






一、并行计算概述 在计算机术语中,并行性是指:把一个复杂问题,分解成多个能同时处理的子问题的能力。要实现并行计算,首先我们要有物理上能够实现并行计算的硬件设备,比如多核CPU,每个核能同时实现算术或逻辑运算。在计算机术语中,并行性是指:把一个复杂问题,分解成多个能同时处理的子问题的能力。要实现并行计算,首先我们要有物理上能够实现并行计算的硬件设备,比如多核CPU,每个核能同时实现算术或逻辑运算。 通常,我们通过GPU实现两类并行计算:通常,我们通过GPU实现两类并行计算: 任务并行:把一个问题分解为能够同时执行的多个任务。任务并行:把一个问题分解为能够同时执行的多个任务。 数据并行:同一个任务内,它的各个部分同时执行。数据并行:同一个任务内,它的各个部分同时执行。 下面我们通过一个农场主雇佣工人摘苹果的例子来描述不同种类的并行计算。下面我们通过一个农场主雇佣工人摘苹果的例子来描述不同种类的并行计算。-
摘苹果的工人就是硬件上的并行处理单元(process elements)。 -
树就是要执行的任务。 -
苹果就是要处理的数据。
串行的任务处理就如下图所示,一个工人背着梯子摘完所有树上的苹果(一个处理单元处理完所有任务的数据)。一个处理单元处理完所有任务的数据)。
数据并行就好比农场主雇佣了好多工人来摘完一个树上的苹果(多个处理单元并行完成一个任务中的数据),这样就能很快摘完一颗树上的苹果。

农场主也可以为每棵树安排一个工人,这就好比任务并行。在每个任务内,由于只有一个工人,所以是串行执行的,但任务之间是并行的。

对一个复杂问题,影响并行计算的因素很多。通常,我们都是通过分解问题的方式来实施并算法行。
这又包括两方面内容:
- 任务分解:把算法分解成很多的小任务,就像前面的例子中,把果园按苹果树进行划分,这时我们并不关注数据,也就是说不关注每个树上到底有多少个苹果。
- 数据分解:就是把很多数据,分成不同的、离散的小块,这些数据块能够被并行执行,就好比前面例子中的苹果。
通常我们按照算法之间的依赖关系来分解任务,这样就形成了一个任务关系图。一个任务只有没有依赖任务的时候,才能够被执行。
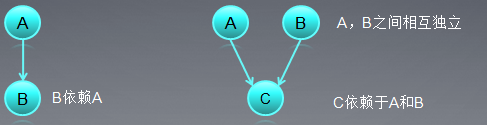
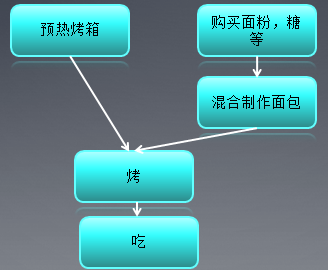
这有点类似于数据结构中的有向无环图,两个没有连通路径的任务之间可以并行执行。下面再给一个烤面包的例子,如果所示,预热烤箱和购买面粉糖两个任务之间可以并行执行。
对大多数科学计算和工程应用来说,数据分解一般都是基于输出数据,例如:
- 在一副图像中,对一个滑动窗口(例如:3*3像素)内的像素实施滤波操作,可以得到一个输出像素的卷积。
- 第一个输入矩阵的第i行乘以第二个输入矩阵的第j列,得到的向量和即为输出矩阵第i行,第j列的元素。
这种方法对于输入和输出数据是一对一,或者多对一的对应关系比较有效。
也有的数据分解算法是基于输入数据的,这时,输入数据和输出数据一般是一对多的关系,比如求图像的直方图,我们要把每个像素放到对应的槽中(bins,对于灰度图,bin数量通常是256)。一个搜索函数,输入可能是多个数据,输出却只有一个值。对于这类应用,我们一般用每个线程计算输出的一部分,然后通过同步以及原子操作得到最终的值,OpenCL中求最小值的kernel函数就是典型代表[可以看下ATI Stream Computing OpenCL programming guide第二章中求最小值的kernel例子]。
通常来说,怎样分解问题和具体算法有关,而且还要考虑自己使用的硬件和软件,比如AMD GPU平台和Nvdia GPU平台的优化就有很多不同。
二、常用基于硬件和软件的并行
在上个实际90年代,并行计算主要研究如何在cpu上实施指自动的指令级并行。
- 同时发射多条指令(之间没有依赖关系),并行执行这些指令。
- 在本教程中,我么不讲述自动的硬件级并行,感兴趣的话,可以看看计算机体系结构的教程。
高层的并行,比如线程级别的并行,一般很难自动化,需要程序员告诉计算机,该做什么,不该做什么。这时,程序员还要考虑硬件的具体指标,通常特定硬件都是适应于某一类并行编程,比如多核cpu就适合基于任务的并行编程,而GPU更适应于数据并行编程。
| Hardware type | Examples | Parallelism |
| Multi-core superscalar processors | Phenom II CPU | Task |
| Vector or SIMD processors | SSE units (x86 CPUs) | Data |
| Multi-core SIMD processors | Radeon 5870 GPU | Data |
现代的GPU有很多独立的运算核(processor)组成,在AMD GPU上就是stream core,这些core能够执行SIMD操作(单指令,多数据),所以特别适合数据并行操作。通常GPU上执行一个任务,都是把任务中的数据分配到各个独立的core中执行。
在GPU上,我们一般通过循环展开,Loop strip mining 技术,来把串行代码改成并行执行的。比如在CPU上,如果我们实现一个向量加法,代码通常如下:
1: for(i = 0; i < n; i++) 2: { 3: C[i] = A[i] + B[i]; 4: }在GPU上,我们可以设置n个线程,每个线程执行一个加法,这样大大提高了向量加法的并行性。
1: __kernel void VectorAdd(__global const float* a, __global const float* b, __global float* c, int n) 2: { 3: int i = get_global_id(0); 4: c[i] = a[i] + b[i]; 5: }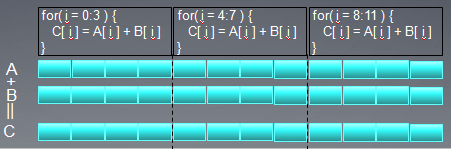
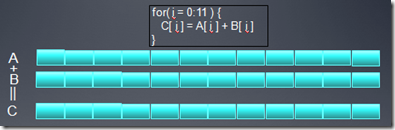

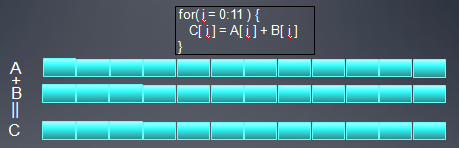
上面这个图展示了向量加法的SPMD(单指令多线程)实现,从图中可以看出如何实施Loop strip mining 操作的。
GPU的程序一般称作Kernel程序,它是一种SPMD的编程模型(the Single Program Multiple Data )。SPMD执行同一段代码的多个实例,每个实例对数据的不同部分进行操作。
在数据并行应用中,用loop strip mining来实现SPMD是最常用的方法:
-
- 在分布式系统中,我们用Message Passing Interface (MPI)来实现SPMD。
- 在共享内存并行系统中,我们用POSIX线程来实现SPMD。
- 在GPU中,我们就是用Kernel来显现SPMD。
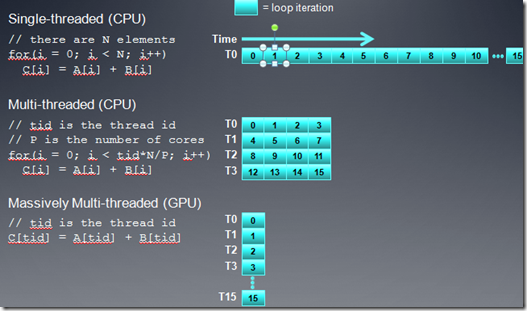
在现代的CPU上,创建一个线程的开销还是很大的,如果要在CPU上实现SPMD,每个线程处理的数据块就要尽量大点,做更多的事情,以便减少平均线程开销。但在GPU上,都是轻量级的线程,创建、调度线程的开销比较小,所以我们可以做到把循环完全展开,一个线程处理一个数据。
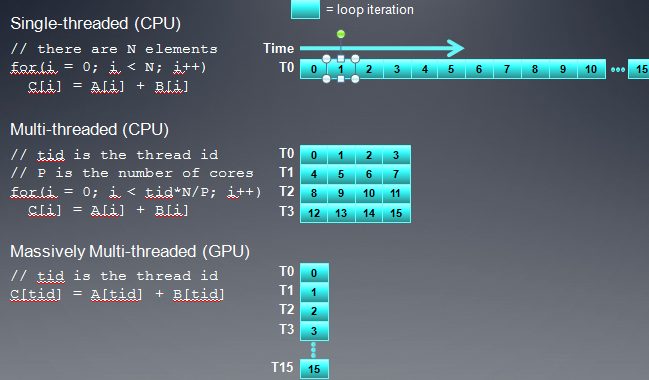
GPU上并行编程的硬件一般称作SIMD。通常,发射一条指令后,它要在多个ALU单元中执行(ALU的数量即使simd的宽度),这种设计减少了控制流单元以级ALU相关的其他硬件数量。
SIMD的硬件如下图所示:
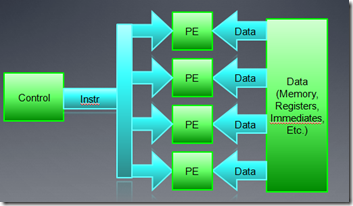

在向量加法中,宽度为4的SIMD单元,可以把整个循环分为四个部分同时执行。在工人摘苹果的例子中,工人的双手类似于SIMD的宽度为2。另外,我们要知道,现在的GPU硬件上都是基于SIMD设计,GPU硬件隐式的把SPMD线程映射到SIMD core上。对开发有人员来说,我们并不需要关注硬件执行结果是否正确,我们只需要关注它的性能就OK了。
CPU一般都支持并行级的原子操作,这些操作保证不同的线程读写数据,相互之间不会干扰。有些GPU支持系统范围的并行操作,但会有很大开销,比如Global memory的同步。
1、OpenCL架构
OpenCL可以实现混合设备的并行计算,这些设备包括CPU,GPU,以及其它处理器,比如Cell处理器,DSP等。使用OpenCL编程,可以实现可移植的并行加速代码。[但由于各个OpenCL device不同的硬件性能,可能对于程序的优化还要考虑具体的硬件特性]。
通常OpenCL架构包括四个部分:
- 平台模型(Platform Model)
- 执行模型(Execution Model)
- 内存模型(Memory Model)
- 编程模型(Programming Model)
2、OpenCL平台模型
不同厂商的OpenCL实施定义了不同的OpenCL平台,通过OpenCL平台,主机能够和OpenCL设备之间进行交互操作。现在主要的OpenCL平台有AMD、Nvida,Intel等。OpenCL使用了一种Installable Client Driver模型,这样不同厂商的平台就能够在系统中共存。在我的计算机上就安装有AMD和Intel两个OpenCL Platform[现在的OpenCL driver模型不允许不同厂商的GPU同时运行]。
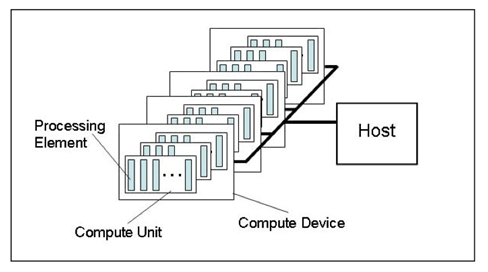
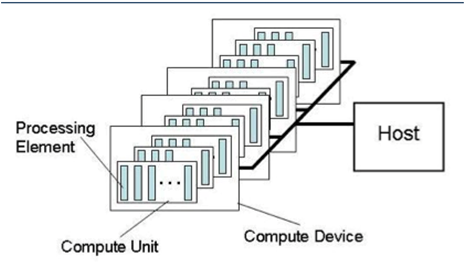
OpenCL平台通常包括一个主机(Host)和多个OpenCL设备(device),每个OpenCL设备包括一个或多个CU(compute units),每个CU包括又一个或多个PE(process element)。 每个PE都有自己的程序计数器(PC)。主机就是OpenCL运行库宿主设备,在AMD和Nvida的OpenCL平台中,主机一般都指x86 CPU。
对AMD平台来说,所有的CPU是一个设备,CPU的每一个core就是一个CU,而每个GPU都是独立的设备。
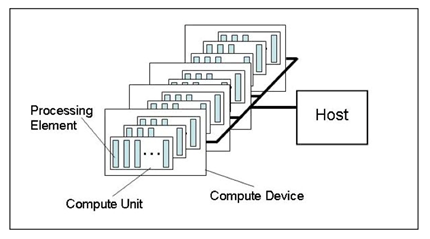
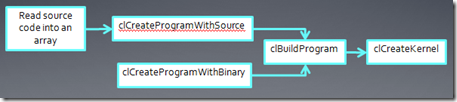
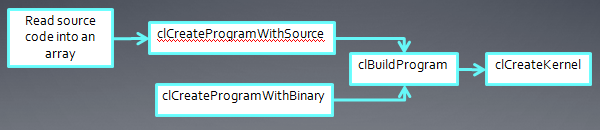
3、OpenCL编程的一般步骤
下面我们通过一个实例来了解OpenCL编程的步骤,假设我们用的是AMD OpenCL平台(因为本人的GPU是HD5730),安装了AMD Stream SDK 2.6,并在VS2008中设置好了include,lib目录等。
首先我们建立一个控制台程序,最初的代码如下:
1: #include "stdafx.h" 2: #include <CL/cl.h> 3: #include <stdio.h> 4: #include <stdlib.h> 5: 6: #pragma comment (lib,"OpenCL.lib") 7: 8: int main(int argc, char* argv[]) 9: { 10: return 0; 11: }
第一步,我们要选择一个OpenCL平台,所用的函数就是


通常,这个函数要调用2次,第一次得到系统中可使用的平台数目,然后为(Platform)平台对象分配空间,第二次调用就是查询所有的平台,选择自己需要的OpenCL平台。代码比较长,具体可以看下AMD Stream SDK 2.6中的TemplateC例子,里面描述如何构建一个robust的最小OpenCL程序。为了简化代码,使程序看起来不那么繁琐,我直接调用该函数,选取系统中的第一个OpenCL平台,我的系统中安装AMD和Intel两家的平台,第一个平台是AMD的。另外,我也没有增加错误检测之类的代码,但是增加了一个status的变量,通常如果函数执行正确,返回的值是0。
1: #include "stdafx.h" 2: #include <CL/cl.h> 3: #include <stdio.h> 4: #include <stdlib.h> 5: 6: #pragma comment (lib,"OpenCL.lib") 7: 8: int main(int argc, char* argv[]) 9: { 10: cl_uint status; 11: cl_platform_id platform; 12: 13: status = clGetPlatformIDs( 1, &platform, NULL ); 14: 15: return 0; 16: }第二步是得到OpenCL设备,


这个函数通常也是调用2次,第一次查询设备数量,第二次检索得到我们想要的设备。为了简化代码,我们直接指定GPU设备。
1: #include "stdafx.h" 2: #include <CL/cl.h> 3: #include <stdio.h> 4: #include <stdlib.h> 5: 6: #pragma comment (lib,"OpenCL.lib") 7: 8: int main(int argc, char* argv[]) 9: { 10: cl_uint status; 11: cl_platform_id platform; 12: 13: status = clGetPlatformIDs( 1, &platform, NULL ); 14: 15: cl_device_id device; 16: 17: clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU, 18: 1, 19: &device, 20: NULL); 21: 22: return 0; 23: }下面我们来看下OpenCL中Context的概念:
通常,Context是指管理OpenCL对象和资源的上下文环境。为了管理OpenCL程序,下面的一些对象都要和Context关联起来:
—设备(Devices):执行Kernel程序对象。
—程序对象(Program objects): kernel程序源代码
—Kernels:运行在OpenCL设备上的函数。
—内存对象(Memory objects): device处理的数据对象。
—命令队列(Command queues): 设备之间的交互机制。
注意:创建一个Context的时候,我们必须把一个或多个设备和它关联起来。对于其它的OpenCL资源,它们创建时候,也要和Context关联起来,一般创建这些资源的OpenCL函数的输入参数中,都会有context。


这个函数中指定了和context关联的一个或多个设备对象,properties参数指定了使用的平台,如果为NULL,厂商选择的缺省值被使用,这个函数也提供了一个回调机制给用户提供错误报告。
现在的代码如下:
1: #include "stdafx.h" 2: #include <CL/cl.h> 3: #include <stdio.h> 4: #include <stdlib.h> 5: 6: #pragma comment (lib,"OpenCL.lib") 7: 8: int main(int argc, char* argv[]) 9: { 10: cl_uint status; 11: cl_platform_id platform; 12: 13: status = clGetPlatformIDs( 1, &platform, NULL ); 14: 15: cl_device_id device; 16: 17: clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU, 18: 1, 19: &device, 20: NULL); 21: cl_context context = clCreateContext( NULL, 22: 1, 23: &device, 24: 25: 26: return 0; 27: }接下来,我们要看下命令队列。在OpenCL中,命令队列就是主机的请求,在设备上执行的一种机制。
- 在Kernel执行前,我们一般要进行一些内存拷贝的工作,比如把主机内存中的数据传输到设备内存中。
另外要注意的几点就是:对于不同的设备,它们都有自己的独立的命令队列;命令队列中的命令(kernel函数)可能是同步的,也可能是异步的,它们的执行顺序可以是有序的,也可以是乱序的。


命令队列在device和context之间建立了一个连接。
命令队列properties指定以下内容:
- 是否乱序执行(在AMD GPU中,好像现在还不支持乱序执行)
- 是否启动profiling。Profiling通过事件机制来得到kernel执行时间等有用的信息,但它本身也会有一些开销。
如下图所示,命令队列把设备和context联系起来,尽管它们之间不是物理连接。

添加命令队列后的代码如下:
1: #include "stdafx.h" 2: #include <CL/cl.h> 3: #include <stdio.h> 4: #include <stdlib.h> 5: 6: #pragma comment (lib,"OpenCL.lib") 7: 8: int main(int argc, char* argv[]) 9: { 10: cl_uint status; 11: cl_platform_id platform; 12: 13: status = clGetPlatformIDs( 1, &platform, NULL ); 14: 15: cl_device_id device; 16: 17: clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU, 18: 1, 19: &device, 20: NULL); 21: cl_context context = clCreateContext( NULL, 22: 1, 23: &device, 24: NULL, NULL, NULL); 25: 26: cl_command_queue queue = clCreateCommandQueue( context, 27: device, 28: CL_QUEUE_PROFILING_ENABLE, NULL ); 29: 30: return 0; 31: }
OpenCL内存对象:
OpenCL内存对象就是一些OpenCL数据,这些数据一般在设备内存中,能够被拷入也能够被拷出。OpenCL内存对象包括buffer对象和image对象。
buffer对象:连续的内存块----顺序存储,能够通过指针、行列式等直接访问。
image对象:是2维或3维的内存对象,只能通过read_image() 或 write_image()来读取。image对象可以是可读或可写的,但不能同时既可读又可写。

该函数会在指定的context上创建一个buffer对象,image对象相对比较复杂,留在后面再讲。
flags参数指定buffer对象的读写属性,host_ptr可以是NULL,如果不为NULL,一般是一个有效的host buffer对象,这时,函数创建OpenCL buffer对象后,会把对应host buffer的内容拷贝到OpenCL buffer中。
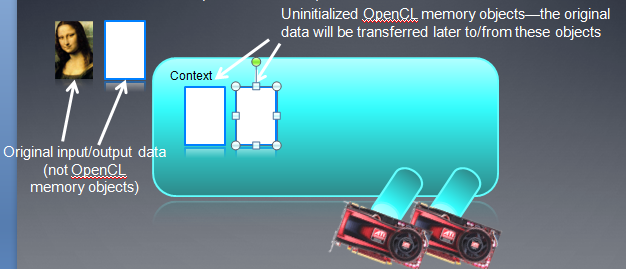
在Kernel执行之前,host中原始输入数据必须显式的传到device中,Kernel执行完后,结果也要从device内存中传回到host内存中。我们主要通过函数clEnqueue{Read|Write}{Buffer|Image}来实现这两种操作。从host到device,我们用clEnqueueWrite,从device到host,我们用clEnqueueRead。clEnqueueWrite命令包括初始化内存对象以及把host 数据传到device内存这两种操作。当然,像前面一段说的那样,也可以把host buffer指针直接用在CreateBuffer函数中来实现隐式的数据写操作。

这个函数初始化OpenCL内存对象,并把相应的数据写到OpenCL内存关联的设备内存中。其中,blocking_write参数指定是数拷贝完成后函数才返回还是数据开始拷贝后就立即返回(阻塞模式于非阻塞模式)。Events参数指定这个函数执行之前,必须要完成的Event(比如先要创建OpenCL内存对象的Event)。
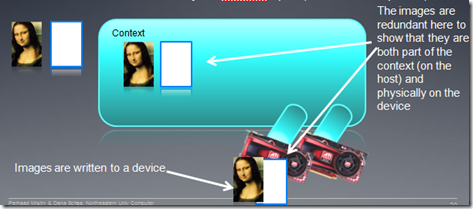

OpenCL程序对象:
程序对象就是通过读入Kernel函数源代码或二进制文件,然后在指定的设备上进行编译而产生的OpenCL对象。



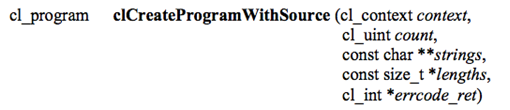
这个函数通过源代码(strings),创建一个程序对象,其中counts指定源代码串的数量,lengths指定源代码串的长度(为NULL结束的串时,可以省略)。当然,我们还必须自己编写一个从文件中读取源代码串的函数。

对context中的每个设备,这个函数编译、连接源代码对象,产生device可以执行的文件,对GPU而言就是设备对应shader汇编。如果device_list参数被提供,则只对这些设备进行编译连接。options参数主要提供一些附加的编译选项,比如宏定义、优化开关标志等等。
如果程序编译失败,我们能够根据返回的状态,通过调用clGetProgramBuildInfo来得到错误信息。
加上创建内存对象以及程序对象的代码如下:
1: 2: #include "stdafx.h" 3: #include <CL/cl.h> 4: #include <stdio.h> 5: #include <stdlib.h> 6: #include <time.h> 7: #include <iostream> 8: #include <fstream> 9: 10: using namespace std; 11: #define NWITEMS 262144 12: 13: #pragma comment (lib,"OpenCL.lib") 14:
Kernel对象:
Kernel就是在程序代码中的一个函数,这个函数能在OpenCL设备上执行。一个Kernel对象就是kernel函数以及其相关的输入参数。

Kernel对象通过程序对象以及指定的函数名字创建。注意:函数必须是程序源代码中存在的函数。


运行时编译:
在运行时,编译程序和创建kernel对象是有时间开销的,但这样比较灵活,能够适应不同的OpenCL硬件平台。程序动态编译一般只需一次,而Kernel对象在创建后,可以反复调用。
创建Kernel后,运行Kernel之前,我们还要为Kernel对象设置参数。我们可以在Kernel运行后,重新设置参数再次运行。

arg_index指定该参数为Kernel函数中的第几个参数(比如第一个参数为0,第二个为1,…)。内存对象和单个的值都可以作为Kernel参数。下面是2个设置Kernel参数的例子:
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*)&d_iImage);
clSetKernelArg(kernel, 1, sizeof(int), (void*)&a);

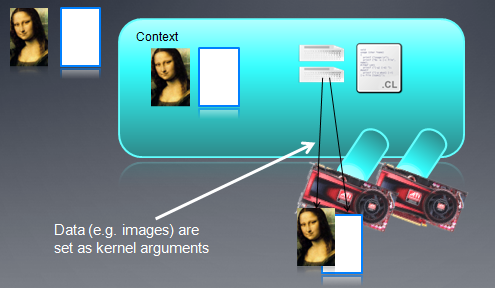
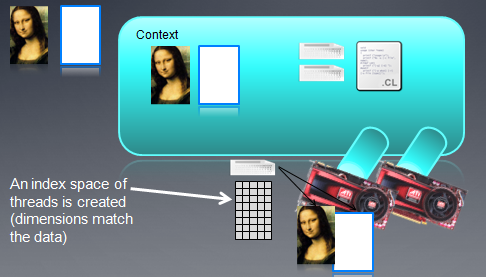
在Kernel运行之前,我们先看看OpenCL中的线程结构:
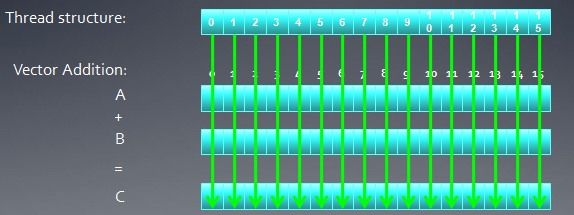
大规模并行程序中,通常每个线程处理一个问题的一部分,比如向量加法,我们会把两个向量中对应的元素加起来,这样,每个线程可以处理一个加法。
下面我看一个16个元素的向量加法:两个输入缓冲A、B,一个输出缓冲C

在这种情况下,我们可以创建一维的线程结构去匹配这个问题。

每个线程把自己的线程id作为索引,把相应元素加起来。

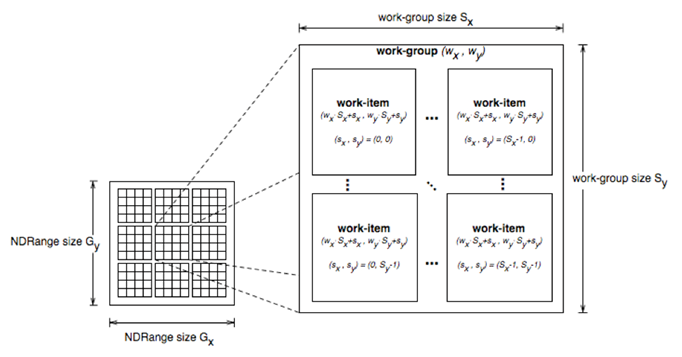
OpenCL中的线程结构是可缩放的,Kernel的每个运行实例称作WorkItem(也就是线程),WorkItem组织在一起称作WorkGroup,OpenCL中,每个Workgroup之间都是相互独立的。
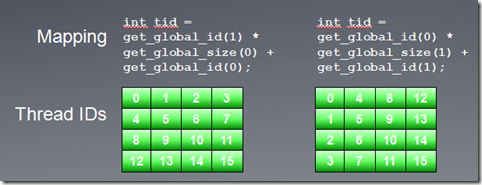
通过一个global id(在索引空间,它是唯一的)或者一个workgroup id和一个work group内的local id,我就能标定一个workitem。

在kernel函数中,我们能够通过API调用得到global id以及其他信息:
get_global_id(dim)
get_global_size(dim)
这两个函数能得到每个维度上的global id。
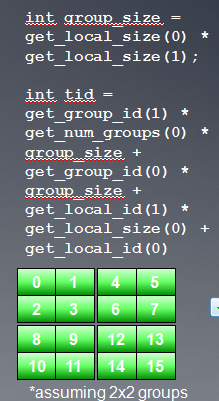
get_group_id(dim)
get_num_groups(dim)
get_local_id(dim)
get_local_size(dim)
这几个函数用来计算group id以及在group内的local id。
get_global_id(0) = column, get_global_id(1) = row
get_num_groups(0) * get_local_size(0) == get_global_size(0)
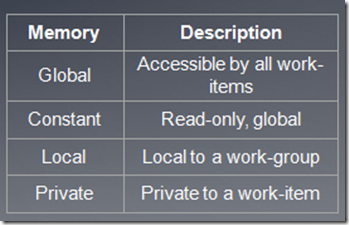
OpenCL内存模型
OpenCL的内存模型定义了各种各样内存类型,各种内存模型之间有层级关系。各种内存之间的数据传输必须是显式进行的,比如从host memory到device memory,从global memory到local memory等等。


WorkGroup被映射到硬件的CU上执行(在AMD 5xxx系列显卡上,CU就是simd,一个simd中有16个pe,或者说是stream core),OpenCL并不提供各个workgroup之间的一致性,如果我们需要在各个workgroup之间共享数据或者通信之类的,要自己通过软件实现。
Kernel函数的写法
每个线程(workitem)都有一个kenerl函数的实例。下面我们看下kernel的写法:
1: __kernel void vecadd(__global const float* A, __global const float* B, __global float* C) 2: { 3: int id = get_global_id(0); 4: C[id] = A[id] + B[id]; 5: }每个Kernel函数都必须以__kernel开始,而且必须返回void。每个输入参数都必须声明使用的内存类型。通过一些API,比如get_global_id之类的得到线程id。
内存对象地址空间标识符有以下几种:
__global – memory allocated from global address space
__constant – a special type of read-only memory
__local – memory shared by a work-group
__private – private per work-item memory
__read_only/__write_only – used for images
Kernel函数参数如果是内存对象,那么一定是__global,__local或者constant。
运行Kernel
首先要设置线程索引空间的维数以及workgroup大小等。
我们通过函数clEnqueueNDRangeKerne把Kernel放在一个队列里,但不保证它马上执行,OpenCL driver会管理队列,调度Kernel的执行。注意:每个线程执行的代码都是相同的,但是它们执行数据却是不同的。
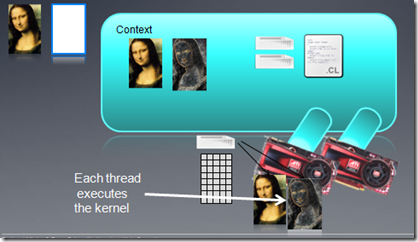


该函数把要执行的Kernel函数放在指定的命令队列中,globald大小(线程索引空间)必须指定,local大小(work group)可以指定,也可以为空。如果为空,则系统会自动根据硬件选择合适的大小。event_wait_list用来选定一些events,只有这些events执行完后,该kernel才可能被执行,也就是通过事件机制来实现不同kernel函数之间的同步。
当Kernel函数执行完毕后,我们要把数据从device memory中拷贝到host memory中去。




释放资源:
大多数的OpenCL资源都是指针,不使用的时候需要释放掉。当然,程序关闭的时候这些对象也会被自动释放掉。
释放资源的函数是:clRelase{Resource} ,比如: clReleaseProgram(), clReleaseMemObject()等。
错误捕捉:
如果OpenCL函数执行失败,会返回一个错误码,一般是个负值,返回0则表示执行成功。我们可以根据该错误码知道什么地方出错了,需要修改。错误码在cl.h中定义,下面是几个错误码的例子.
CL_DEVICE_NOT_FOUND -1
CL_DEVICE_NOT_AVAILABLE -2
CL_COMPILER_NOT_AVAILABLE -3
CL_MEM_OBJECT_ALLOCATION_FAILURE -4
…
下面是一个OpenCL机制的示意图


程序模型
数据并行:work item和内存对象元素之间是一一映射关系;workgroup可以显示指定,也可以隐式指定。
任务并行:kernel的执行独立于线程索引空间;用其他方法表示并行,比如把不同的任务放入队列,用设备指定的特殊的向量类型等等。
同步:workgroup内work item之间的同步;命令队列中不同命令之间的同步。
完整代码如下:
1: #include "stdafx.h" 2: #include <CL/cl.h> 3: #include <stdio.h> 4: #include <stdlib.h> 5: #include <time.h> 6: #include <iostream> 7: #include <fstream> 8: 9: using namespace std; 10: #define NWITEMS 262144 11: 12: #pragma comment (lib,"OpenCL.lib") 13: 14: //把文本文件读入一个string中 15: int convertToString(const char *filename, std::string& s) 16: { 17: size_t size; 18: char* str; 19: 20: std::fstream f(filename, (std::fstream::in | std::fstream::binary)); 21: 22: if(f.is_open()) 23: { 24: size_t fileSize; 25: f.seekg(0, std::fstream::end); 26: size = fileSize = (size_t)f.tellg(); 27: f.seekg(0, std::fstream::beg); 28: 29: str = new char[size+1]; 30: if(!str) 31: { 32: f.close(); 33: return NULL; 34: } 35: 36: f.read(str, fileSize); 37: f.close(); 38: str[size] = '\0'; 39: 40: s = str; 41: delete[] str; 42: return 0; 43: } 44: printf("Error: Failed to open file %s\n", filename); 45: return 1; 46: } 47: 48: int main(int argc, char* argv[]) 49: { 50: //在host内存中创建三个缓冲区 51: float *buf1 = 0; 52: float *buf2 = 0; 53: float *buf = 0; 54: 55: buf1 =(float *)malloc(NWITEMS * sizeof(float)); 56: buf2 =(float *)malloc(NWITEMS * sizeof(float)); 57: buf =(float *)malloc(NWITEMS * sizeof(float)); 58: 59: //初始化buf1和buf2的内容 60: int i; 61: srand( (unsigned)time( NULL ) ); 62: for(i = 0; i < NWITEMS; i++) 63: buf1[i] = rand()%65535; 64: 65: srand( (unsigned)time( NULL ) +1000); 66: for(i = 0; i < NWITEMS; i++) 67: buf2[i] = rand()%65535; 68: 69: for(i = 0; i < NWITEMS; i++) 70: buf[i] = buf1[i] + buf2[i]; 71: 72: cl_uint status; 73: cl_platform_id platform; 74: 75: //创建平台对象 76: status = clGetPlatformIDs( 1, &platform, NULL ); 77: 78: cl_device_id device; 79: 80: //创建GPU设备 81: clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU, 82: 1, 83: &device, 84: NULL); 85: //创建context 86: cl_context context = clCreateContext( NULL, 87: 1, 88: &device, 89: NULL, NULL, NULL); 90: //创建命令队列 91: cl_command_queue queue = clCreateCommandQueue( context, 92: device, 93: CL_QUEUE_PROFILING_ENABLE, NULL ); 94: //创建三个OpenCL内存对象,并把buf1的内容通过隐式拷贝的方式 95: //拷贝到clbuf1,buf2的内容通过显示拷贝的方式拷贝到clbuf2 96: cl_mem clbuf1 = clCreateBuffer(context, 97: CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, 98: NWITEMS*sizeof(cl_float),buf1, 99: NULL ); 100: 101: cl_mem clbuf2 = clCreateBuffer(context, 102: CL_MEM_READ_ONLY , 103: NWITEMS*sizeof(cl_float),NULL, 104: NULL ); 105: 106: status = clEnqueueWriteBuffer(queue, clbuf2, 1, 107: 0, NWITEMS*sizeof(cl_float), buf2, 0, 0, 0); 108: 109: cl_mem buffer = clCreateBuffer( context, 110: CL_MEM_WRITE_ONLY, 111: NWITEMS * sizeof(cl_float), 112: NULL, NULL ); 113: 114: const char * filename = "add.cl"; 115: std::string sourceStr; 116: status = convertToString(filename, sourceStr); 117: const char * source = sourceStr.c_str(); 118: size_t sourceSize[] = { strlen(source) }; 119: 120: //创建程序对象 121: cl_program program = clCreateProgramWithSource( 122: context, 123: 1, 124: &source, 125: sourceSize, 126: NULL); 127: //编译程序对象 128: status = clBuildProgram( program, 1, &device, NULL, NULL, NULL ); 129: if(status != 0) 130: { 131: printf("clBuild failed:%d\n", status); 132: char tbuf[0x10000]; 133: clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf, NULL); 134: printf("\n%s\n", tbuf); 135: return -1; 136: } 137: 138: //创建Kernel对象 139: cl_kernel kernel = clCreateKernel( program, "vecadd", NULL ); 140: //设置Kernel参数 141: cl_int clnum = NWITEMS; 142: clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*) &clbuf1); 143: clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*) &clbuf2); 144: clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*) &buffer); 145: 146: //执行kernel 147: cl_event ev; 148: size_t global_work_size = NWITEMS; 149: clEnqueueNDRangeKernel( queue, 150: kernel, 151: 1, 152: NULL, 153: &global_work_size, 154: NULL, 0, NULL, &ev); 155: clFinish( queue ); 156: 157: //数据拷回host内存 158: cl_float *ptr; 159: ptr = (cl_float *) clEnqueueMapBuffer( queue, 160: buffer, 161: CL_TRUE, 162: CL_MAP_READ, 163: 0, 164: NWITEMS * sizeof(cl_float), 165: 0, NULL, NULL, NULL ); 166: //结果验证,和cpu计算的结果比较 167: if(!memcmp(buf, ptr, NWITEMS)) 168: printf("Verify passed\n"); 169: else printf("verify failed"); 170: 171: if(buf) 172: free(buf); 173: if(buf1) 174: free(buf1); 175: if(buf2) 176: free(buf2); 177: 178: //删除OpenCL资源对象 179: clReleaseMemObject(clbuf1); 180: clReleaseMemObject(clbuf2); 181: clReleaseMemObject(buffer); 182: clReleaseProgram(program); 183: clReleaseCommandQueue(queue); 184: clReleaseContext(context); 185: return 0; 186: } 187: 也可以在http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amdunicourseCode1.zip&can=2&q=#makechanges上下载完整版本。
GPU架构
内容包括:
1.OpenCLspec和多核硬件的对应关系
- AMD GPU架构
- Nvdia GPU架构
- Cell Broadband Engine
2.一些关于OpenCL的特殊主题
- OpenCL编译系统
- Installable client driver
首先我们可能有疑问,既然OpenCL具有平台无关性,我们为什么还要去研究不同厂商的特殊硬件设备呢?
- 了解程序中的循环和数据怎样映射到OpenCL Kernel中,便于我们提高代码质量,获得更高的性能。
- 了解AMD和Nvdia显卡的区别。
- 了解各种硬件的区别,可以帮助我们使用基于这些硬件的一些特殊的OpenCL扩展,这些扩展在后面课程中会讲到。
3、传统的CPU架构


- 对单个线程来说,CPU优化能获得最小时延,而且CPU也适合处理控制流密集的工作,比如if、else或者跳转指令比较多的任务。
- 控制逻辑单元在芯片中占用的面积要比ALU单元多。
- 多层次的cache设计被用来隐藏时延(可以很好的利用空间和时间局部性原理)
- 有限的寄存器数量使得同时active的线程不能太多。
- 控制逻辑单元记录程序的执行、提供指令集并行(ILP)以及最小化CPU管线的空置周期(stalls,在该时钟周期,ALU没做什么事)。
4、现代的GPGPU架构
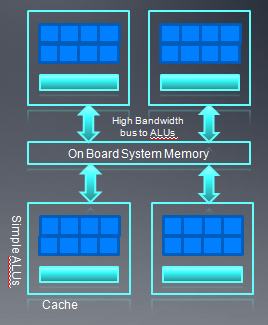
- 对于现代的GPU,通常的它的控制逻辑单元比较简单(和cpu相比),cache也比较小
- 线程切换开销比较小,都是轻量级的线程。
- GPU的每个“核”有大量的ALU以及很小的用户可管理的cache。[这儿的核应该是指整个GPU]。
- 内存总线都是基于带宽优化的。150GB/s的带宽可以使得大量ALU同时进行内存操作。
5、AMD GPU硬件架构
现在我们简单看下AMD 5870显卡(cypress)的架构
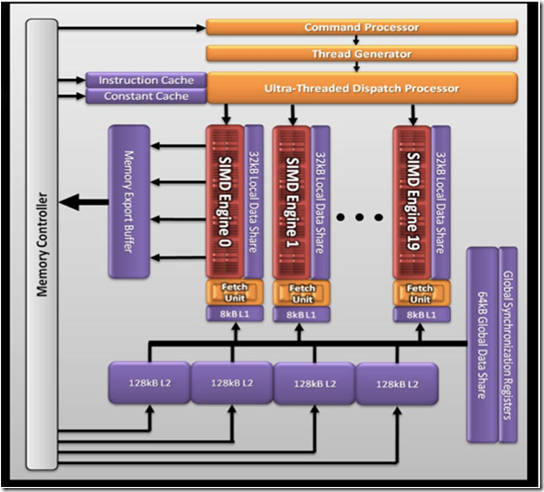
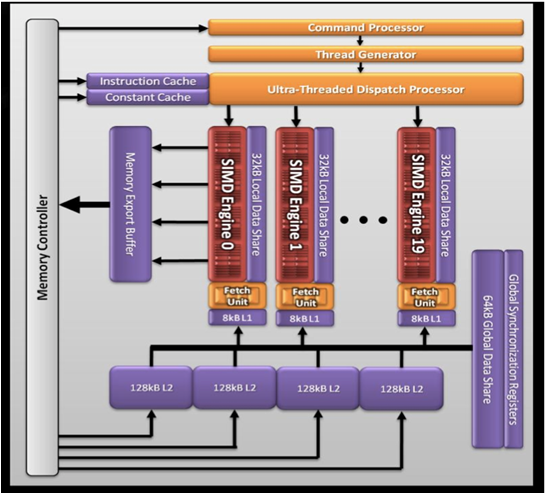
- 20个simd引擎,每个simd引擎包含16个simd。
- 每个simd包含16个stream core
- 每个stream core都是5路的乘法-加法运算单元(VLIW processing)。
- 单精度运算可以达到 Teraflops。
- 双精度运算可以达到544Gb/s
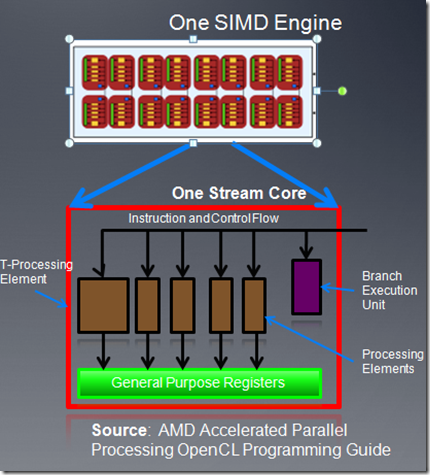
上图为一个simd引擎的示意图,每个simd引擎由一系列的stream core组成。
- 每个stream core是一个5路的VLIW处理器,在一个VLIW指令中,可以最多发射5个标量操作。标量操作在每个pe上执行。
- CU(8xx系列cu对应硬件的simd)内的stream core执行相同的VLIW指令。
- 在CU(或者说simd)内同时执行的work item放在一起称作一个wave,它是cu中同时执行的线程数目。在5870中wave大小是64,也就是说一个cu内,最多有64个work item在同时执行。
注:5路的运算对应(x,y,z,w),以及T(超越函数),在cayman中,已经取消了T,改成四路了。
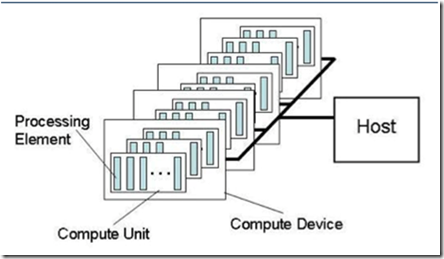
我们现在看下AMD GPU硬件在OpenCL中的对应关系:
- 一个workitme对应一个pe,pe就是单个的VLIW core
- 一个cu对应多个pe,cu就是simd引擎。
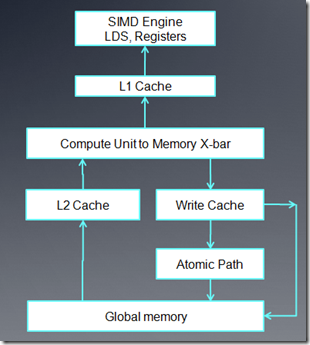
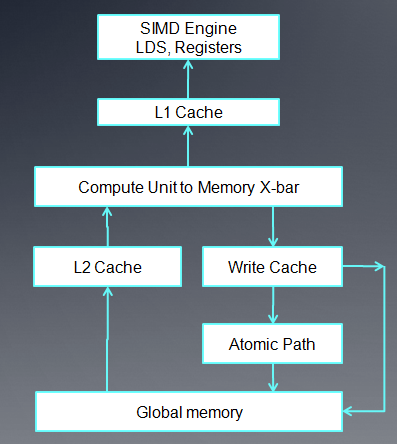
上图是AMD GPU的内存架构(原课件中的图有点小错误,把Global memory写成了LDS)
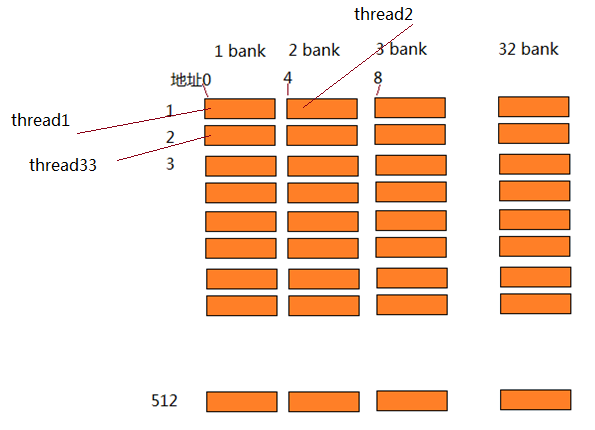
- 对每个cu来说,它使用的内存包括onchip的LDS以及相关寄存器。在5870中,每个LDS是32K,共32个bank,每个bank 1k,读写单位4 byte。
- 对没给cu来说,有8K的L1 cache。(for 5870)
- 各个cu之间共享的L2 cache,在5870中是512K。
- fast Path只能执行32位或32位倍数的内存操作。
- complete path能够执行原子操作以及小于32位的内存操作。
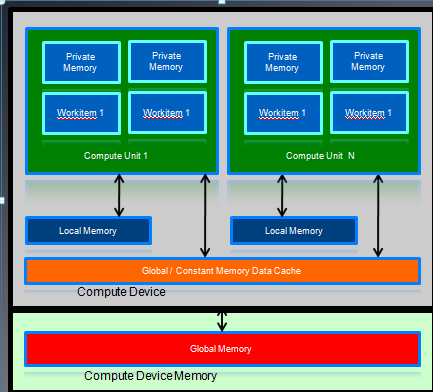
AMD GPU的内存架构和OpenCL内存模型之间的对应关系:
- LDS对应local memeory,主要用来在一个work group内的work times之间共享数据。steam core访问LDS的速度要比Global memory快一个数量级。
- private memory对应每个pe的寄存器。
- constant memory主要是利用了L1 cache
注意:对AMD CPU,constant memory的访问包括三种方式:Direct-Addressing Patterns,这种模式要求不包括行列式,它的值都是在kernel函数初始化的时候就决定了,比如传入一个固定的参数。Same Index Patterns,所有的work item都访问相同的索引地址。Globally scoped constant arrays,行列式会被初始化,如果小于16K,会使用L1 cache,从而加快访问速度。
当所有的work item访问不同的索引地址时候,不能被cache,这时要在global memory中读取。
6、Nvdia GPU Femi架构


GTX480-Compute 2.0 capability:
- 有15个core或者说SM(Streaming Multiprocessors )。
- 每个SM,一般有32 cuda处理器。
- 共480个cuda处理器。
- 带ECC的global memory
- 每个SM内的线程按32个单位调度执行,称作warp。每个SM内有2个warp发射单元。
- 一个cuda核由一个ALU和一个FPU组成,FPU是浮点处理单元。
SIMT和SIMD
SIMT是指单指令、多线程。
- 硬件决定了多个ALU之间要共享指令。
- 通过预测来处理多个线程间的Diverage(是指同一个warp中的指令执行路径产生不同)。
- NV把一个warp中执行的指令当作一个SIMT。SIMT指令指定了一个线程的执行以及分支行为。
SIMD指令可以得到向量的宽度,这点和X86 SSE向量指令比较类似。
SIMD的执行和管线相关
- 所有的ALU执行相同的指令。
- 根据指令可以管线分为不同的阶段。当第一条指令完成的时候(4个周期),下条指令开始执行。
Nvida GPU内存机制:
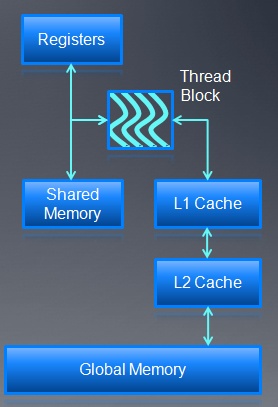
- 每个SM都有L1 cache,通过配置,它可以支持shared memory,也可以支持global memory。
- 48 KB Shared / 16 KB of L1 cache,16 KB Shared / 48 KB of L1 cache
- work item之间数据共享通过shared memory
- 每个SM有32K的register bank
- L2(768K)支持所有的操作,比如load,store等等
- Unified path to global for loads and stores

和AMD GPU类似,Nv的GPU 内存模型和OpenCL内存模型的对应关系是:
- shared memory对应local memory
- 寄存器对应private memory
7、Cell Broadband Engine
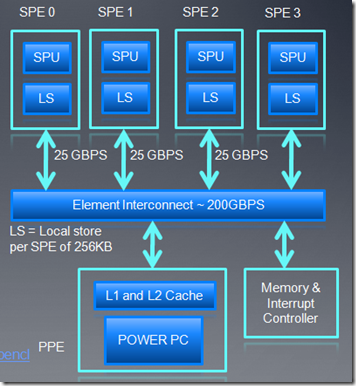
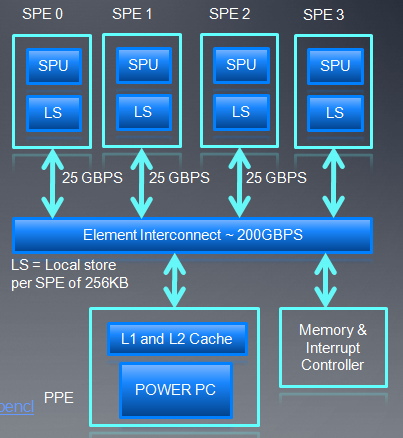
由索尼,东芝,IBM等联合开发,可用于嵌入式平台,也可用于高性能计算(SP3次世代游戏主机就用了cell处理器)。
- Bladecenter servers提供OpenCL driver支持
- 如图所示,cell处理器由一个Power Processing Element (PPE) 和多个Synergistic Processing Elements (SPE)组成。
- Uses the IBM XL C for OpenCL compiler 11
- Cell Power/VMX CPU 的设备类型是CL_DEVICE_TYPE_CPU,Cell SPU 的设备类型是CL_DEVICE_TYPE_ACCELERATOR。
- OpenCL Accelerator设备和CPU共享内存总线。
- 提供一些扩展,比如Device Fission、Migrate Objects来指定一个OpenCL对象驻留在什么位置。
- 不支持OpenCL image对象,原子操作,sampler对象以及字节内存地址。
8、OpenCL编译系统

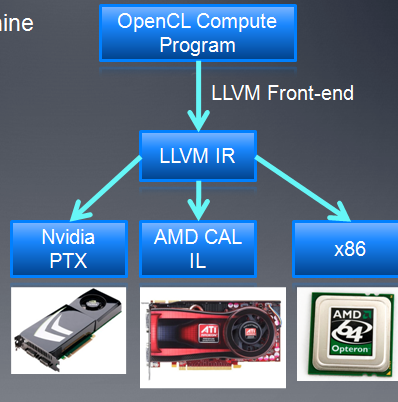
- LLVM-底层的虚拟机
- Kernel首先在front-end被编译成LLVM IR
- LLVM是一个开源的编译器,具有平台独立性,可以支持不同厂商的back_end编译,网址:http://llvm.org
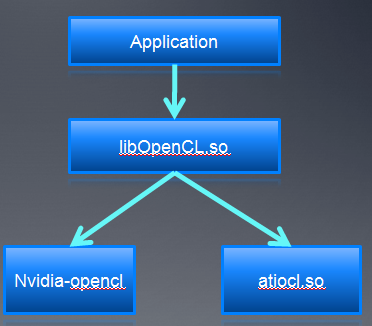
9、Installable Client Driver
- ICD支持不同厂商的OpenCL实施在系统中共存。
- 代码紧被链接接到libOpenCL.so
- 应用程序可在运行时选择不同的OpenCL实施(就是选择不同platform)
- 现在的GPU驱动还不支持跨厂商的多个GPU设备同时工作。
- 通过clGetPlatformIDs() 和clGetPlatformInfo() 来检测不同厂商的OpenCL平台。
本节主要讲述GPU的memory架构。优化基于GPU device的kernel程序时,我们需要了解很多GPU的memory知识,比如内存合并,bank conflit(冲突)等等,这样才能针对具体算法做一些优化工作。
1、GPU总线寻址介绍
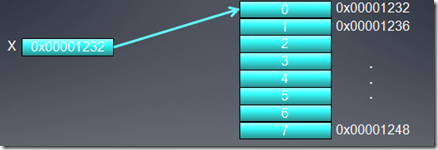

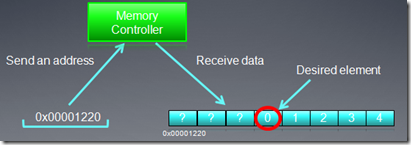
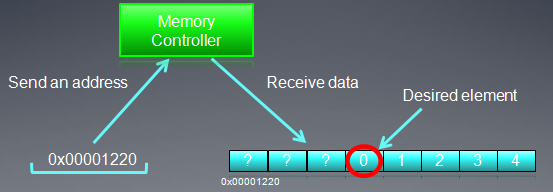
假定X是一个指向整数(32位整数)数组的指针,数组的首地址为0x00001232。一个线程要访问元素X[0],
int tmp = X[0];
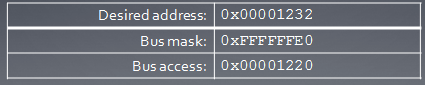
假定memory总线宽度为256位(HD5870就是如此,即为32字节),因为基于字节地址的总线要访问memeory,必须和总线宽度对齐,也就是说按必须32字节对齐来访问memory,比如访问0x00000000,0x00000020,0x00000040,…等,所以我们要得到地址0x00001232中的数据,比如访问地址0x00001220,这时,它会同时得到0x00001220到 0x0000123F 的所有数据。因为我们只是取的一个32位整数,所以有用的数据是4个字节,其它28的字节的数据都被浪费了,白白消耗了带宽。
2、合并内存访问
为了利用总线带宽,GPU通常把多个线程的内存访问尽量合并到较少的内存请求命令中去。
假定下面的OpenCL kernel代码:int tmp = X[get_global_id(0)];
数组X的首地址和前面例子一样,也是0x00001232,则前16个线程将访问地址:0x00001232 到 0x00001272。假设每个memory访问请求都单独发送的话,则有16个request,有用的数据只有64字节,浪费掉了448字节(16*28)。
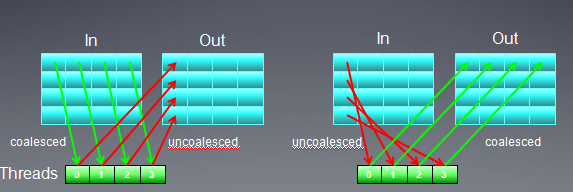
假定多个线程访问32个字节以内的地址,它们的访问可以通过一个memory request完成,这样可以大大提高带宽利用率,在专业术语描述中这样的合并访问称作coalescing。
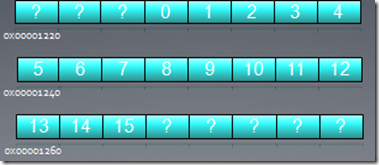
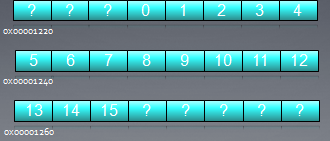
例如上面16个线程访问地址0x00001232 到 0x00001272,我们只需要3次memory requst。
在HD5870显卡中,一个wave中16个连续线程的内存访问会被合并,称作quarter-wavefront,是重要的硬件调度单位。
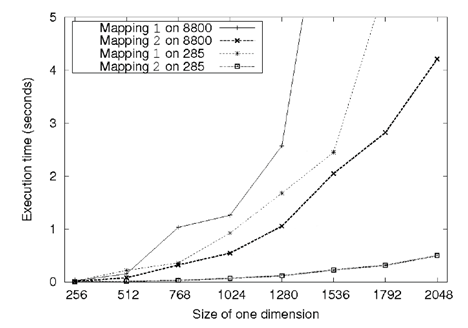
下面的图是HD5870中,使用memory访问合并以及没有使用合并的bandwidth比较:

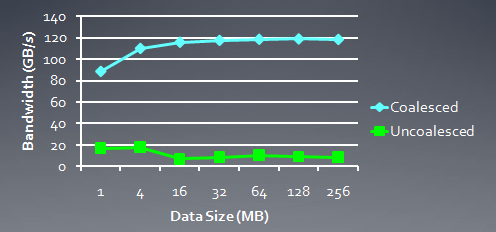
下图是GTX285中的比较:

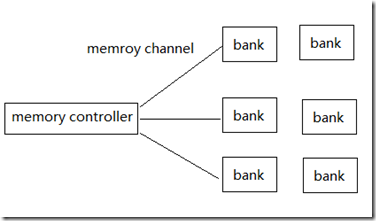
3、Global memory的bank以及channel访问冲突
我们知道内存由bank,channel组成,bank是实际存储数据的单元,一个mc可以连接多个channel,形成单mc,多channel的连接方式。在物理上,不同bank的数据可以同时访问,相同的bank的数据则必须串行访问,channel也是同样的道理。但由于合并访问的缘故,对于global memory来说,bank conflit影响要小很多,除非是非合并问,不同线程访问同一个bank。理想情况下,我们应该做到不同的workgroup访问的不同的bank,同一个group内,最好用合并操作。
下面我简单的画一个图,不知道是否准确,仅供参考:


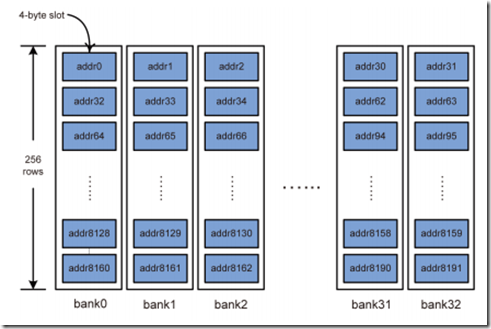
在HD5870中,memory地址的低8位表示一个bank中的数据,接下来的3位表示channel(共8个channel),bank位的多少依赖于显存中bank的多少。
4、local memory的bank conflit
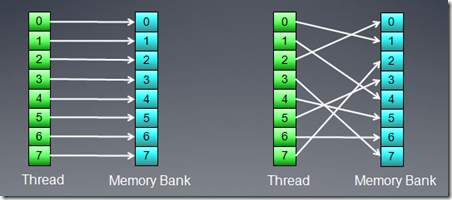
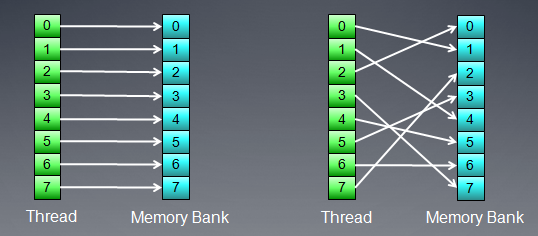
bank访问冲突对local memory操作有更大的影响(相比于global memory),连续的local memory访问地址,应该映射到不同的bank上,
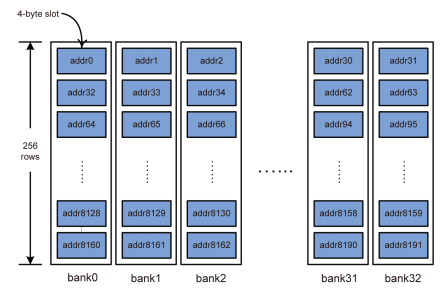
在AMD显卡中,一个产生bank访问冲突wave将会等待所有的local memory访问完成,硬件不能通过切换到另一个wave来隐藏local memory访问时延。所以对local memory访问的优化就很重要。HD5870显卡中,每个cu(simd)有32bank,每个bank 1k,按4字节对齐访问。如果没有bank conflit,每个bank能够没有延时的返回一个数据,下面的图就是这种情况。
如果多个memory访问对应到一个bank上,则conflits的数量决定时延的大小。下面的访问方式将会有3倍的时延。
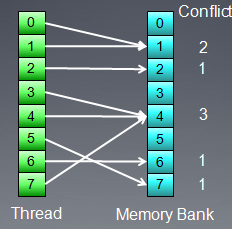
但是,如果所有访问都映射到一个bank上,则系统会广播数据访问,不会产生额外时延。

GPU线程及调度
本节主要讲述OpenCL中的Workgroup如何在硬件设备中被调度执行。同时也会讲一下同一个workgroup中的workitem,如果它们执行的指令发生diverage(就是执行指令不一致)对性能的影响。学习OpenCL并行编程,不仅仅是对OpenCL Spec本身了解,更重要的是了解OpenCL硬件设备的特性,现阶段来说,主要是了解GPU的的架构特性,这样才能针对硬件特性优化算法。
现在OpenCL的Spec是1.1,随着硬件的发展,相信OpenCL会支持更多的并行计算特性。基于OpenCL的并行计算才刚刚起步,…
1、workgroup到硬件线程
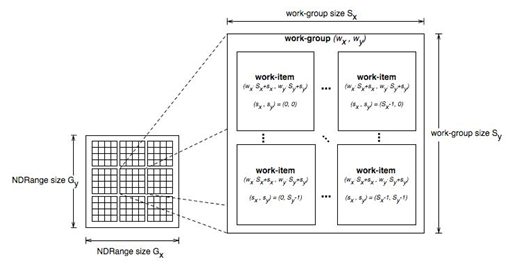
在OpenCL中,Kernel函数被workgroup中的workitem(线程,我可能混用这两个概念)执行。在硬件层次,workgroup被映射到硬件的cu(compute unit)单元来执行具体计算,而cu一般由更多的SIMT(单指令,线程)pe(processing elements)组成。这些pe执行具体的workitem计算,它们执行同样的指令,但操作的数据不一样,用simd的方式完成最终的计算。
由于硬件的限制,比如cu中pe数量的限制,实际上workgroup中线程并不是同时执行的,而是有一个调度单位,同一个workgroup中的线程,按照调度单位分组,然后一组一组调度硬件上去执行。这个调度单位在nv的硬件上称作warp,在AMD的硬件上称作wavefront,或者简称为wave。


上图显示了workgroup中,线程被划分为不同wave的分组情况。wave中的线程同步执行相同的指令,但每个线程都有自己的register状态,可以执行不同的控制分支。比如一个控制语句
if(A)
{
… //分支A
}
else
{
… //分支B
}
假设wave中的64个线程中,奇数线程执行分支A,偶数线程执行分支B,由于wave中的线程必须执行相同的指令,所以这条控制语句被拆分为两次执行[编译阶段进行了分支预测],第一次分支A的奇数线程执行,偶数线程进行空操作,第二次偶数线程执行,奇数线程空操作。硬件系统有一个64位mask寄存器,第一次是它为01…0101,第二次会进行反转操作10…1010,根据mask寄存器的置位情况,来选择执行不同的线程。可见对于分支多的kernel函数,如果不同线程的执行发生diverage的情况太多,会影响程序的性能。
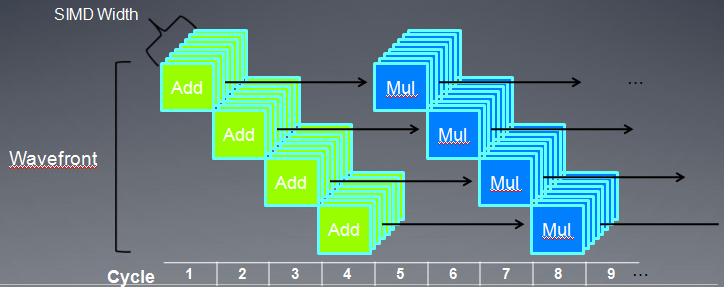
2、AMD wave调度
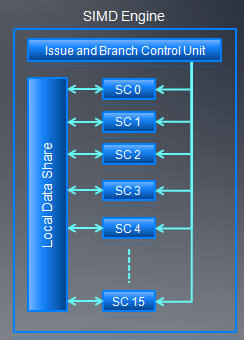
AMD GPU的线程调度单位是wave,每个wave的大小是64。指令发射单元发射5路的VLIW指令,每个stream core(SC)执行一条VLIW指令,16个stream core在一个时钟周期执行16条VLIW指令。每个时钟周期,1/4wave被完成,整个wave完成需要四个连续的时钟周期。
另外还有以下几点值得我们了解:
- 发生RAW hazard情况下,整个wave必须stall 4个时钟周期,这时,如果其它的wave可以利用,ALU会执行其它的wave以便隐藏时延,8个时钟周期后,如果先前等待wave已经准备好了,ALU会继续执行这个wave。
- 两个wave能够完全隐藏RAW时延。第一个wave执行时候,第二个wave在调度等待数据,第一个wave执行完时,第二个wave可以立即开始执行。
3、nv warp调度
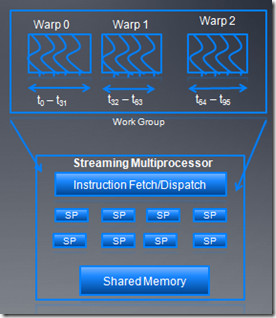
work group以32个线程为单位,分成不同warp,这些warp被SM调度执行。每次warp中一半的线程被发射执行,而且这些线程能够交错执行。可以用的warp数量依赖于每个block的资源情况。除了大小不一样外,wave和warp在硬件特性上很相似。
4、Occupancy开销
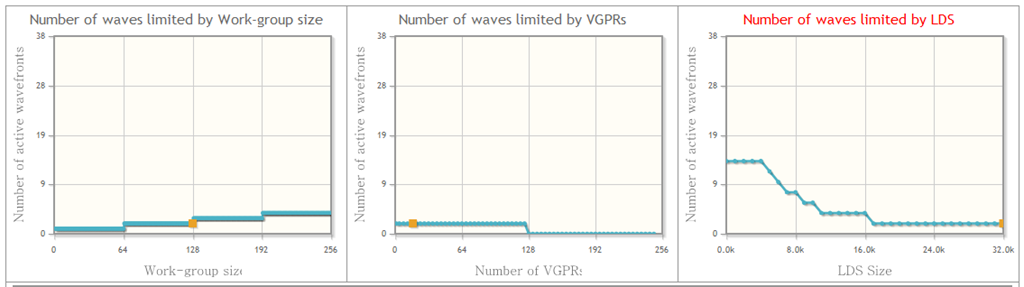
在每个cu中,同时激活的wave数量是受限制的,这和每个线程使用register和local memory大小有关,因为对于每个cu,register和local memory总量是一定的。
我们用术语Occupancy来衡量一个cu中active wave的数量。如果同时激活的wave越多,能更好的隐藏时延,在后面性能优化的章节中,我们还会更具体讨论Occupancy。
5、控制流和分支预测(prediction)
前面我说了if else的分支执行情况,当一个wave中不同线程出现diverage的时候,会通过mask来控制线程的执行路径。这种预测(prediction)的方式基于下面的考虑:
- 分支的代码都比较短
- 这种prediction的方式比条件指令更高效。
- 在编译阶段,编译器能够用predition替换switch或者if else。
prediction 可以定义为:根据判断条件,条件码被设置为true或者false。
__kernel
void test() {
int tid= get_local_id(0) ;
if( tid %2 == 0)
Do_Some_Work() ;
else
Do_Other_Work() ;
}例如上面的代码就是可预测的,
Predicate = True for threads 0,2,4….
Predicate = False for threads 1,3,5….
下面在看一个控制流diverage的例子
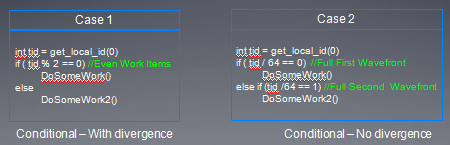
- 在case1中,所有奇数线程执行DoSomeWork2(),所有偶数线程执行DoSomeWorks,但是在每个wave中,if和else代码指令都要被发射。
- 在case2中,第一个wave执行if,其它的wave执行else,这种情况下,每个wave中,if和else代码只被发射一个。
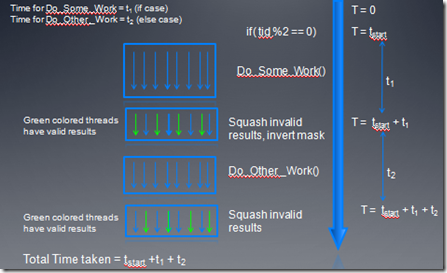

在prediction下,指令执行时间是if,else两个代码快执行时间之和。
6、Warp voting
warp voting是一个warp内的线程之间隐式同步的机制。
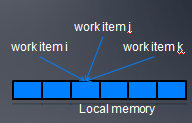
比如一个warp内线程同时写Local meory某个地址,在线程并发执行时候,warp voting机制可以保证它们的前后顺序正确。更详细的warp voting大家可以参考cuda的资料。
在OpenCL编程中,由于各种硬件设备不同,导致我们必须针对不同的硬件进行优化,这也是OpenCL编程的一个挑战,比如warp和wave数量的不同,使得我们在设计workgroup大小时候,必须针对自己的平台进行优化,如果选择32,对于AMD GPU,可能一个wave中32线程是空操作,而如果选择64,对nv GPU来说,可能会出现资源竞争的情况加剧,比如register以及local meomory的分配等等。这儿还不说混合CPU device的情况,OpenCL并行编程的道路还很漫长,期待新的OpenCL架构的出现。
性能优化
1、线程映射
所谓线程映射是指某个线程访问哪一部分数据,其实就是线程id和访问数据之间的对应关系。
合适的线程映射可以充分利用硬件特性,从而提高程序的性能,反之,则会降低performance。
请参考Static Memory Access Pattern Analysis on a Massively Parallel GPU这篇paper,文中讲述线程如何在算法中充分利用线程映射。这是我在google中搜索到的下载地址:http://www.ece.neu.edu/~bjang/patternAnalysis.pdf
使用不同的线程映射,同一个线程可能访问不同位置的数据。下面是几个线程映射的例子:

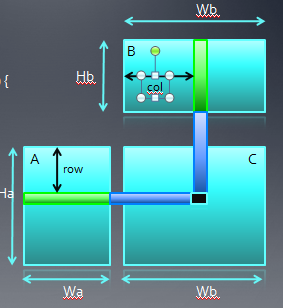
我们考虑一个简单的串行矩阵乘法:这个算法比较适合输出数据降维操作,通过创建N*M个线程,我们移去两层外循环,这样每个线程执行P个加法乘法操作。现在需要我们考虑的问题是,线程索引空间究竟应该是M*N还是N*M?
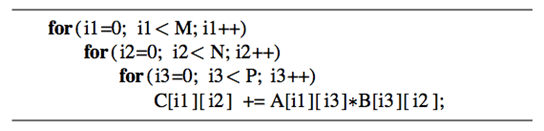
当我们使用M*N线程索引空间时候,Kernel如下图所示:

而使用N*M线程索引空间时候,Kernel如下图所示:
使用两种映射关系,程序执行结果是一样的。下面是在nv的卡GeForce 285 and 8800 GPUs上的执行结果。可以看到映射2(及N*M线程索引空间),程序的performance更高。
performance差异主要是因为在两种映射方式下,对global memory访问的方式有所不同。在行主序的buffer中,数据都是按行逐个存储,为了保证合并访问,我们应该把一个wave中连续的线程映射到矩阵的列(第二维),这样在A*B=C的情况下,会把矩阵B和C的内存读写实现合并访问,而两种映射方式对A没有影响(A又i3决定顺序)。
完整的源代码请从:http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amduniCourseCode4.zip&can=2&q=#makechanges下载,程序中我实现了两种方式的比较。结果确实第二种方式要快一些。
下面我们再看一个矩阵转置的例子,在例子中,通过改变映射方式,提高了global memory访问的效率。

矩阵转置的公式是:Out(x,y) = In(y,x)
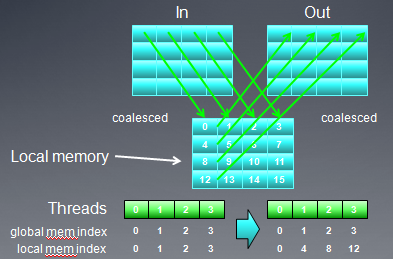
从上图可以看出,无论才去那种映射方式,总有一个buffer是非合并访问方式(注:在矩阵转置时,必须要把输入矩阵的某个元素拷贝到临时位置,比如寄存器,然后才能拷贝到输出矩阵)。我们可以改变线程映射方式,用local memory作为中间元素,从而实现输入,输出矩阵都是global memory合并访问。

下面是AMD 5870显卡上,两种线程映射方式实现的矩阵转置性能比较:
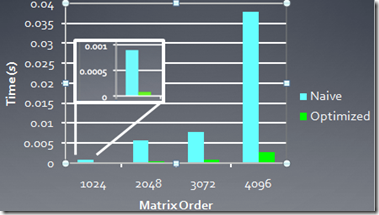
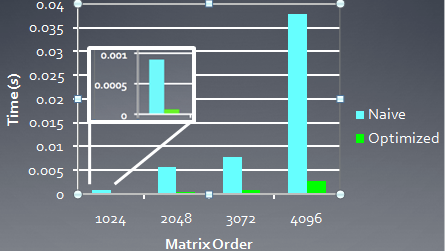
2、Occupancy
前面的教程中,我们提到过Occupancy的概念,它主要用来描述CU中资源的利用率。
OpenCL中workgroup被映射到硬件的CU中执行,在一个workgroup中的所有线程执行完之后,这个workgroup才算执行结束。对一个特定的cu来说,它的资源(比如寄存器数量,local memory大小,最大线程数量等)是固定的,这些资源都会限制cu中同时处于调度状态的workgroup数量。如果cu中的资源数量足够的的话,映射到同一个cu的多个workgroup能同时处于调度状态,其中一个workgroup的wave处于执行状态,当处于执行状态的workgroup所有wave因为等待资源而切换到等待状态的话,不同workgroup能够从就绪状态切换到ALU执行,这样隐藏memory访问时延。这有点类似操作系统中进程之间的调度状态。我简单画个图,以供参考:

- 对于一个比较长的kernel,寄存器是主要的资源瓶颈。假设kernel需要的最大寄存器数目为35,则workgroup中的所有线程都会使用35个寄存器,而一个CU(假设为5870)的最大寄存器数目为16384,则cu中最多可有16384/35=468线程,此时,一个workgroup中的线程数目(workitem)不可能超过468,
- 考虑另一个问题,一个cu共16384个寄存器,而workgroup固定为256个线程,则使用的寄存器数量可达到64个。
每个CU的local memory也是有限的,对于AMD HD 5XXX显卡,local memory是32K,NV的显卡local memory是32-48K(具体看型号)。和使用寄存器的情况相似,如果kernel使用过多的local memory,则workgroup中的线程数目也会有限制。
GPU硬件还有一个CU内的最大线程数目限制:AMD显卡256,nv显卡512。
NV的显卡对于每个CU内的激活线程有数量限制,每个cu 8个或16个warp,768或者1024个线程。
AMD显卡对每个CU内的wave数量有限制,对于5870,最多496个wave。
这些限制都是因为有限的资源竞争引起的,在nv cuda中,可以通过可视化的方式查看资源的限制情况。
3、向量化
向量化允许一个线程同时执行多个操作。我们可以在kernel代码中,使用向量数据类型,比如float4来获得加速。向量化在AMD的GPU上效果更为明显,这是因为AMD的显卡的stream core是(x,y,z,w)这样的向量运算单元。
下图是在简单的向量赋值运算中,使用float和float4的性能比较。

kernel代码为:

posted on 2012-01-31 19:26 迈克老狼2012 阅读(881) 评论(3)编辑 收藏
评论
#2楼
这句话每次读都不顺口,实际是这样的,比如B【4】【4】,存的时候是B[0][0],B[0][1],B[0][2]...这样存储的,在每一行中是按照第二维递增的,也就是按列递增,存完第一行然后存的第二行。因此应该把一个wave中连续的线程映射到矩阵的列。Opencl线程是以(0,0),(1,0)(2,0)...这样变换的,也就是先是get_global_id(0)变换,然后是get_global_id(1)变换,因此将get_global_id(0)对应到列。
#3楼
本节主要介绍NBody算法的OpenCL性能优化。
1、NBody
NBody系统主要用来通过粒子之间的物理作用力来模拟星系系统。每个粒子表示一个星星,多个粒子之间的相互作用,就呈现出星系的效果。
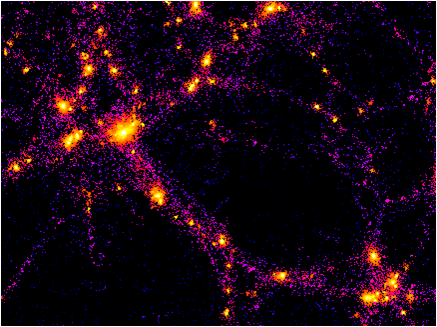
上图为一个粒子模拟星系的图片:Source: THE GALAXY-CLUSTER-SUPERCLUSTER CONNECTION,http://www.casca.ca/ecass/issues/1997-DS/West/west-bil.html
由于每个粒子之间都有相互作用的引力,所以这个算法的复杂度是N2的。下面我们主要探讨如何优化算法以及在OpenCL基础上优化算法。
2、NBody算法
假设两个粒子之间通过万有引力相互作用,则任意两个粒子之间的相互作用力F公式如下:

最笨的方法就是计算每个粒子和其它粒子的作用力之和,这个方法通常称作N-Pair的NBody模拟。
粒子之间的万有引力和它们之间的距离成反比,对于一个粒子而言(假设粒子质量都一样),远距离粒子的作用力有时候很小,甚至可以忽略。Barnes Hut 把3D空间按八叉树进行分割,只有在相邻cell的粒子才直接计算它们之间的引力,远距离cell中的粒子当作一个整体来计算引力。

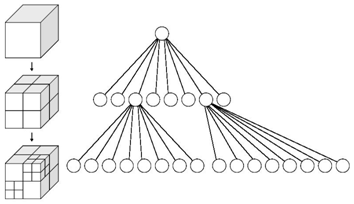
3、OpenCL优化Nbody
在本节中,我们不考虑算法本身的优化,只是通过OpenCL机制来优化N-Pair的NBody模拟。
最简单的实施方法就是每个例子的作用力相加,代码如下:
for(i=0; i<n; i++)
{
ax = ay = az = 0;
// Loop over all particles "j”
for (j=0; j<n; j++) {
//Calculate Displacement
dx=x[j]-x[i];
dy=y[j]-y[i];
dz=z[j]-z[i];
// small eps is delta added for dx,dy,dz = 0
invr= 1.0/sqrt(dx*dx+dy*dy+dz*dz +eps);
invr3 = invr*invr*invr;
f=m[ j ]*invr3;
// Accumulate acceleration
ax += f*dx;
ay += f*dy;
az += f*dx;
}
// Use ax, ay, az to update particle positions
}
我们对每个粒子计算作用在它上面的合力,然后求在合力作用下,delta时间内粒子的新位置,并把这个新位置当作下次计算的输入参数。
没有优化的OpenCL kernel代码如下:
__kernel void nbody_sim_notile(
__global float4* pos ,
__global float4* vel,
int numBodies,
float deltaTime,
float epsSqr,
__local float4* localPos,
__global float4* newPosition,
__global float4* newVelocity)
{
unsigned int tid = get_local_id(0);
unsigned int gid = get_global_id(0);
unsigned int localSize = get_local_size(0);
// position of this work-item
float4 myPos = pos[gid];
float4 acc = (float4)(0.0f, 0.0f, 0.0f, 0.0f);
// load one tile into local memory
int idx = tid * localSize + tid;
localPos[tid] = pos[idx];
// calculate acceleration effect due to each body
// a[i->j] = m[j] * r[i->j] / (r^2 + epsSqr)^(3/2)
for(int j = 0; j < numBodies; ++j)
{
// Calculate acceleartion caused by particle j on particle i
localPos[tid] = pos[j];
float4 r = localPos[j] - myPos;
float distSqr = r.x * r.x + r.y * r.y + r.z * r.z;
float invDist = 1.0f / sqrt(distSqr + epsSqr);
float invDistCube = invDist * invDist * invDist;
float s = localPos[j].w * invDistCube;
// accumulate effect of all particles
acc += s * r;
}
float4 oldVel = vel[gid];
// updated position and velocity
float4 newPos = myPos + oldVel * deltaTime + acc * 0.5f * deltaTime * deltaTime;
newPos.w = myPos.w;
float4 newVel = oldVel + acc * deltaTime;
// write to global memory
newPosition[gid] = newPos;
newVelocity[gid] = newVel;
}
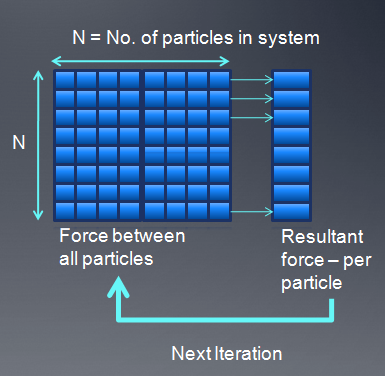
在这种实现中,每次都要从global memory中读取其它粒子的位置,速度,内存访问= N reads*N threads=N2
我们可以通过local memory进行优化,一个粒子数据读进来以后,可以被p*p个线程共用,p*p即为workgroup的大小,对于每个粒子,我们通过迭代p*p的tile,累积得到最终结果。
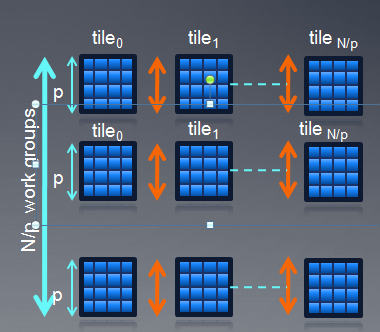
优化后的kernel代码如下:
__kernel void nbody_sim(
__global float4* pos ,
__global float4* vel,
int numBodies,
float deltaTime,
float epsSqr,
__local float4* localPos,
__global float4* newPosition,
__global float4* newVelocity)
{
unsigned int tid = get_local_id(0);
unsigned int gid = get_global_id(0);
unsigned int localSize = get_local_size(0);
// Number of tiles we need to iterate
unsigned int numTiles = numBodies / localSize;
// position of this work-item
float4 myPos = pos[gid];
float4 acc = (float4)(0.0f, 0.0f, 0.0f, 0.0f);
for(int i = 0; i < numTiles; ++i)
{
// load one tile into local memory
int idx = i * localSize + tid;
localPos[tid] = pos[idx];
// Synchronize to make sure data is available for processing
barrier(CLK_LOCAL_MEM_FENCE);
// calculate acceleration effect due to each body
// a[i->j] = m[j] * r[i->j] / (r^2 + epsSqr)^(3/2)
for(int j = 0; j < localSize; ++j)
{
// Calculate acceleartion caused by particle j on particle i
float4 r = localPos[j] - myPos;
float distSqr = r.x * r.x + r.y * r.y + r.z * r.z;
float invDist = 1.0f / sqrt(distSqr + epsSqr);
float invDistCube = invDist * invDist * invDist;
float s = localPos[j].w * invDistCube;
// accumulate effect of all particles
acc += s * r;
}
// Synchronize so that next tile can be loaded
barrier(CLK_LOCAL_MEM_FENCE);
}
float4 oldVel = vel[gid];
// updated position and velocity
float4 newPos = myPos + oldVel * deltaTime + acc * 0.5f * deltaTime * deltaTime;
newPos.w = myPos.w;
float4 newVel = oldVel + acc * deltaTime;
// write to global memory
newPosition[gid] = newPos;
newVelocity[gid] = newVel;
}下面是在AMD, NV两个平台上性能测试结果:
AMD GPU = 5870 Stream SDK 2.2
Nvidia GPU = GTX 480 with CUDA 3.1
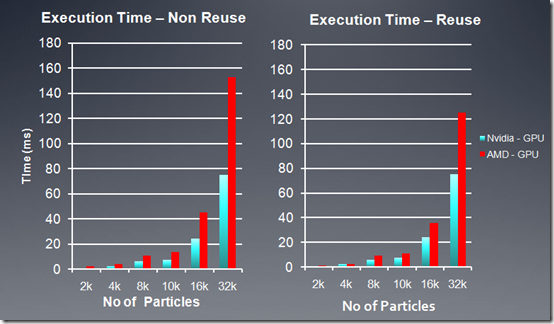
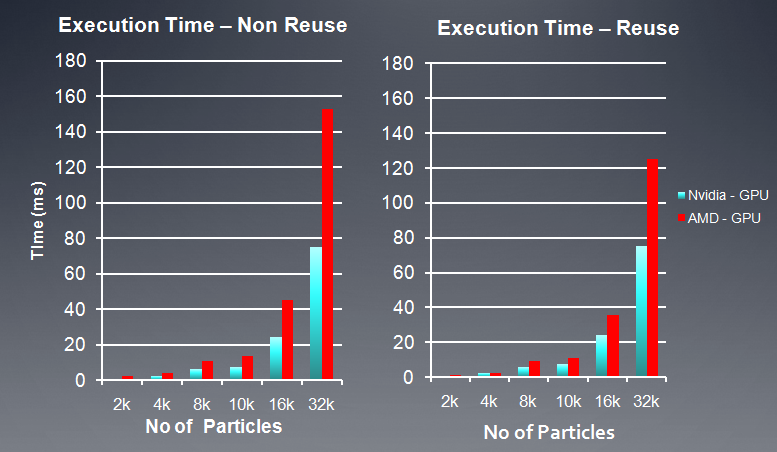
另外,在程序中,也尝试了循环展开,通过展开内循环,从而减少GPU执行分支指令,我的测试中,使用展开四次,得到的FPS比没展开前快了30%。(AMD 5670显卡)。具体实现可以看kernel代码中的__kernel void nbody_sim_unroll函数。在AMD平台上,使用向量化也可以提高10%左右的性能。
最后提供2篇NBody优化的文章:
—Nvidia GPU Gems
—http://http.developer.nvidia.com/GPUGems3/gpugems3_ch31.html
—Brown Deer Technology
—http://www.browndeertechnology.com/docs/BDT_OpenCL_Tutorial_NBody.html
第二个可能地址需要fan墙。
完整的代码可从:http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amduniCourseCode7.zip&can=2&q=#makechanges 下载。
1、OpenCL扩展
OpenCL扩展是指device支持某种特性,但这中特性并不是OpenCL标准的一部分。通过扩展,厂商可以给device增加一些新的功能,而不用考虑兼容性问题。现在各个厂商在OpenCL的实现中或多或少的使用了自己的扩展。
扩展的类型分为三种:
- Khronos OpenCL工作组批准的扩展,这种要经过一致性测试,可能会被增加到新版本的OpenCL规范中。这种扩展都以cl_khr作为扩展名。
- 外部扩展, 以cl_ext为扩展名。这种扩展是由2个或2个以上的厂商发起,并不需要进行一致性测试。比如cl_ext_device_fission扩展。
- 某个厂商自己的扩展,比如AMD的扩展printf
2、使用扩展
OpenCL中,要使用扩展,我们必须打开扩展,在默认状态下,所有的扩展都是禁止的。
#pragma OPENCL EXTENSION extension_name : enable
对于OpenCL,一个函数只有在运行时,才知道其是否可用,所以要确定某个扩展是否可用,是程序员的责任,我们必须在使用前查询它的状态。下面是查询扩展是否可用的代码:
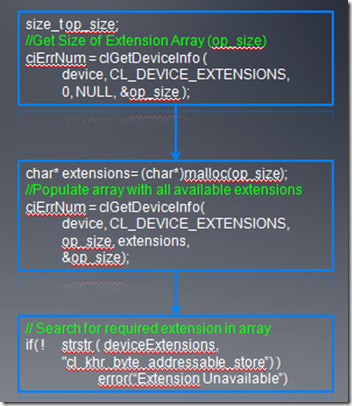

3、一些Khronos批准的扩展
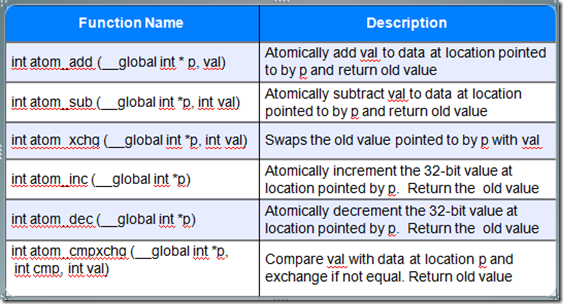
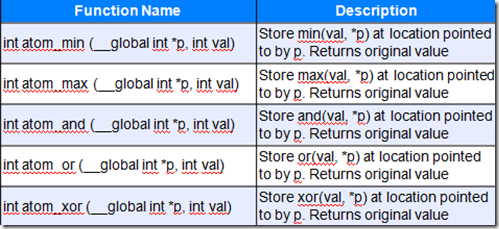
原子操作,它可以保证函数只在一个device上实施原子操作,比如:
—cl_khr_{global | local}_int32_base_atomics
—cl_khr_{global | local}_int32_extended_atomics
—cl_khr_int64_base_atomics
—cl_khr_int64_extended_atomics
注意:原子操作能够保证操作结果正确,但不保证操作的顺序。


双精度和half精度扩展cl_khr_fp64,在一些物理模拟或者科学计算中,需要双精度支持。AMD的64位扩展用cl_amd_fp64,对于cl_khr_fp64是部分支持,NV支持cl_khr_fp64扩展。但half精度扩展cl_khr_fp16,这两家厂商现在都还不支持。
在OpenCL中,Byte addressable store 也是一个扩展,对于sub 32的写,比如char,需要该扩展的支持。例如AMD 直方图的例子中,每个bin用一个byte来存储。
3D Image Write Extensions,在OpenCL标准中,支持2D图像的读写,3D图形的写就需要通过扩展来操作。
The extension cl_KHR_gl_sharing 允许应用程序使用OpenGL buffer,纹理等。
4、AMD扩展
cl_ext_device_fission扩展,通过该扩展把一个设备分成多个子设备,每一个设备都有自己的队列,主要是多核cpu以及Cell Broadband Engine使用,该扩展由AMD,Apple,Intel以及IBM四家联合提出。
fission设备可能的用途包括:
- 保留一部分设备处理高优先级、低时延的任务。
- Control for the assignment of work to individual compute units
- Subdivide compute devices along some shared hardware feature like a cache
对于每个子设备,都有自己的queue,比如下面的图中,我们把不同任务发送到两个子设备。值得注意的是:要把设备拆分为子设备,首先我们要了解该设备的架构,然后根据任务及device架构进行拆分。


GPU printf 扩展,主要用来debug kernel代码。cl_amd_media_ops扩展,主要用于一些多媒体操作。The AMD device query extension 主要用于查询和事件处理。
5、NV扩展
- Compiler Options
- Interoperability Extensions
- Device Query Extension
6、Cell Broadband Engine Extensions
cell处理器用的不多,就不详细说了,使用的人可以查询其相关手册。
, 在本节,我们主要介绍OpenCL中buffer的使用,同时提供了2个完整的例子,一个是图像的旋转,一个是矩阵乘法(非常简单,没有分块优化)。
1、创建OpenCL设备缓冲(buffer)
OpenCL设备使用的数据都存放在设备的buffer中[其实就是device memory中]。我们用下面的代码创建buffer对象:
cl_mem bufferobj = clCreateBuffer (
cl_context context, //Context name
cl_mem_flags flags, //Memory flags
size_t size, //Memory size allocated in buffer
void *host_ptr, //Host data
cl_int *errcode) //Returned error code如果host_ptr指向一个有效的host指针,则创建一个buffer对象的同时会实现隐式的数据拷贝(会在kernel函数进入队列时候,把host_prt中的数据从host memory拷贝到设备内存对象bufferobj中)。
我们可以通过flags参数指定buffer对象的属性。

函数clEnqueueWriteBuffer()用来实现显示的数据拷贝,即把host memory中的数据拷贝到device meomory中。
cl_int clEnqueueWriteBuffer (
cl_command_queue queue, //Command queue to device
cl_mem buffer, //OpenCL Buffer Object
cl_bool blocking_read, //Blocking/Non-Blocking Flag
size_t offset, //Offset into buffer to write to
size_t cb, //Size of data
void *ptr, //Host pointer
cl_uint num_in_wait_list, //Number of events in wait list
const cl_event * event_wait_list, //Array of events to wait for
cl_event *event) //Event handler for this function2、图像旋转的例子
下面是一个完整的OpenCL例子,实现图像的旋转。在这个例子中,我把美丽的lenna旋转了90度。
下面是原始图像和旋转后的图像(黑白)



在这个例子中,我使用FreeImage库,可以从FreeImage网站或者我的code工程中下载。
http://code.google.com/p/imagefilter-opencl/downloads/detail?name=Dist.rar&can=2&q=#makechanges
图像旋转是指把定义的图像绕某一点以逆时针或顺时针方向旋转一定的角度,通常是指绕图像的中心以逆时针方向旋转。
假设图像的左上角为(left, top),右下角为(right, bottom),则图像上任意点(x0, y0)绕其中心(xcenter, ycenter)逆时针旋转angle角度后,新的坐标位置(x′, y′)的计算公式为:
xcenter = (right - left + 1) / 2 + left;
ycenter = (bottom - top + 1) / 2 + top;
x′ = (x0 - xcenter) cosθ - (y0 - ycenter) sinθ + xcenter;
y′ = (x0 - xcenter) sinθ + (y0 - ycenter) cosθ + ycenter;
下面给出kernel的代码:
1: __kernel void image_rotate( __global uchar * src_data, __global uchar * dest_data, //Data in global memory 2: int W, int H, //Image Dimensions 3: float sinTheta, float cosTheta ) //Rotation Parameters 4: { 5: //Thread gets its index within index space 6: const int ix = get_global_id(0); 7: const int iy = get_global_id(1); 8: 9: int xc = W/2; 10: int yc = H/2; 11: 12: int xpos = ( ix-xc)*cosTheta - (iy-yc)*sinTheta+xc; 13: int ypos = (ix-xc)*sinTheta + ( iy-yc)*cosTheta+yc; 14: 15: if ((xpos>=0) && (xpos< W) && (ypos>=0) && (ypos< H)) //Bound Checking 16: { 17: dest_data[ypos*W+xpos]= src_data[iy*W+ix]; 18: } 19: } 20: src_data为原始图像(灰度图)数据,dest_data为旋转后的图像数据。W、H分别为图像的高度和宽度。sinTheta和cosTheta是旋转参数。我在代码中实现了旋转90度,所以sinTheta为1,cosTheta为0,大家可以尝试其它的值。
下面是程序的流程图:
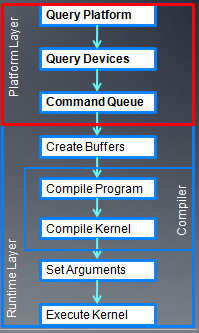
在前面向量加法的例子中,我已经介绍了OpenCL一些基本的步骤。
- 创建platform对象
- 创建GPU设备
- 创建contex
- 创建命令队列
- 创建缓冲对象,代码如下:
1: cl_mem d_ip = clCreateBuffer(2: context, CL_MEM_READ_ONLY,3: mem_size,4: NULL, NULL);5: l_mem d_op = clCreateBuffer(6: context, CL_MEM_WRITE_ONLY,7: mem_size,8: NULL, NULL);9: status = clEnqueueWriteBuffer (10: queue , d_ip, CL_TRUE,11: 0, mem_size, (void *)src_image,12: 0, NULL, NULL); - 创建程序对象
- 编译程序对象
- 创建Kernel对象
- 设置kernel参数
- 执行kernel
- 数据拷贝回host memory,我采用映射memory的方式。
1: unsigned char *op_data=0; 2: //op_data =(unsigned char *)malloc(mem_size); 3: status = clEnqueueReadBuffer( 4: //queue, d_op, 5: //CL_TRUE, //Blocking Read Back 6: //0, mem_size,(void*)op_data, NULL, NULL, NULL); 7: op_data = (cl_uchar *) clEnqueueMapBuffer( queue, 8: d_op, 9: CL_TRUE, 10: CL_MAP_READ, 11: 0, 12: mem_size, 13: 0, NULL, NULL, NULL );kernel执行时间的计算后面教程会有详细介绍,但在本节中,我们会给出通过事件机制来得到kernel执行时间,首先要在创建队列时候,使用CL_QUEUE_PROFILING_ENABLE参数,否则计算的kernel运行时间是0。
下面是代码:
1: //计算kerenl执行时间 2: cl_ulong startTime, endTime;clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_START, 4: sizeof(cl_ulong), &startTime, NULL); 5: clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_END, 6: sizeof(cl_ulong), &endTime, NULL); 7: cl_ulong kernelExecTimeNs = endTime-startTime; 8: printf("kernal exec time :%8.6f ms\n ", kernelExecTimeNs*1e-6 );
完整的程序代码:
1: #include "stdafx.h" 2: #include <CL/cl.h> 3: #include <stdio.h> 4: #include <stdlib.h> 5: #include <time.h> 6: #include <iostream> 7: #include <fstream> 8: 9: #include "gFreeImage.h" 10: 11: using namespace std; 12: #define NWITEMS 4 13: #pragma comment (lib,"OpenCL.lib") 14: #pragma comment(lib,"FreeImage.lib") 15: 16: //把文本文件读入一个string中 17: int convertToString(const char *filename, std::string& s) 18: { 19: size_t size; 20: char* str; 21: 22: std::fstream f(filename, (std::fstream::in | std::fstream::binary)); 23: 24: if(f.is_open()) 25: { 26: size_t fileSize; 27: f.seekg(0, std::fstream::end); 28: size = fileSize = (size_t)f.tellg(); 29: f.seekg(0, std::fstream::beg); 30: 31: str = new char[size+1]; 32: if(!str) 33: { 34: f.close(); 35: return NULL; 36: } 37: 38: f.read(str, fileSize); 39: f.close(); 40: str[size] = '\0'; 41: 42: s = str; 43: delete[] str; 44: return 0; 45: } 46: printf("Error: Failed to open file %s\n", filename); 47: return 1; 48: } 49: 50: //CPU旋转图像 51: void cpu_rotate(unsigned char* inbuf, unsigned char* outbuf, int w, int h,float sinTheta, float cosTheta) 52: { 53: int i, j; 54: int xc = w/2; 55: int yc = h/2; 56: 57: for(i = 0; i < h; i++) 58: { 59: for(j=0; j< w; j++) 60: { 61: int xpos = ( j-xc)*cosTheta - (i-yc)*sinTheta+xc; 62: int ypos = (j-xc)*sinTheta + ( i-yc)*cosTheta+yc; 63: 64: if(xpos>=0&&ypos>=0&&xpos<w&&ypos<h) 65: outbuf[ypos*w + xpos] = inbuf[i*w+j]; 66: } 67: } 68: } 69: 70: int main(int argc, char* argv[]) 71: { 72: //装入图像 73: unsigned char *src_image=0; 74: unsigned char *cpu_image=0; 75: int W, H; 76: gFreeImage img; 77: if(!img.LoadImageGrey("lenna.jpg")) 78: { 79: printf("装入lenna.jpg失败\n"); 80: exit(0); 81: } 82: else 83: src_image = img.getImageDataGrey(W, H); 84: 85: size_t mem_size = W*H; 86: cpu_image = (unsigned char*)malloc(mem_size); 87: 88: cl_uint status; 89: cl_platform_id platform; 90: 91: //创建平台对象 92: status = clGetPlatformIDs( 1, &platform, NULL ); 93: 94: cl_device_id device; 95: 96: //创建GPU设备 97: clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU, 98: 1, 99: &device, 100: NULL); 101: //创建context 102: cl_context context = clCreateContext( NULL, 103: 1, 104: &device, 105: NULL, NULL, NULL); 106: //创建命令队列 107: cl_command_queue queue = clCreateCommandQueue( context, 108: device, 109: CL_QUEUE_PROFILING_ENABLE, NULL ); 110: 111: //创建三个OpenCL内存对象,并把buf1的内容通过隐式拷贝的方式 112: //拷贝到clbuf1,buf2的内容通过显示拷贝的方式拷贝到clbuf2 113: cl_mem d_ip = clCreateBuffer( 114: context, CL_MEM_READ_ONLY, 115: mem_size, 116: NULL, NULL); 117: cl_mem d_op = clCreateBuffer( 118: context, CL_MEM_WRITE_ONLY, 119: mem_size, 120: NULL, NULL); 121: status = clEnqueueWriteBuffer ( 122: queue , d_ip, CL_TRUE, 123: 0, mem_size, (void *)src_image, 124: 0, NULL, NULL); 125: 126: const char * filename = "rotate.cl"; 127: std::string sourceStr; 128: status = convertToString(filename, sourceStr); 129: const char * source = sourceStr.c_str(); 130: size_t sourceSize[] = { strlen(source) }; 131: 132: //创建程序对象 133: cl_program program = clCreateProgramWithSource( 134: context, 135: 1, 136: &source, 137: sourceSize, 138: NULL); 139: //编译程序对象 140: status = clBuildProgram( program, 1, &device, NULL, NULL, NULL ); 141: if(status != 0) 142: { 143: printf("clBuild failed:%d\n", status); 144: char tbuf[0x10000]; 145: clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf, NULL); 146: printf("\n%s\n", tbuf); 147: return -1; 148: } 149: 150: 151: //创建Kernel对象 152: //Use the “image_rotate” function as the kernel 153: 154: //创建Kernel对象 155: cl_kernel kernel = clCreateKernel( program, "image_rotate", NULL ); 156: 157: //设置Kernel参数 158: float sintheta = 1, costheta = 0; 159: clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&d_ip); 160: clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&d_op); 161: clSetKernelArg(kernel, 2, sizeof(cl_int), (void *)&W); 162: clSetKernelArg(kernel, 3, sizeof(cl_int), (void *)&H); 163: clSetKernelArg(kernel, 4, sizeof(cl_float), (void *)&sintheta); 164: clSetKernelArg(kernel, 5, sizeof(cl_float), (void *)&costheta); 165: 166: //Set local and global workgroup sizes 167: size_t localws[2] = {16,16} ; 168: size_t globalws[2] = {W, H};//Assume divisible by 16 169: 170: cl_event ev; 171: //执行kernel 172: clEnqueueNDRangeKernel( 173: queue ,kernel, 174: 2, 0, globalws, localws, 175: 0, NULL, &ev); 176: 177: clFinish( queue ); 178: 179: //计算kerenl执行时间 180: cl_ulong startTime, endTime; 181: clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_START, 182: sizeof(cl_ulong), &startTime, NULL); 183: clGetEventProfilingInfo(ev, CL_PROFILING_COMMAND_END, 184: sizeof(cl_ulong), &endTime, NULL); 185: cl_ulong kernelExecTimeNs = endTime-startTime; 186: printf("kernal exec time :%8.6f ms\n ", kernelExecTimeNs*1e-6 ); 187: 188: //数据拷回host内存 189: // copy results from device back to host 190: unsigned char *op_data=0; 191: //op_data =(unsigned char *)malloc(mem_size); 192: // status = clEnqueueReadBuffer( 193: //queue, d_op, 194: //CL_TRUE, //Blocking Read Back 195: //0, mem_size,(void*)op_data, NULL, NULL, NULL); 196: op_data = (cl_uchar *) clEnqueueMapBuffer( queue, 197: d_op, 198: CL_TRUE, 199: CL_MAP_READ, 200: 0, 201: mem_size, 202: 0, NULL, NULL, NULL ); 203: 204: int i; 205: cpu_rotate(src_image,cpu_image, W, H, 1, 0); 206: for(i = 0; i < mem_size; i++) 207: { 208: src_image[i] =cpu_image[i]; 209: } 210: img.SaveImage("cpu_lenna_rotate.jpg"); 211: for(i = 0; i < mem_size; i++) 212: { 213: src_image[i] =op_data[i]; 214: } 215: img.SaveImage("lenna_rotate.jpg"); 216: 217: if(cpu_image) 218: free(cpu_image); 219: 220: //删除OpenCL资源对象 221: clReleaseMemObject(d_ip); 222: clReleaseMemObject(d_op); 223: clReleaseProgram(program); 224: clReleaseCommandQueue(queue); 225: clReleaseContext(context); 226: return 0; 227: } 228: 感兴趣的朋友可以从http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amdunicourseCode2.zip&can=2&q=#makechanges下载完整代码。
注意代码运行后,会在程序目录生成lenna_rotate.jpg,这时gpu执行的结果,另外还有一个cpu_lenna_rotate.jpg这是CPU执行的结果。
3、一个矩阵乘法的例子
在amd的slides中,本节还讲了一个简单的,没有优化的矩阵乘法,一共才2两页ppt,所以我也不在这儿详细讲述了,…,但简单介绍还是需要的。
1: for(int i = 0; i < Ha; i++) 2: for(int j = 0; j < Wb; j++){ 3: c[i][j] = 0; 4: for(int k = 0; k < Wa; k++) 5: c[i][j] += a[i][k] + b[k][j] 6: }上面的代码是矩阵乘法的例子,有三重循环,下面我们只给出kernel代码,完整程序请从:http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amdunicodeCode3.zip&can=2&q=#makechanges下载。
1: __kernel void simpleMultiply( 2: __global float* c, int Wa, int Wb, 3: __global float* a, __global float* b) 4: { 5: 6: //Get global position in Y direction 7: int row = get_global_id(1); 8: //Get global position in X direction 9: int col = get_global_id(0); 10: float sum = 0.0f; 11: //Calculate result of one element 12: for (int i = 0; i < Wa; i++) 13: {
从今天开始学习OpenCL……
因为老狼的显卡是AMD 5xx的redwood,所以下面先介绍OpenCL APP(Accelerated Parallel processing)的安装。
下载地址:http://developer.amd.com/tools/hc/AMDAPPSDK/downloads/Pages/default.aspx
安装注意事项:http://developer.amd.com/tools/hc/AMDAPPSDK/assets/AMD_APP_SDK_Installation_Notes.pdf
有用的资料:http://developer.amd.com/tools/hc/AMDAPPSDK/documentation/Pages/default.aspx
其中最有用的是下面几个文档:
AMD最新显卡Tahiti的ISA介绍,对OpenCL编程优化有用。
这本书是最好的OpenCL教程,好过市面上的任何一本OpenCL书,其中包括很多优化Kernel代码的内容,我计划以后就按照这本书的内容来学习opencl。
http://developer.amd.com/download/AMD_Accelerated_Parallel_Processing_OpenCL_Programming_Guide.pdf
再就是OpenCL 1.2的spec了,下载地址:OpenCL™ 1.2 Specification (revision 15) ,相对于1.1来说,1.2中还是有一些变化的,比如我以前写的程序中CreateImage2D函数发现在1.2中没有了,spec其实就是一个函数手册,偶尔用来查询一下而已。
另外一个比较好的初级教程,就是我翻译的AMD OpenCL大学教程了,http://www.cnblogs.com/mikewolf2002/archive/2012/01/30/2332356.html
现在,我们开始写一个简单的OpenCL程序,计算两个数组相加的和,放到另一个数组中去。程序用cpu和gpu分别计算,最后验证它们是否相等。OpenCL程序的流程大致如下:

下面是source code中的主要代码:
int main(int argc, char* argv[])
{
//在host内存中创建三个缓冲区
float *buf1 = 0;
float *buf2 = 0;
float *buf = 0;
buf1 =(float *)malloc(BUFSIZE * sizeof(float));
buf2 =(float *)malloc(BUFSIZE * sizeof(float));
buf =(float *)malloc(BUFSIZE * sizeof(float));
//用一些随机值初始化buf1和buf2的内容
int i;
srand( (unsigned)time( NULL ) );
for(i = 0; i < BUFSIZE; i++)
buf1[i] = rand()%65535;
srand( (unsigned)time( NULL ) +1000);
for(i = 0; i < BUFSIZE; i++)
buf2[i] = rand()%65535;
//cpu计算buf1,buf2的和
for(i = 0; i < BUFSIZE; i++)
buf[i] = buf1[i] + buf2[i];
cl_uint status;
cl_platform_id platform;
//创建平台对象
status = clGetPlatformIDs( 1, &platform, NULL );
注意:如果我们系统中安装不止一个opencl平台,比如我的os中,有intel和amd两家opencl平台,用上面这行代码,有可能会出错,因为它得到了intel的opencl平台,而intel的平台只支持cpu,而我们后面的操作都是基于gpu,这时我们可以用下面的代码,得到AMD的opencl平台。
cl_uint numPlatforms;
std::string platformVendor;
status = clGetPlatformIDs(0, NULL, &numPlatforms);
if(status != CL_SUCCESS)
{
return 0;
}
if (0 < numPlatforms)
{
cl_platform_id* platforms = new cl_platform_id[numPlatforms];
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
char platformName[100];
for (unsigned i = 0; i < numPlatforms; ++i)
{
status = clGetPlatformInfo(platforms[i],
CL_PLATFORM_VENDOR,
sizeof(platformName),
platformName,
NULL);
platform = platforms[i];
platformVendor.assign(platformName);
if (!strcmp(platformName, "Advanced Micro Devices, Inc."))
{
break;
}
}
std::cout << "Platform found : " << platformName << "\n";
delete[] platforms;
}
cl_device_id device;
//创建GPU设备
clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU,
1,
&device,
NULL);
//创建context
cl_context context = clCreateContext( NULL,
1,
&device,
NULL, NULL, NULL);
//创建命令队列
cl_command_queue queue = clCreateCommandQueue( context,
device,
CL_QUEUE_PROFILING_ENABLE, NULL );
//创建三个OpenCL内存对象,并把buf1的内容通过隐式拷贝的方式
//buf1内容拷贝到clbuf1,buf2的内容通过显示拷贝的方式拷贝到clbuf2
cl_mem clbuf1 = clCreateBuffer(context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
BUFSIZE*sizeof(cl_float),buf1,
NULL );
cl_mem clbuf2 = clCreateBuffer(context,
CL_MEM_READ_ONLY ,
BUFSIZE*sizeof(cl_float),NULL,
NULL );
cl_event writeEvt;
status = clEnqueueWriteBuffer(queue, clbuf2, 1,
0, BUFSIZE*sizeof(cl_float), buf2, 0, 0, 0);
上面这行代码把buf2中的内容拷贝到clbuf2,因为buf2位于host端,clbuf2位于device端,所以这个函数会执行一次host到device的传输操作,或者说一次system memory到video memory的拷贝操作,所以我在该函数的后面放置了clFush函数,表示把command queue中的所有命令提交到device(注意:该命令并不保证命令执行完成),所以我们调用函数waitForEventAndRelease来等待write缓冲的完成,waitForEventAndReleae是一个用户定义的函数,它的内容如下,主要代码就是通过event来查询我们的操作是否完成,没完成的话,程序就一直block在这行代码处,另外我们也可以用opencl中内置的函数clWaitForEvents来代替clFlush和waitForEventAndReleae。
//等待事件完成
int waitForEventAndRelease(cl_event *event)
{
cl_int status = CL_SUCCESS;
cl_int eventStatus = CL_QUEUED;
while(eventStatus != CL_COMPLETE)
{
status = clGetEventInfo(
*event,
CL_EVENT_COMMAND_EXECUTION_STATUS,
sizeof(cl_int),
&eventStatus,
NULL);
}
status = clReleaseEvent(*event);
return 0;
} status = clFlush(queue);
//等待数据传输完成再继续往下执行
waitForEventAndRelease(&writeEvt);
cl_mem buffer = clCreateBuffer( context,
CL_MEM_WRITE_ONLY,
BUFSIZE * sizeof(cl_float),
NULL, NULL );
kernel文件中放的是gpu中执行的代码,它被放在一个单独的文件add.cl中,本程序中kernel代码非常简单,只是执行两个数组相加。kernel的代码为:
__kernel void vecadd(__global const float* A, __global const float* B, __global float* C)
{
int id = get_global_id(0);
C[id] = A[id] + B[id];
}
//kernel文件为add.cl
const char * filename = "add.cl";
std::string sourceStr;
status = convertToString(filename, sourceStr);
convertToString也是用户定义的函数,该函数把kernel源文件读入到一个string中,它的代码如下:
//把文本文件读入一个string中,用来读入kernel源文件
int convertToString(const char *filename, std::string& s)
{
size_t size;
char* str;
std::fstream f(filename, (std::fstream::in | std::fstream::binary));
if(f.is_open())
{
size_t fileSize;
f.seekg(0, std::fstream::end);
size = fileSize = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size+1];
if(!str)
{
f.close();
return NULL;
}
f.read(str, fileSize);
f.close();
str[size] = '\0';
s = str;
delete[] str;
return 0;
}
printf("Error: Failed to open file %s\n", filename);
return 1;
}
const char * source = sourceStr.c_str();
size_t sourceSize[] = { strlen(source) };
//创建程序对象
cl_program program = clCreateProgramWithSource(
context,
1,
&source,
sourceSize,
NULL);
//编译程序对象
status = clBuildProgram( program, 1, &device, NULL, NULL, NULL );
if(status != 0)
{
printf("clBuild failed:%d\n", status);
char tbuf[0x10000];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf, NULL);
printf("\n%s\n", tbuf);
return -1;
}
//创建Kernel对象
cl_kernel kernel = clCreateKernel( program, "vecadd", NULL );
//设置Kernel参数
cl_int clnum = BUFSIZE;
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*) &clbuf1);
clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*) &clbuf2);
clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*) &buffer);
注意:在执行kernel时候,我们只设置了global work items数量,没有设置group size,这时候,系统会使用默认的work group size,通常可能是256之类的。
//执行kernel,Range用1维,work itmes size为BUFSIZE
cl_event ev;
size_t global_work_size = BUFSIZE;
clEnqueueNDRangeKernel( queue,
kernel,
1,
NULL,
&global_work_size,
NULL, 0, NULL, &ev);
status = clFlush( queue );
waitForEventAndRelease(&ev);
//数据拷回host内存
cl_float *ptr;
cl_event mapevt;
ptr = (cl_float *) clEnqueueMapBuffer( queue,
buffer,
CL_TRUE,
CL_MAP_READ,
0,
BUFSIZE * sizeof(cl_float),
0, NULL, NULL, NULL );
status = clFlush( queue );
waitForEventAndRelease(&mapevt);
//结果验证,和cpu计算的结果比较
if(!memcmp(buf, ptr, BUFSIZE))
printf("Verify passed\n");
else printf("verify failed");
if(buf)
free(buf);
if(buf1)
free(buf1);
if(buf2)
free(buf2);
程序结束后,这些opencl对象一般会自动释放,但是为了程序完整,养成一个好习惯,这儿我加上了手动释放opencl对象的代码。
//删除OpenCL资源对象
clReleaseMemObject(clbuf1);
clReleaseMemObject(clbuf2);
clReleaseMemObject(buffer);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
return 0;
}
程序执行后的界面如下:

完整的代码请参考:
工程文件gclTutorial1
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
在教程2中,我们通过函数convertToString,把kernel源文件读到一个string串中,然后用函数clCreateProgramWithSource装入程序对象,再调用函数clBuildProgram编译程序对象。其实我们也可以直接调用二进制kernel文件,这样,当不想把kernel文件给别人看的时候,起到一定的保密作用。在本教程中,我们会把读入的源文件存储一个二进制文件中,并且还会建立一个计时器类,用来记录数组加法在cpu和gpu端分别执行的时间。
首先我们建立工程文件gclTutorial2,在其中增加类gclFile,该类主要用来读取文本kernel文件,或者读写二进制kernel文件。
class gclFile
{
public:
gclFile(void);
~gclFile(void);
//打开opencl kernel源文件(文本模式)
bool open(const char* fileName);
//读写二进制kernel文件
bool writeBinaryToFile(const char* fileName, const char* birary, size_t numBytes);
bool readBinaryFromFile(const char* fileName);
…
}
gclFile中三个读写kernel文件的函数代码为:
bool gclFile::writeBinaryToFile(const char* fileName, const char* birary, size_t numBytes)
{
FILE *output = NULL;
output = fopen(fileName, "wb");
if(output == NULL)
return false;
fwrite(birary, sizeof(char), numBytes, output);
fclose(output);
return true;
}
bool gclFile::readBinaryFromFile(const char* fileName)
{
FILE * input = NULL;
size_t size = 0;
char* binary = NULL;
input = fopen(fileName, "rb");
if(input == NULL)
{
return false;
}
fseek(input, 0L, SEEK_END);
size = ftell(input);
//指向文件起始位置
rewind(input);
binary = (char*)malloc(size);
if(binary == NULL)
{
return false;
}
fread(binary, sizeof(char), size, input);
fclose(input);
source_.assign(binary, size);
free(binary);
return true;
}
bool gclFile::open(const char* fileName) //!< file name
{
size_t size;
char* str;
//以流方式打开文件
std::fstream f(fileName, (std::fstream::in | std::fstream::binary));
// 检查是否打开了文件流
if (f.is_open())
{
size_t sizeFile;
// 得到文件size
f.seekg(0, std::fstream::end);
size = sizeFile = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size + 1];
if (!str)
{
f.close();
return false;
}
// 读文件
f.read(str, sizeFile);
f.close();
str[size] = '\0';
source_ = str;
delete[] str;
return true;
}
return false;
}现在,在main.cpp中,我们就可以用gclFile类的open函数来读入kernel源文件了:
//kernel文件为add.cl
gclFile kernelFile;
if(!kernelFile.open("add.cl"))
{
printf("Failed to load kernel file \n");
exit(0);
}
const char * source = kernelFile.source().c_str();
size_t sourceSize[] = {strlen(source)};
//创建程序对象
cl_program program = clCreateProgramWithSource(
context,
1,
&source,
sourceSize,
NULL);
编译好kernel后,我们可以通过下面的代码,把编译好的kernel存储在一个二进制文件addvec.bin中,在教程4种,我们将会直接装入这个二进制的kernel文件。
//存储编译好的kernel文件
char **binaries = (char **)malloc( sizeof(char *) * 1 ); //只有一个设备
size_t *binarySizes = (size_t*)malloc( sizeof(size_t) * 1 );
status = clGetProgramInfo(program,
CL_PROGRAM_BINARY_SIZES,
sizeof(size_t) * 1,
binarySizes, NULL);
binaries[0] = (char *)malloc( sizeof(char) * binarySizes[0]);
status = clGetProgramInfo(program,
CL_PROGRAM_BINARIES,
sizeof(char *) * 1,
binaries,
NULL);
kernelFile.writeBinaryToFile("vecadd.bin", binaries[0],binarySizes[0]);我们还会建立一个计时器类gclTimer,用来统计时间,这个类主要用QueryPerformanceFrequency得到时钟频率,用QueryPerformanceCounter得到流逝的ticks数,最终得到流逝的时间。函数非常简单,
class gclTimer
{
public:
gclTimer(void);
~gclTimer(void);
private:
double _freq;
double _clocks;
double _start;
public:
void Start(void); // 启动计时器
void Stop(void); //停止计时器
void Reset(void); //复位计时器
double GetElapsedTime(void); //计算流逝的时间
};
下面我们在cpu端执行数组加法时,增加计时器的代码:
gclTimer clTimer;
clTimer.Reset();
clTimer.Start();
//cpu计算buf1,buf2的和
for(i = 0; i < BUFSIZE; i++)
buf[i] = buf1[i] + buf2[i];
clTimer.Stop();
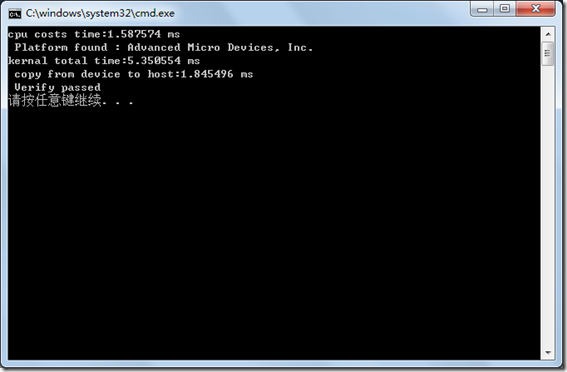
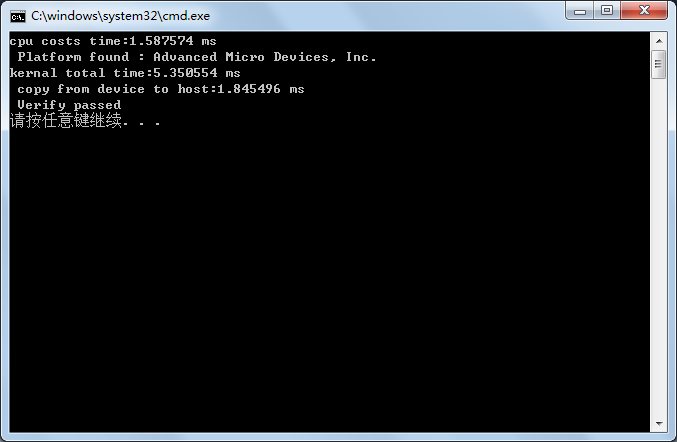
printf("cpu costs time:%.6f ms \n ", clTimer.GetElapsedTime()*1000 );
同理在gpu执行kernel代码,以及copy gpu结果到cpu时候,增加计时器代码:
//执行kernel,Range用1维,work itmes size为BUFSIZE,
cl_event ev;
size_t global_work_size = BUFSIZE;
clTimer.Reset();
clTimer.Start();
clEnqueueNDRangeKernel( queue,
kernel,
1,
NULL,
&global_work_size,
NULL, 0, NULL, &ev);
status = clFlush( queue );
waitForEventAndRelease(&ev);
//clWaitForEvents(1, &ev);
clTimer.Stop();
printf("kernal total time:%.6f ms \n ", clTimer.GetElapsedTime()*1000 );
//数据拷回host内存
cl_float *ptr;
clTimer.Reset();
clTimer.Start();
cl_event mapevt;
ptr = (cl_float *) clEnqueueMapBuffer( queue,
buffer,
CL_TRUE,
CL_MAP_READ,
0,
BUFSIZE * sizeof(cl_float),
0, NULL, &mapevt, NULL );
status = clFlush( queue );
waitForEventAndRelease(&mapevt);
//clWaitForEvents(1, &mapevt);
clTimer.Stop();
printf("copy from device to host:%.6f ms \n ", clTimer.GetElapsedTime()*1000 );最终程序执行界面如下,在bufsize为262144时,在我的显卡上gpu还有cpu快呢…,在程序目录,我们可以看到也产生了vecadd.bin文件了。
完整的代码请参考:
工程文件gclTutorial2
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
本教程中,我们使用上一篇教程中产生的二进制kernel文件vecadd.bin作为输入来创建程序对象,程序代码如下:
//kernel文件为vecadd.bin
gclFile kernelFile;
if(!kernelFile.readBinaryFromFile("vecadd.bin"))
{
printf("Failed to load binary file \n");
exit(0);
}
const char * binary = kernelFile.source().c_str();
size_t binarySize = kernelFile.source().size();
cl_program program = clCreateProgramWithBinary(context,
1,
&device,
(const size_t *)&binarySize,
(const unsigned char**)&binary,
NULL,
NULL);
程序执行的界面和教程3中一摸一样…
完整的代码请参考:
工程文件gclTutorial3
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
在本教程中,我们使用二维NDRange来设置workgroup,这样在opencl中,workitme的组织形式是二维的,Kernel中 的代码也要做相应的改变,我们先看一下clEnqueueNDRangeKernel函数的变化。首先我们指定了workgroup size为localx*localy,通常这个值为64的倍数,但最好不要超过256。
//执行kernel,Range用2维,work itmes size为width*height,
cl_event ev;
size_t globalThreads[] = {width, height};
size_t localx, localy;
if(width/8 > 4)
localx = 16;
else if(width < 8)
localx = width;
else localx = 8;
if(height/8 > 4)
localy = 16;
else if (height < 8)
localy = height;
else localy = 8;
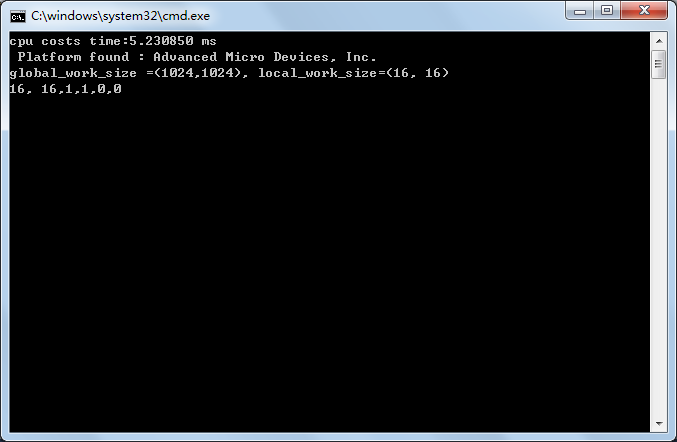
size_t localThreads[] = {localx, localy};// localx*localy应该是64的倍数
printf("global_work_size =(%d,%d), local_work_size=(%d, %d)\n",width,height,localx,localy);
clTimer.Reset();
clTimer.Start();
clEnqueueNDRangeKernel( queue,
kernel,
2,
NULL,
globalThreads,
localThreads, 0, NULL, &ev);
注意:在上面代码中,定义global threads以及local threads数量,都是通过二维数组的方式进行的。
新的Kernel代码如下:
#pragma OPENCL EXTENSION cl_amd_printf : enable
__kernel void vecadd(__global const float* a, __global const float* b, __global float* c)
{
int x = get_global_id(0);
int y = get_global_id(1);
int width = get_global_size(0);
int height = get_global_size(1);
if(x == 1 && y ==1)
printf("%d, %d,%d,%d,%d,%d\n",get_local_size(0),get_local_size(1),get_local_id(0),get_local_id(1),get_group_id(0),get_group_id(1));
c[x + y * width] = a[x + y * width] + b[x + y * width];
}
我们在kernel中增加了#pragma OPENCL EXTENSION cl_amd_printf : enable,以便在kernel中通过printf函数进行debug,这是AMD的一个扩展。printf还可以直接打印出float4这样的向量,比如printf(“%v4f”, vec)。
另外,在main.cpp中增加一行代码:
//告诉driver dump il和isa文件
_putenv("GPU_DUMP_DEVICE_KERNEL=3");
我们可以在程序目录dump出il和isa形式的kernel文件,对于熟悉isa汇编的人,这是一个很好的调试performance的方法。
在最新的app sdk 2.7中,在kernel中使用printf的时候,这个程序会hang在哪儿,以前没这种情况。
程序执行界面。
完整的代码请参考:
工程文件gclTutorial4
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
在本教程中,我们学习用opencl进行简单的图像处理,对一个图片进行旋转。图片读入、保存等工作,我们使用开源的FreeImage,下载地址:http://freeimage.sourceforge.net/
首先我们建立一个gFreeImage类,用来装入图像,该类主要调用FreeImage的函数,首先会初始化FreeImage库,然后根据文件名猜测图像文件格式,最终load图像文件到变量FIBITMAP *bitmap中去。同时,我们还定义了2个缓冲
unsigned char *imageData;
unsigned char *imageData4;
用来存放图像数据,之所以定义imageData4,是因为通常的图片文件,比如jpg,bmp都是3个通道,没有包括alpha通道,但是在gpu中处理数据时候,通常以vector4或者vector的形式进行,不能以vector3进行,所以我们装入图像后,会把imageData指向图像数据,同时生成包括alpha通道的图像数据imageData4。
另外,我们还定义了一个函数LoadImageGrey,该函数用来装入灰度图,灰度图一个像素用一个uchar表示。
在main.cpp中,我们首先定义一个cpu处理图像旋转的函数:
//CPU旋转图像
void cpu_rotate(unsigned char* inbuf, unsigned char* outbuf, int w, int h,float sinTheta, float cosTheta)
{
int i, j;
int xc = w/2;
int yc = h/2;
for(i = 0; i < h; i++)
{
for(j=0; j< w; j++)
{
int xpos = ( j-xc)*cosTheta - (i-yc)*sinTheta+xc;
int ypos = (j-xc)*sinTheta + ( i-yc)*cosTheta+yc;
if(xpos>=0&&ypos>=0&&xpos<w&&ypos<h)
outbuf[ypos*w + xpos] = inbuf[i*w+j];
}
}
}
在main函数中,我们首先会装入图像文件,代码如下:
int W, H;
gFreeImage img;
if(!img.LoadImageGrey("lenna.jpg"))
{
printf("can‘t load lenna.jpg\n");
exit(0);
}
else
src_image = img.getImageDataGrey(W, H);
size_t mem_size = W*H;
cpu_image = (unsigned char*)malloc(mem_size);之后,定义2个cl memory对象,一个用来放原始图像,一个用来放旋转后的图像。
//创建2个OpenCL内存对象
cl_mem d_ip = clCreateBuffer(
context, CL_MEM_READ_ONLY,
mem_size,
NULL, NULL);
cl_mem d_op = clCreateBuffer(
context, CL_MEM_WRITE_ONLY,
mem_size,
NULL, NULL);
cl_event writeEvt;
status = clEnqueueWriteBuffer (
queue , d_ip, CL_TRUE,
0, mem_size, (void *)src_image,
0, NULL, &writeEvt);
//等待数据传输完成再继续往下执行
status = clFlush(queue);
waitForEventAndRelease(&writeEvt);
//clWaitForEvents(1, &writeEvt);
旋转kernel函数需要传入6个参数:
//创建Kernel对象
cl_kernel kernel = clCreateKernel( program, "image_rotate", NULL );
//设置Kernel参数
float sintheta = 1, costheta = 0;
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&d_ip);
clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&d_op);
clSetKernelArg(kernel, 2, sizeof(cl_int), (void *)&W);
clSetKernelArg(kernel, 3, sizeof(cl_int), (void *)&H);
clSetKernelArg(kernel, 4, sizeof(cl_float), (void *)&sintheta);
clSetKernelArg(kernel, 5, sizeof(cl_float), (void *)&costheta);
kernel执行的代码为:
//执行kernel,Range用2维,work itmes size为W*H,
cl_event ev;
size_t globalThreads[] = {W, H};
size_t localThreads[] = {16, 16}; // localx*localy应该是64的倍数
printf("global_work_size =(%d,%d), local_work_size=(16, 16)\n",W,H);
clTimer.Reset();
clTimer.Start();
clEnqueueNDRangeKernel( queue,
kernel,
2,
NULL,
globalThreads,
localThreads, 0, NULL, &ev);
//没有设置local group size时候,系统将会自动设置为 (256,1)
status = clFlush( queue );
waitForEventAndRelease(&ev);
//clWaitForEvents(1, &ev);
clTimer.Stop();
printf("kernal total time:%.6f ms \n ", clTimer.GetElapsedTime()*1000 );
kernel函数代码为:
#pragma OPENCL EXTENSION cl_amd_printf : enable
__kernel void image_rotate( __global uchar * src_data, __global uchar * dest_data, //源图像和输出图像都放在global memory中
int W, int H, //图像size
float sinTheta, float cosTheta ) //旋转角度
{
const int ix = get_global_id(0);
const int iy = get_global_id(1);
int xc = W/2;
int yc = H/2;
int xpos = ( ix-xc)*cosTheta - (iy-yc)*sinTheta+xc;
int ypos = (ix-xc)*sinTheta + ( iy-yc)*cosTheta+yc;
if ((xpos>=0) && (xpos< W) && (ypos>=0) && (ypos< H)) //边界检测
{
dest_data[ypos*W+xpos]= src_data[iy*W+ix];
}
}
gpu执行完毕后,旋转后的图像保存在lenna_rotate.jpg,我们还会用cpu rotate函数执行一次旋转,同时把生成的图像保存到cpu_lenna_rotate.jpg。
完整的代码请参考:
工程文件gclTutorial5
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
histogram翻译成中文就是直方图,在计算机图像处理和视觉技术中,通常用histogram来进行图像匹配,从而完成track,比如meanshift跟踪算法中,经常要用到图像的直方图。
灰度图的histogram计算,首先要选择bin(中文可以称作槽)的数量,对于灰度图,像素的范围通常是[0-255],所以bin的数目就是256,然后我们循环整幅图像,统计出每种像素值出现的次数,放到对应的bin中。比如bin[0]中放的就是整幅图像中灰度值为0的像素个数,bin[1]中放的就是整幅图像中灰度值为1的像素个数……
下面的直方图就是灰度图lenna对应的直方图。

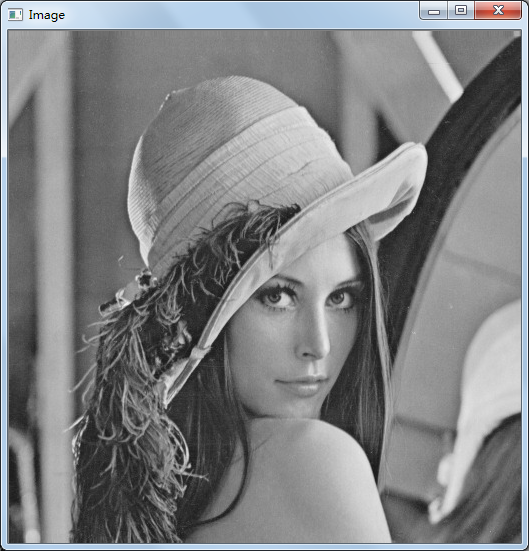
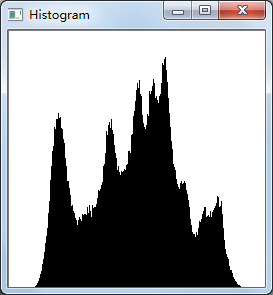
灰度图直方图的cpu计算特别简单,定义一个数组hostBin[256],初始化所有数组元素为0,然后循环整幅图像,得到直方图,代码如下:
//cpu求直方图
void cpu_histgo()
{
int i, j;
for(i = 0; i < height; ++i)
{
for(j = 0; j < width; ++j)
{
//printf("data: %d\n", data[i * width + j] );
hostBin[data[i * width + j]]++;
//printf("hostbin %d=%d\n", data[i * width + j], hostBin[data[i * width + j]]);
}
}
}
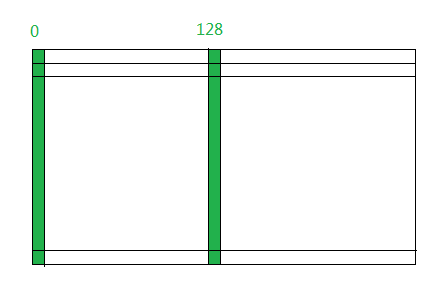
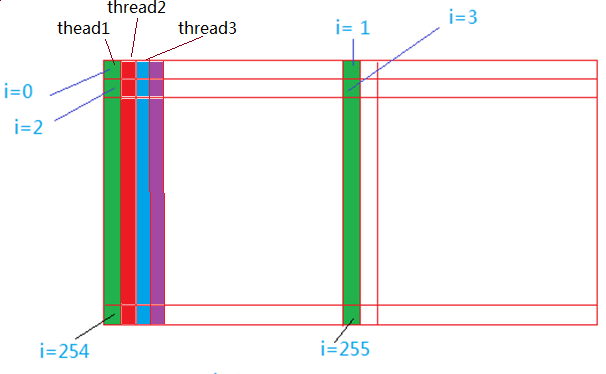
如何使用opencl,来计算灰度图,就没有那么简单了。我们知道gpu的优势是并行计算,如何把图像分块,来并行计算直方图,是我们讨论的重点。下面是一副512*512图像的thread,workgroup划分:


我们设定图像的宽度是bins的整数倍,即256的倍数,高度是workgroup size(本程序中,设置为128)的倍数,如果图像高宽不是bins和workgroup size的倍数,则我们通过下面的公式把图像的宽度和高度变成它们的倍数:
//width是binSize的整数倍,height是groupsize的整数倍
width = (width / binSize ? width / binSize: 1) * binSize;
height = (height / groupSize ? height / groupSize: 1) * groupSize;
则512*512的图像可以分为8个work group,每个workgroup包括128个thread,每个thread计算256个像素的直方图,并把结果放到该thread对应的local memroy空间,在kenrel代码结束前,合并一个workgroup中所有thread的直方图,生成一个workgroup块的直方图,最后在host端,合并8个workgroup块的直方图,产生最终的直方图。
openCL的memory对象主要有3个,dataBuffer用来传入图像数据,而minDeviceBinBuf大小是workgroup number *256, 即每个workgroup对应一个bin,另外一个kernel函数的第二个参数,它的大小为workgroup size*256, 用于workgroup中的每个线程存放自己256个像素的直方图结果。
//创建2个OpenCL内存对象
dataBuf = clCreateBuffer(
context,
CL_MEM_READ_ONLY,
sizeof(cl_uchar) * width * height,
NULL,
0);
//该对象存放每个block块的直方图结果
midDeviceBinBuf = clCreateBuffer(
context,
CL_MEM_WRITE_ONLY,
sizeof(cl_uint) * binSize * subHistgCnt,
NULL,
0);
…
status = clSetKernelArg(kernel, 1, groupSize * binSize * sizeof(cl_uchar), NULL);//local memroy size, lds for amd
下面看看kernel代码是如何计算workgroup块的直方图。
__kernel
void histogram256(__global const uchar* data,
__local uchar* sharedArray,
__global uint* binResult)
{
size_t localId = get_local_id(0);
size_t globalId = get_global_id(0);
size_t groupId = get_group_id(0);
size_t groupSize = get_local_size(0);
下面这部分代码初始化每个thread对应的local memory,也就是对应的256个bin中计数清零。sharedArray大小是workgroup size * 256 = 128 * 256
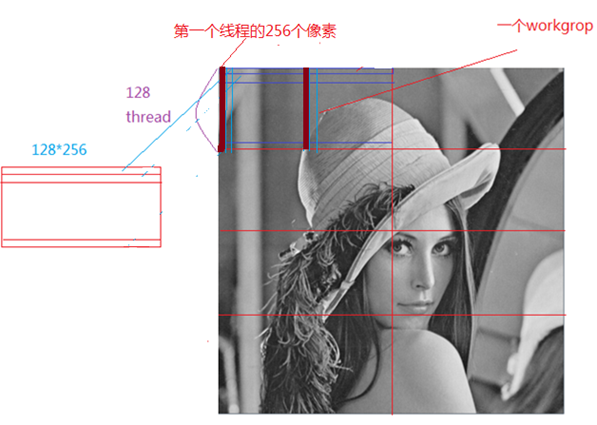
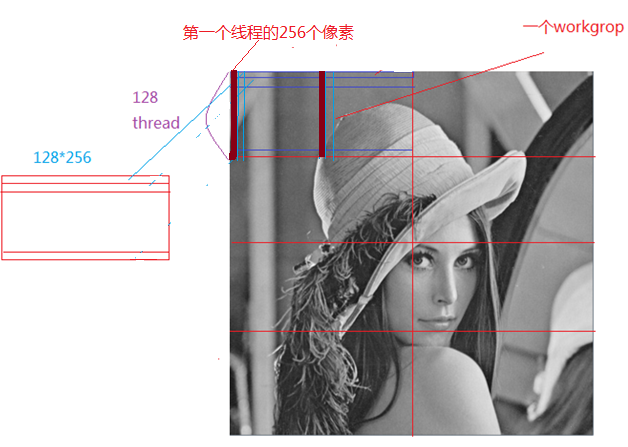
//初始化共享内存
for(int i = 0; i < BIN_SIZE; ++i)
sharedArray[localId * BIN_SIZE + i] = 0;
通过barrier设置workgroup中所有thread的同步点,保证所有thread都完成初始化操作。
barrier(CLK_LOCAL_MEM_FENCE);
下面的代码,计算thread中,256个像素的直方图,比如对于workgroup 0中的thread 0它计算的256个像素为绿条的部分像素,注意:每个thread的包含的像素并不是连续的。
//计算thread直方图
for(int i = 0; i < BIN_SIZE; ++i)
{
uint value = (uint)data[groupId * groupSize * BIN_SIZE + i * groupSize + localId];
sharedArray[localId * BIN_SIZE + value]++;
}
通过fence,保证每个thread都完成各自的直方图计算。
barrier(CLK_LOCAL_MEM_FENCE);
下面是合并各个thread的直方图形成整个workgroup像素块的直方图,每个thread合并2个bin,比如thread 0,合并bin0和bin128。

//合并workgroup中所有线程的直方图,产生workgroup直方图
for(int i = 0; i < BIN_SIZE / groupSize; ++i)
{
uint binCount = 0;
for(int j = 0; j < groupSize; ++j)
binCount += sharedArray[j * BIN_SIZE + i * groupSize + localId];
binResult[groupId * BIN_SIZE + i * groupSize + localId] = binCount;
}
}
最终在host端,我们还要把每个workgroup块的直方图合并成得到整个图像的直方图,主要代码如下:
// 合并子块直方图值
for(i = 0; i < subHistgCnt; ++i)
{
for( j = 0; j < binSize; ++j)
{
deviceBin[j] += midDeviceBin[i * binSize + j];
}
}
完整的代码请参考:
工程文件gclTutorial7
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
本教程代码基本上和上一篇教程中代码是一样的,区别主要包括以下2点:
1、我们装入的是RGBA 彩色图。
//装入图像
unsigned char *src_image=0;
gFreeImage img;
if(!img.LoadImage("../lenna.jpg"))
{
printf("can‘t load lenna.jpg\n");
exit(0);
}
src_image = img.getImageData(width,height);
2、在kernel代码中,有点小变化,kernel代码如下:
#define LINEAR_MEM_ACCESS
#pragma OPENCL EXTENSION cl_khr_byte_addressable_store : enable
#define BIN_SIZE 256
/**
* 计算直方图,bins是256
* data 输入数据
* 一个workgroup内所有thread共享的内存,
* 每个workgroup的直方图
*/
__kernel
void histogram256(__global const uchar4* data,
__local uchar* sharedArray,
__global uint* binResult)
{
size_t localId = get_local_id(0);
size_t globalId = get_global_id(0);
size_t groupId = get_group_id(0);
size_t groupSize = get_local_size(0);
//初始化共享内存
for(int i = 0; i < BIN_SIZE; ++i)
sharedArray[localId * BIN_SIZE + i] = 0;
barrier(CLK_LOCAL_MEM_FENCE);
uchar R, G, B, A, T;
//计算thread直方图
for(int i = 0; i < BIN_SIZE; ++i)
{
#ifdef LINEAR_MEM_ACCESS
R = (uint)data[groupId * groupSize * BIN_SIZE + i * groupSize + localId].x;
G = (uint)data[groupId * groupSize * BIN_SIZE + i * groupSize + localId].y;
B = (uint)data[groupId * groupSize * BIN_SIZE + i * groupSize + localId].z;
A = (uint)data[groupId * groupSize * BIN_SIZE + i * groupSize + localId].w;
uint value = (uint)max(max(R,G),max(B,A));
#else
uint value = data[globalId * BIN_SIZE + i];
#endif // LINEAR_MEM_ACCESS
sharedArray[localId * BIN_SIZE + value]++;
}
barrier(CLK_LOCAL_MEM_FENCE);
//合并workgroup中所有线程的直方图,产生workgroup直方图
for(int i = 0; i < BIN_SIZE / groupSize; ++i)
{
uint binCount = 0;
for(int j = 0; j < groupSize; ++j)
binCount += sharedArray[j * BIN_SIZE + i * groupSize + localId];
binResult[groupId * BIN_SIZE + i * groupSize + localId] = binCount;
}
}
完整的代码请参考:
工程文件gclTutorial8
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
在opencl编程中,特别是基于gpu的opencl的编程,提高程序性能最主要的方法就是想法提高memory的利用率:一个是提高global memory的合并读写效率,另一个就是减少local memory的bank conflit。下面我们分析一下教程7中的代码,其的memory利用率如何?
首先我们用amd的opencl profiler分析一下程序性能(不会找不到用吧,点击view-other windows-app profiler…,然后就看到了…)。
下面我们来分析我们的kernel代码中memory操作:
首先是shared memory的的初始化,我们知道shared memory是local memory,被一个workgroup中的所有thread,或者说work item共享。在amd硬件系统中,local memory是LDS,它通常是为32k,分为32个bank,dword字节地址,每个bank 512个item,我们可以通过函数得到自己系统中的local memory数量:
cl_ulong DeviceLocalMemSize;
clGetDeviceInfo(device,
CL_DEVICE_LOCAL_MEM_SIZE,
sizeof(cl_ulong),
&DeviceLocalMemSize,
NULL);
lds的示意图如下,对于每个bank,同时只能有一个读写请求,如果两个thread都读写bank1,那个必须串行访问,这就称作bank conflict。

kernel初始化local memory的代码如下:
//初始化共享内存
for(int i = 0; i < BIN_SIZE; ++i)
sharedArray[localId * BIN_SIZE + i] = 0;
在同一时间,thread0访问地址0(bank1),thread1,访问地址256,也在bank1,…,这样就有很多bank conflit,降低程序的性能。从profiler里面可以看到,lds bank conflit为13.98,很高的比例,所以此时同时运行的thread就比较少,只有总wave(每个wave 64个thread)的12%(我曾经默认lds内存分配是0,这样我们就省去了这些代码,但是实际上分配内存是一些随机的值…)。

第二段memory操作的代码为:
//计算thread直方图
for(int i = 0; i < BIN_SIZE; ++i)
{
uint value = (uint)data[groupId * groupSize * BIN_SIZE + i * groupSize + localId];
sharedArray[localId * BIN_SIZE + value]++;
}
其中有lds的操作,也有global memory的操作,对于全局memory的访问,在同一时刻,thread0访问i=0的memory
,thread1访问相邻的memory单元…,这是对于global memory的访问会采用合并读写的方式(coalencing),就是一个memory请求返回16个dword,也就是一个请求满足16个thread,提高memory利用率。此时对lds的写是随机的,根据value的值决定,不能控制…
最后一段memory读写的代码:
//合并workgroup中所有线程的直方图,产生workgroup直方图
for(int i = 0; i < BIN_SIZE / groupSize; ++i)
{
uint binCount = 0;
for(int j = 0; j < groupSize; ++j)
binCount += sharedArray[j * BIN_SIZE + i * groupSize + localId];
binResult[groupId * BIN_SIZE + i * groupSize + localId] = binCount;
}
其中lds的读写如下图,此时每个线程访问不同的bank,因为amd lds访问就是以32为单位,所以实际上,这段代码不会有bank conflit。
本章学习一下在opencl中如何实现矩阵的转置,主要的技巧还是利用好local memory,防止bank conflit以及使得全局memory的读写尽量是合并(coalensing)读写。
我们的矩阵是一副二维灰度图像256*256,矩阵的转置也就是图像的转置。每个thread处理16(4*4)个pixel(uchar),workgroup的size是(16,16)。
下面直接看shader代码:
uint wiWidth = get_global_size(0);
uint gix_t = get_group_id(0);
uint giy_t = get_group_id(1);
uint num_of_blocks_x = get_num_groups(0);
uint giy = gix_t;
uint gix = (gix_t+giy_t)%num_of_blocks_x;
uint lix = get_local_id(0);
uint liy = get_local_id(1);
uint blockSize = get_local_size(0);
uint ix = gix*blockSize + lix;
uint iy = giy*blockSize + liy;
int index_in = ix + (iy)*wiWidth*4;
// 通过合并读写把输入数据装入到lds中
int ind = liy*blockSize*4+lix;
block[ind] = input[index_in];
block[ind+blockSize] = input[index_in+wiWidth];
block[ind+blockSize*2] = input[index_in+wiWidth*2];
block[ind+blockSize*3] = input[index_in+wiWidth*3];
因为workgroup size是(16,16),所以lix,liy的取值范围都是0-15,下面我们通过图片看下,lix=0 liy=0,lix=1 liy=0时候,ind,以及index_in的值,从而得到输入图像数据如何映射到local memory中。
lix=0 liy=0
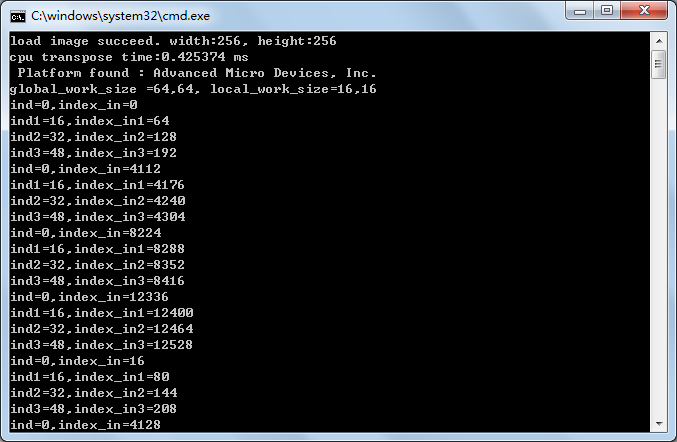
lix=1 liy=0

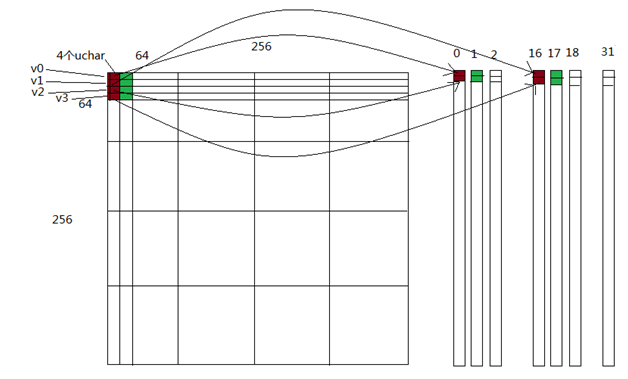
下面是影射关系,(0,0) thread处理的16个pixel用血红色表示,它们映射到lds的0bank和16bank,(1,0)thread处理的像素用绿色表示,它们映射到lds的bank1和bank17,有效的避免了bank conflit,而全局memory的访问不同thread对应连续的全局memory空间,可以实现合并读写,从而提高程序性能。
把转置的数据写到全局memory中的代码如下:
ix = giy*blockSize + lix;
iy = gix*blockSize + liy;
int index_out = ix + (iy)*wiWidth*4;
ind = lix*blockSize*4+liy;
uchar4 v0 = block[ind];
uchar4 v1 = block[ind+blockSize];
uchar4 v2 = block[ind+blockSize*2];
uchar4 v3 = block[ind+blockSize*3];
// 通过合并读写把lds中数据写回到全局memory中
output[index_out] = (uchar4)(v0.x, v1.x, v2.x, v3.x);
output[index_out+wiWidth] = (uchar4)(v0.y, v1.y, v2.y, v3.y);
output[index_out+wiWidth*2] = (uchar4)(v0.z, v1.z, v2.z, v3.z);
output[index_out+wiWidth*3] = (uchar4)(v0.w, v1.w, v2.w, v3.w);
对应copy关系图如下:
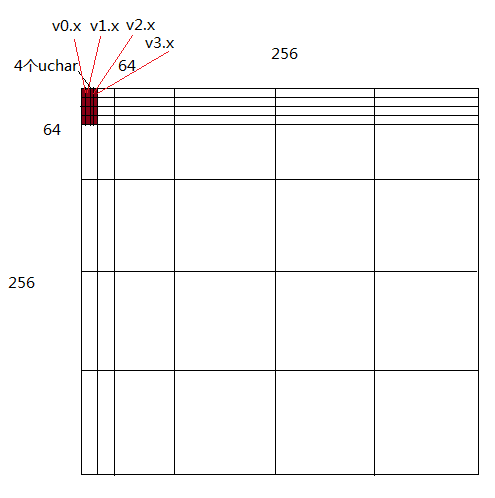
完整的代码请参考:
工程文件gclTutorial9
代码下载:
稍后提供
本篇教程中,我们学习一下如何用opencl有效实现数组求和,也就是通常所说的reduction问题。
在程序中,我们设置workgroup size为256,kernel的输入、输出缓冲参数都用uint4的格式,这样我们原始求和的数组大小为256*4的倍数,数据类型为uint。我们设定每个workgroup处理处理512个uint,即2048个uint
为了简便期间,我们输出数组长度定为4096,即需要2个workgruop来处理。
kernel代码如下:
__kernel void reduce(__global uint4* input, __global uint4* output, __local uint4* sdata)
{
// 把数据装入lds
unsigned int tid = get_local_id(0);
unsigned int bid = get_group_id(0);
unsigned int gid = get_global_id(0);
unsigned int localSize = get_local_size(0);
unsigned int stride = gid * 2;
sdata[tid] = input[stride] + input[stride + 1];
barrier(CLK_LOCAL_MEM_FENCE);
// 在lds中进行reduction操作,得到数组求和的结果
for(unsigned int s = localSize >> 1; s > 0; s >>= 1)
{
if(tid < s)
{
sdata[tid] += sdata[tid + s];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
// 把一个workgroup计算的结果输出到输出缓冲,是一个uint4,还需要在host端再进行一次reduction过程
if(tid == 0) output[bid] = sdata[0];
}
在程序中,global和local的NDRange,我们都用一维的形式。下面以图的方式看下kernel代码是如何执行的:

对第一个workgroup中的第一个thread的来说,它首先进行一次reduction操作,把两个uint4相加,放到lds(shared memory)中,然后再在lds中进行reduction操作,此时要从global memory中取数据,可以看出连续的thread访问连续的global memory,这时可以利用合并读写。
申请的shared memory大小为groupsize*sizeof(uint4),相加后uint4放入32bank的lds中,放置的方式应该是如下图所示,因为放入的是uint4,所以会放入连续的4个bank中(每个bank都是dword宽),可见只能同时有8个thread访问lds,所以会有一定程序的bank conflit。从App profiler session,我们可以看到:


接下来,kernel会通过一个for循环迭代执行reduction操作,求得一个workgroup中的uint4的和。
迭代的第一次s=128,这时会执行如下图的两两相加,workgroup中同时执行的thread为128,thread local id大于等于128的线程都不会做什么事情,在每个循环的末尾,有一个barrier来同步所有thread,以便所有thread都完成这次循环后再进入下一次循环。

第二次迭代的时候,只剩下前面128个uint4,workgroup中同时执行的thread为64。最后,当s=1时候,完成迭代reduction操作,然后把thread0(第一个thread)的结果输出。
在host段,我们还要做一次相加操作,把不同workgroup得到的uint4,拆分成uint,并相加求得最终的结果。
//在cpu reduction各个workgroup的结果以及uint4分量 reduction
output = 0;
for(int i = 0; i < numBlocks * VECTOR_SIZE; ++i)
output += outMapPtr[i];
printf("gpu reduction result:%d\n", output);
if(refOutput==output) printf("passed\n");
程序执行后结果如下:

完整的代码请参考:
工程文件gclTutorial11
代码下载:
稍后提供














 3517
3517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









