def showSVM(dataArr,labelArr,alphas,b):
m = shape(dataArr)[0]
for i in range(m):
if int(labelArr[i])== -1:
plt.plot(dataArr[i][0],dataArr[i][1],'or')
else:
plt.plot(dataArr[i][0],dataArr[i][1],'ob')
supportIndex = nonzero(alphas.A>0)[0]
for i in range(shape(supportIndex)[0]):
plt.plot(dataArr[i][0],dataArr[i][1],'oy')
#画出超平面
w = mat(zeros((2,1)))
dataMat = mat(dataArr)
labelMat = mat(labelArr).transpose()
for i in supportIndex:
w+=multiply(alphas[i]*labelMat[i],dataMat[i,:].T)
min_x = min(dataMat[:,0])[0,0]
max_x = max(dataMat[:,0])[0,0]
y_min_x = min(dataMat[:,1])[0,0]
y_max_X = max(dataMat[:,1])[0,0]
plt.plot([min_x,max_x],[y_min_x,y_max_X],'-g')
plt.show()编写了重要的注释测试代码如下:
dataArr,labelArr = SVM.loadDataSet('testSet.txt') b,alphas = SVM.trainBySMO(dataArr,labelArr,0.6,0.001,40)
结果如下:
遍历整个数据集,迭代轮数: 0 同时改变了几次 11
iteration遍历轮数: 1
遍历非边界数据就是支持向量 ,迭代轮数: 1 同时改变了几次 6
iteration遍历轮数: 2
遍历非边界数据就是支持向量 ,迭代轮数: 2 同时改变了几次 0
iteration遍历轮数: 3
遍历整个数据集,迭代轮数: 3 同时改变了几次 0
iteration遍历轮数: 4
training Complete! Took 0.050000s
计算W推测测试数据类别
我们花了很多内容计算出alpha那么如何得到具体的W呢以及我们衡量一下这个分类器的性能
#分类计算时候权重系数需要用户指定
def SVM_predict(test,alphas,dataArr,classLables,b):
X = mat(dataArr);labelMat = mat(classLables).transpose()
inputTest = mat(test)
m,n = shape(dataArr)
predMat = mat(zeros((inputTest.shape[0],1)))#输出样本
bMat = mat(tile(b,(m,1)))
for i in range(m):
predMat+= inputTest*multiply(alphas[i]*labelMat[i],X[i,:].T)
predMat+=b
return predMat
def test_SVM(predMat,classLables):
labelMat = mat(classLables).transpose()
accuracy = float(mean(sign(predMat)==sign(labelMat)))
print "准确率为%.1f"% (accuracy*100)结果如下:
准确率为100.0
分类结果是正确的
绘制超平面为:
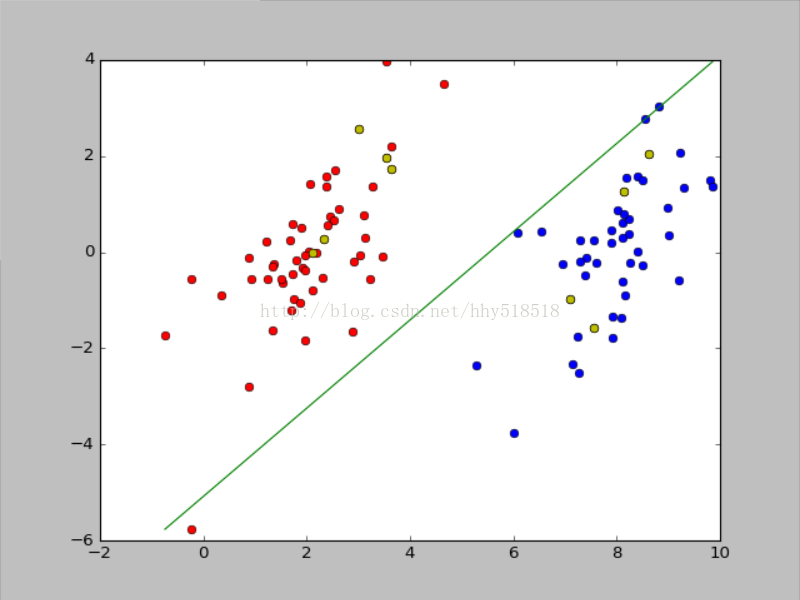
核函数
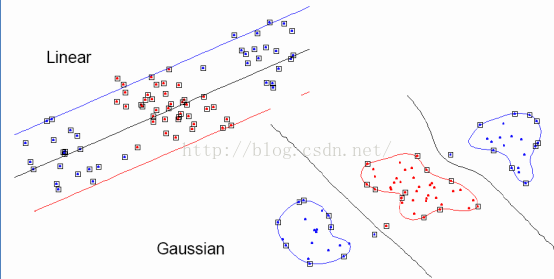
我们可以发现核函数的用处就是如图所示在低维不可分的数据映射到高维以后就可以划分了。这个过程是从一个特征空间映射到另外一个特征空间,就是通过核函数实现。我们能把核函数想象成一个包装器或者接口,它把数据从某个很难处理形式转换成比较容易处理的形式。而核函数还有个非常好的优点就是,所有运算都可以写成内积的形式,而将内积转换成核函数的方式称为核技巧
径向基核函数
这样我们得到一个核函数的必要条件:
K是有效的核函数 ==> 核函数矩阵K是对称半正定的。
可幸的是,这个条件也是充分的,由Mercer定理来表达。
| Mercer定理: 如果函数K是上的映射(也就是从两个n维向量映射到实数域)。那么如果K是一个有效核函数(也称为Mercer核函数),那么当且仅当对于训练样例,其相应的核函数矩阵是对称半正定的。 |
下面给出常见的核函数运用,径向基核函数是SVM常用的核函数,采用向量作为自变量的函数,能够基于向量距离输出一个标量。我们接下来看高斯版本
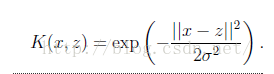
其实分母是用户定义的达率,或者说函数跌落道0的速度参数
这个函数将数据从特征空间映射道更高维的空间,具体是无穷维的空间。我们不用关心数据在新空间具体的表现形式,下面需要利用上章节实现的支持向量机来进行修改
def kernelTrick(X,test,kernelOpt): m,n = shape(X) K = mat(zeros((m,1))) if kernelOpt[0]=='lin':K = X*test.T#直接内积 elif kernelOpt[0]=='rbf': for j in range(m): deltaRow = test-X[j,:] K[j] = deltaRow*deltaRow.T K = exp(K/(-1*kernelOpt[1]**2))#测试与每个样本的高斯相似度 return K kTup是包含了核信息的元祖然后我们需要对初始化类进行修改其实就是填充的过程 class optStruct: def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters self.X = dataMatIn self.labelMat = classLabels self.C = C self.tol = toler self.m = shape(dataMatIn)[0] self.alphas = mat(zeros((self.m,1))) self.b = 0 self.eCache = mat(zeros((self.m,2))) #first column is valid flag self.K = mat(zeros((self.m,self.m))) for i in range(self.m): self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup) 然后对以前的程序进行修改,修改成以核函数表示内积 #根据alpha计算预测值的公式y = sigma(alphai*yi*<x,xi>) + b def getEk2(oS,k):#统一为矩阵 #fxK = float(multiply(oS.alphas,oS.labelMat).T*\ # (oS.X*oS.X[k:].T)) + oS.b fXk = float(multiply(oS.alphas, oS.labelMat).T * oS.K[:,k] + oS.b) Ek = fXk - float(oS.labelMat[k]) return Ek def updateEk2(oS,k): Ek = getEk2(oS,k) oS.eCache[k] = [1,Ek] #寻找J的最大步长 def selectMaxStepJ2(i,oS,Ei): maxK = -1; maxDeltaE = 0; Ej = 0 oS.eCache[i] = [1, Ei] # 0表示i是否违反了KKT限制条件 validEcacheList = nonzero(oS.eCache[:, 0].A)[0] if (len(validEcacheList)) > 1: for k in validEcacheList: if k == i: continue Ek = getEk2(oS, k) deltaE = abs(Ei - Ek) if (deltaE > maxDeltaE): # 更新最大步长 maxK = k; maxDeltaE = deltaE; Ej = Ek return maxK, Ej # 返回使得目标函数更新最大的步长对应Ej else: # 如果个数不够的话随机选择J j = selectJrand(i, oS.m) Ej = getEk2(oS, j) return j, Ej def findJByI2(i,oS): Ei = getEk2(oS,i) #启发式搜索的方法 #如果组合后误差率大于设定值同时是非边界值alphai的时候 if ((oS.labelMat[i]*Ei<-oS.tol)and (oS.alphas[i]<oS.C)) or\ ((oS.labelMat[i]*Ei>oS.tol)and(oS.alphas[i]>0)): j,Ej = selectMaxStepJ2(i,oS,Ei) alphaIold = oS.alphas[i].copy();alphaJold=oS.alphas[j].copy() #求出边界值L,H对于alphaj来说 if (oS.labelMat[i]!=oS.labelMat[j]): L = max(0,oS.alphas[j]-oS.alphas[i]) H = min(oS.C,oS.C+oS.alphas[j]-oS.alphas[i]) else: L = max(0,oS.alphas[j]+oS.alphas[i]-oS.C) H = min(oS.C,oS.alphas[j]+oS.alphas[i]) if L==H:return 0 eta = 2.0*oS.K[i,j] - oS.K[i,i]- oS.K[j,j] #相似度 if eta>=0: print "相关性大退出:";return 0 oS.alphas[j] -=oS.labelMat[j]*(Ei-Ej)/eta oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)#裁剪边界 updateEk2(oS,j)#alphaj更新为满足KKT条件 if (abs(oS.alphas[j]-alphaJold)<0.00001):#基本没更新J return 0 oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*\ (alphaJold-oS.alphas[j]) updateEk2(oS,i) b1 = oS.b - Ei - oS.labelMat[i]*(oS.alphas[i]-alphaIold)*\ oS.K[i,i] - oS.labelMat[j]*\ (oS.alphas[j]-alphaJold)*oS.K[i,j] b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * \ oS.K[i,j] - oS.labelMat[j] *\ (oS.alphas[j] - alphaJold) * oS.K[j,j] if (0<oS.alphas[i]) and(oS.C>oS.alphas[i]):oS.b = b1 elif (0<oS.alphas[j]) and (oS.C>oS.alphas[j]):oS.b = b2 else:oS.b = (b1+b2)/2.0#如果都处于alpha的边界上 return 1 else:return 0 下面就是利用高斯径向基函数进行运算,核函数类型'rbf' 优化过程结束后,在后面矩阵数学运算中建立了数据的副本,找到哪些alpha非0的值。从而得到所要支持向量 下面是测试函数 def kernel_predict(test,alphas,dataArr,Lables,b,kTup=['rbf',1.3]): dataMat = mat(dataArr) labelMat = mat(Lables).transpose() svInd = nonzero(alphas.A>0)[0]#支持向量有哪些 print "支持向量个数为: %d "%shape(svInd)[0] sVs = dataMat[svInd] testMat = mat(test) m,n = shape(testMat) predMat = zeros((m,1)) for i in range(m):#只计算alphas>0的 kernelEval = kernelTrick(sVs,testMat[i,:],kernelOpt=kTup) predMat[i] = kernelEval.T*multiply(alphas[svInd],labelMat[svInd])+b return predMat dataArr,labelArr = SVM.loadDataSet('testSetRBF.txt') testArr,testLabel = SVM.loadDataSet('testSetRBF2.txt') b,alphas = SVM.trainBySMO(dataArr,labelArr,200,0.0001,10000,kTup=['rbf',1.3]) predMat = SVM.kernel_predict(testArr,alphas,dataArr,labelArr,b) print SVM.test_SVM(predMat,testLabel)得到结果: 遍历整个数据集,迭代轮数: 0 同时改变了几次 28 iteration遍历轮数: 1 遍历非边界数据就是支持向量 ,迭代轮数: 1 同时改变了几次 3 iteration遍历轮数: 2 遍历非边界数据就是支持向量 ,迭代轮数: 2 同时改变了几次 4 iteration遍历轮数: 3 遍历非边界数据就是支持向量 ,迭代轮数: 3 同时改变了几次 0 iteration遍历轮数: 4 遍历整个数据集,迭代轮数: 4 同时改变了几次 2 iteration遍历轮数: 5 遍历非边界数据就是支持向量 ,迭代轮数: 5 同时改变了几次 0 iteration遍历轮数: 6 遍历整个数据集,迭代轮数: 6 同时改变了几次 0 iteration遍历轮数: 7 training Complete! Took 0.472000s 支持向量个数为: 27 准确率为96.0














 4387
4387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









