






备注:今年1月份写的文章,以后准备长期驻扎在这儿,就贴过来了。
1.12号晚上总算彻底的考完了所有的科目,昨天可以睡一个安稳的懒觉了。从床上爬起来之后,随便从书架上拿了一本书,竟然是《备战大学德语四级考试·词汇篇》,不觉想起当初“战绩辉煌”的德语课。翻开书,看了几个单词后,发现都忘记了该怎么发音,所以想把每个单词的发音放到P3里,等睡不着的时候可以听一听~。
所以,具体需求就是:根据一个文本文件,该文件中提供了一个单词列表,格式为每个单词占一行。需要根据这个列表,从某个网站上把对应单词的发音的mp3文件保存在本地磁盘上,而且mp3文件保存为相应的单词的名称。
大致就是这些,想想还缺点什么,恩,多线程---典型的多线程应用环境啊。确定一下实现环境,看来Python是首选了。因为快,当然是说开发速度快了~
该找个网站,从google上搜了搜(最近学校可以用ipv6的google了,速度很快,过滤也少),找到一个网站http://www.leo.de/,上面有一个Deutsch–Englisch的图标,当然也有Deutsch –Chinesisch图标,想想欧洲人那种自恃清高的态度,还是果断选了Deutsch-Englisch。随便搜索一个单词,比如“abendessen”,然后会弹出一个列表,点击发音图标的时候,会弹出一个框,框中还有一个推荐网站http://www.dwds.de/。点击之后,感觉风格清新自然简洁。还是输入刚刚那个单词“abendessen”,点击“suche”之后,在浏览器上看到一个URL是http://www.dwds.de/?qu=abendessen&view=1。 view=1区分了是从主页搜索单词还是从搜索单词后弹出的某个页面中搜索的单词两种情况。可以在当前这个页面(http://www.dwds.de/?qu=abendessen&view=1)再输入“abendessen”,点击“suche”后,你会发现URL地址已经改变了,变为:http://www.dwds.de/?qu=abendessen。
再试几个单词后,基本就可以确定每个单词对应的查询页面的URL地址格式为:
http://www.dwds.de/?qu=所查询的单词
接下来就是看下声音地址的组成格式。查看下页面的Html源代码,CTRL+F搜索sound。在刚刚查询“abendessen”的页面中可以找到这样的一个filename: http://media.dwds.de/dwds/media/sound/dwdswb_aussprache_dev/0ddaf706368d33af4d5aca4cebb41f17.mp3。可以基本确信对应于每个单词的mp3文件格式如下:
http://media.dwds.de/dwds/media/sound/dwdswb_aussprache_dev/+单词对应的哈希值.mp3
不知道这里为什么要用哈希值,可以肯定的是不是用来提高检索速度的,因为单词本身就可以作为唯一的键,而且单词的最大长度应该也不会超过一个固定的上限值(比如:40?)。也许使用哈希值是为了防止用程序自动下载发音文件,减少对服务器的冲击吧,我猜。刚看到这个32位的串,我想大家第一反应应该都是猜它是不是单词对应的md5值(比如QQ登录的时候,就对针对密码进行三次md5加密),很不幸的,这个串不是(这个,可以使用Python在交互式模式下做一个简单的验证)。不过这个并不影响下载这个mp3文件,恩,就是先打开页面,然后从页面上找到mp3的URL,然后再下载。
好了,整理一下思路,简单的说,下载一个单词对应的mp3的流程如下:
Step1:从文件中读取一个单词
Step2:构造一个单词查询页面的URL,将此URL对应的html源代码保存到content中
Step3:使用正则表达式在content中搜索对应mp3文件的URL
Step4:读取mp3数据,在本地新建一个文件,把数据保存进去
Step5:如果没有结束,跳转到Step1
恩,挺简单的流程。还需要增添的设施就是多线程,测试表明,平均每下载一个单词将近4秒钟,不能在一个线程在访问网络或者保存文件的时候让CPU空闲啊。所以,在运行程序的时候需要传入两个参数,一个就是需要开启的线程的数量,另外一个就是保存单词列表的文件名。不过,等我改天有时间了,实现一个线程池,这样就省事了,把任务扔到池子里就行了。否则在程序中还要考虑加锁解锁这种琐碎的事情,因为保存单词列表的队列是共享资源。这些分析清楚了,差不多就可以写代码了。把代码贴到这儿,仅供参考:
- #!/usr/bin/python
- #Author:lichao
- #Date:01-13-2012
- #Description:Download the .mp3 sound files that correspoding to the words in the given file.
- import threading
- import time
- import fileinput
- import re
- import urllib2
- import sys
- class DownloadWorker(threading.Thread):
- global mutext
- def __init__(self,wordsList,workerIndex):
- threading.Thread.__init__(self)
- self.queue=wordsList
- self.index=workerIndex
- def run(self):
- print('worker%d start to work' % (self.index))
- mutex.acquire()
- self.word=self.queue.front()
- mutex.release()
- while self.word!="0":
- url = "http://www.dwds.de/?qu="+self.word
- urlContent = urllib2.urlopen(url).read()
- urlList = re.findall('http://media.dwds.de/dwds/media/sound/dwdswb_aussprache_dev/.*\.mp3', urlContent)
- try:
- soundData = urllib2.urlopen(urlList[0]).read()
- saveName=self.word+".mp3"
- output = open(saveName,'wb')
- output.write(soundData)
- output.close()
- print('%s:OK --Post by worker%d' % (self.word,self.index) )
- except:
- print('%s:FAILED --Post by worker%d' % (self.word,self.index) )
- finally:
- mutex.acquire()
- self.word=self.queue.front()
- mutex.release()
- print('worker%d eixt' % self.index)
- class WordsList():
- def __init__(self,filePath):
- self.t=[]
- for line in fileinput.input(filePath):
- if(len(line)>1 and line[len(line)-1]=='\n'):
- line=line[0:len(line)-1]
- self.t.append(line)
- else:
- self.t.append(line)
- self.t.append('0')
- def front(self):
- if(self.t[0]!='0'):
- return self.t.pop(0)
- else:
- return self.t[0]
- def main():
- global mutex
- mutex=threading.Lock()
- workerNumber=int(sys.argv[1])
- filePath=sys.argv[2]
- wordsList=WordsList(filePath)
- workerPool=[]
- for i in range(0,workerNumber):
- worker=DownloadWorker(wordsList,i)
- workerPool.append(worker)
- for i in range(0,workerNumber):
- workerPool[i].start()
- if __name__ == "__main__":
- main()
下面两张截图是运行效果图,其中图1是运行效果图。是的,有些单词的mp3下载过程中出错了,这是由于某些单词的发音太简单了,这些单词级别估计是1级,估计是网站的设计者觉得这种简单的单词没有必要制作一个mp3文件放在上面。一般来说,稍难一点的单词的发音都能下载到的。图2是下载后的截图,以后可以用来催眠了。
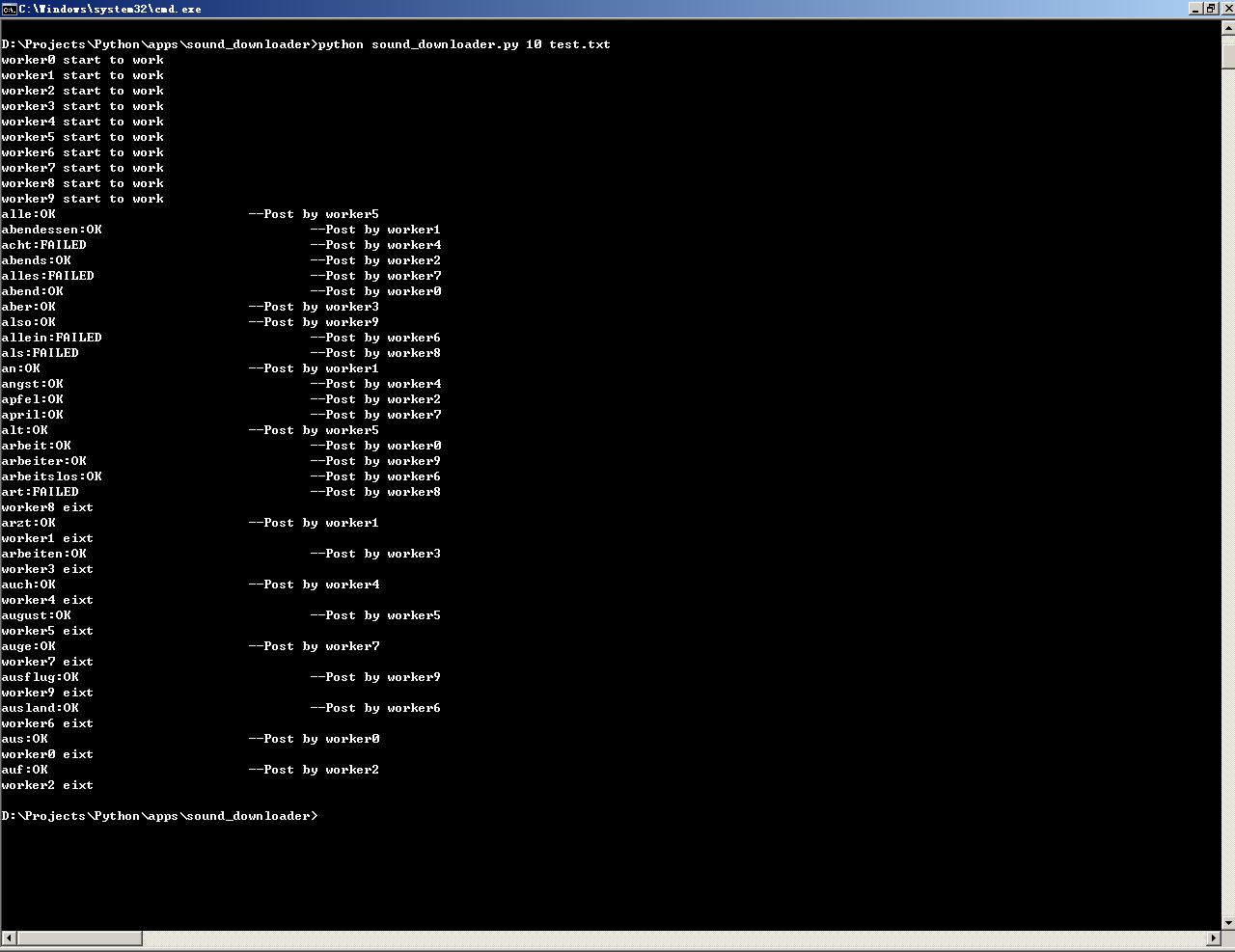
图1:下载器运行效果
图2:保存的声音文件
本文出自 “相信并热爱着” 博客,转载请与作者联系!














 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









