







ParallelGC
再来看看parallelGC的结果。
截取其中一段放大如下:
JVM参数如下:
java -jar -Xms10g -Xmx15g -XX:+UseParallelGC -XX:ParallelGCThreads=8 -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:./log/gc.log Slaver.jar
XX:ParallelGCThreads是用来设置GC并行线程的数量,由于我的测试服务器是8个core,所以这里也设置成了8;
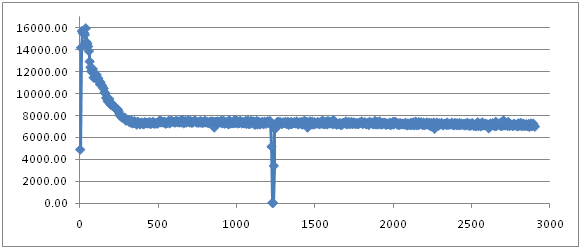
和上一篇中SerialGC的实验结果图相比,有了很大的差别:
首先是整条throughput曲线的抖动明显下降了,并且,更重要的是,整个系统的平均throughput提高了。SerialGC中的曲线在6000左右抖动,而这的实验结果图中,throughput基本上在7000以上。这说明MinorGC对系统造成的影响变小了,为了确认这一点,可以随意看一条Minor GC的log:
1020.911: [GC [PSYoungGen: 6252096K->22304K(6260544K)] 9744749K->3537437K(10454848K), 0.0831140 secs] [Times: user=0.62 sys=0.06, real=0.09 secs ]
从log中读出,一个minor GC在0.09秒内就完成了,相当于只阻塞了application 0.09秒的时间,和SerialGC相比,大概缩短为它的几分之一。正是因为minor GC的时间变短,所以系统受到的影响变小,整体性能也显著提高。
实际上,在Sun的官方文档中,ParallelGC也是被推荐为“能够最大化系统的throughput”。而且,在服务器一级的机器上,ParallelGC是被设置为默认的GC collector,也就是说,如果JVM参数什么没有,那么就是采用Parallel GC。
有一个需要注意的是,虽然real time是0.09秒,但是user time是real time的好几倍,正好说明在执行minor GC的时候是由多个thread共同完成的。
不过,和SerialGC一样,它也有一个大峡谷,和SerialGC一样,这也是Full GC发生的地方:
1239.230: [Full GC [PSYoungGen: 22048K->17780K(6268352K)] [PSOldGen: 4190181K->4194303K(9437184K)] 4212229K->4212084K(15705536K) [PSPermGen: 11049K->11049K(22400K)], 14.1572170 secs] [Times: user=14.15 sys=0.01, real=14.16 secs ]
整个Full GC持续了14.16秒,这段时间系统的throughput下降为0。这点上,ParallelGC和SerialGC相比并没有任何优势。并且,user time和real time值差不多,说明也是由单线程完成的Full GC的工作。
最后需要指出的是,采用ParallelGC的实验发生Full GC的时间和Seral GC相比要更早一些。这主要是因为平均的throughput要比前者更好,所以插入数据的速度更快,所以tenured generation更早的就被数据填满了。
ParallelOldGC
JVM参数如下:
java -jar -Xms10g -Xmx15g -XX:+UseParallelOldGC -XX:ParallelGCThreads=8 -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:./log/gc.log Slaver.jar
实验结果:
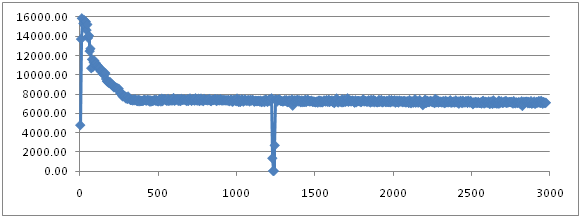
实验结果几乎和ParallelGC一模一样。
它的minor GC的机制和ParallelGC是一样的,所以就不多说了。
但是在Full GC的时候还是有一些差别:
1248.458: [Full GC [PSYoungGen: 22176K->0K(6268224K)] [ParOldGen: 4179368K->4166292K(9437184K)] 4201544K->4166292K(15705408K) [PSPermGen: 11047K->11032K(22400K)], 17.1588660 secs] [Times: user=124.85 sys=0.53, real=17.16 secs ]
老实说,这个结果有些出乎意料。因为按照文档,ParallelOldGC在执行FullGC的时候是多线程工作的,我原以为Full GC的时间就会相应的缩短很多。但是,至少在我的实验中,两者的Full GC的时间差不多(14.16 vs 17.16)。唯一让我确定ParallelOldGC确实是采用多线程工作的是,user time相比real time委实大了好几倍。但是貌似多线程的Full GC在我这里没有起到作用。
(CMS collector比较麻烦,下篇再说)
补充一下,前一篇中各种collector的示意图摘自:
http://www.devx.com/java/Article/21977/0/page/3














 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









