






有一个很简单的题目是这样的:给一个存有随机数的数组排序
书上给的程序如下:
#include<stdio.h>
#define MAXNUM 100
typedef int KeyType;
typedef int DataType;
/*数据结构部分*/
typedef struct
{
KeyType key; //排序的字段
DataType info; //记录其他字段
} RecordNode;
typedef struct
{
RecordNode record[MAXNUM];
int n; //n为文件中的记录个数,n<MAXNUM
} SortObject;
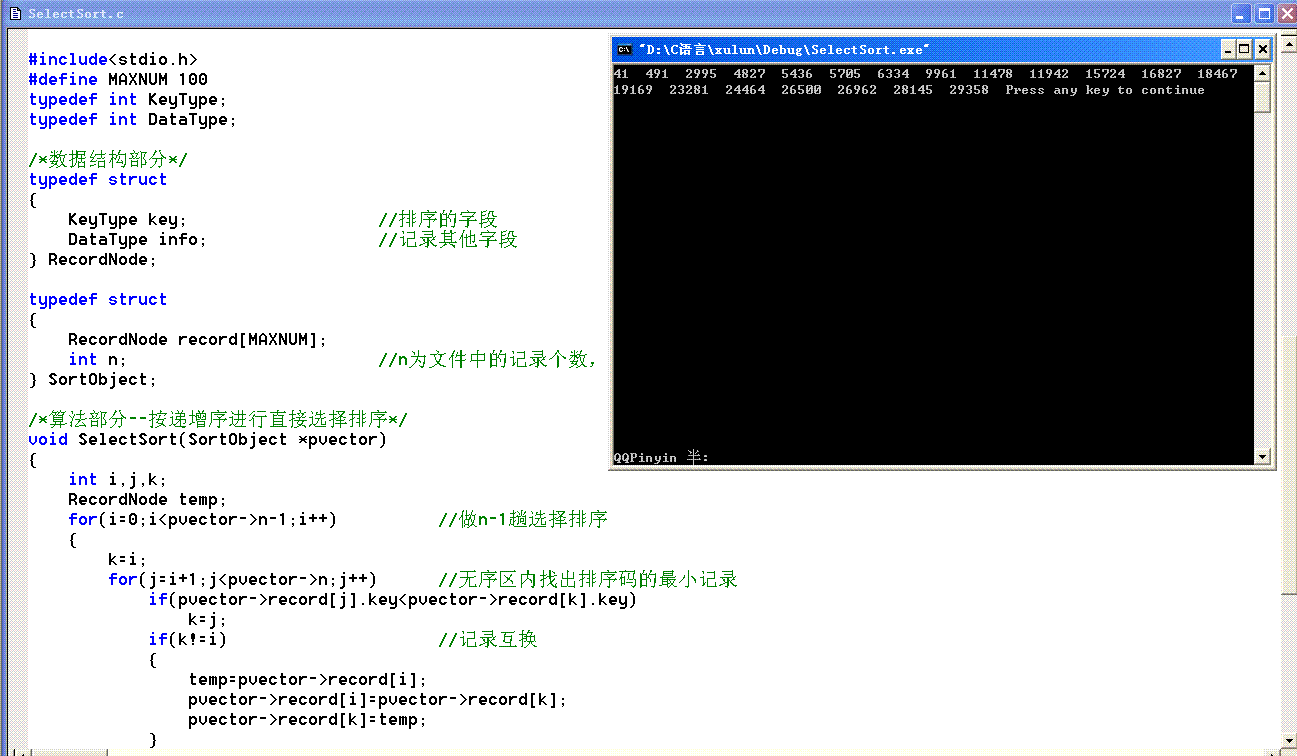
/*算法部分--按递增序进行直接选择排序*/
void SelectSort(SortObject *pvector)
{
int i,j,k;
RecordNode temp;
for(i=0;i<pvector->n-1;i++) //做n-1趟选择排序
{
k=i;
for(j=i+1;j<pvector->n;j++) //无序区内找出排序码的最小记录
if(pvector->record[j].key<pvector->record[k].key)
k=j;
if(k!=i) //记录互换
{
temp=pvector->record[i];
pvector->record[i]=pvector->record[k];
pvector->record[k]=temp;
}
}
}
/*以上为书上给出的程序,以下为自己编的主函数*/
void main()
{
int i;
SortObject myobj;
for(i=0;i<20;i++) //产生20个随机数
myobj.record[i].key=rand();
myobj.n=20;
SelectSort(&myobj);
for(i=0;i<20;i++)
printf("%d ",myobj.record[i].key);
}
运行结果:
而传统的C语言程序是:
#include<stdio.h>
typedef int DataType;
void SelectSort(DataType *pvector,int n)
{
int i,j,k;
DataType temp;
for(i=0;i<n-1;i++) //做n-1趟选择排序
{
k=i;
for(j=i+1;j<n;j++) //无序区内找出排序码的最小记录
if(pvector[j]<pvector[k])
k=j;
//if(k!=i) //原语句判断完全多余,k不可能等于i
temp=pvector[i];
pvector[i]=pvector[k];
pvector[k]=temp;
}
}
void main()
{
int i;
int myobj[100];
for(i=0;i<20;i++) //产生20个随机数
myobj[i]=rand();
SelectSort(myobj,20);
for(i=0;i<20;i++)
printf("%d ",myobj[i]);
}
运行结果:

传统C语言程序长度几乎是书上给出的用数据结构+算法程序的一半,而且时间复杂度一样。那为什么要用后者呢,是为了展示数据结构解决问题的方法还是为了展示解决问题的科学严密?














 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









