







J2EE服务端开发编码问题主要集中在两个地方:JSP页面和Servlet程序。
JSP页面:
<%@ page contentType="text/html;charset=UTF-8" pageEncoding="UTF-8" language="java" %>
<html>
<head>
<meta charset="UTF-8">
<title>编码问题</title>
</head>
<body>
</body>
</html>JSP页面中有三个配置编码的地方,但这三个编码各自都有不同的作用。
1、pageEncoding="UTF-8":用于设置JSP文件的编码,JSP引擎会根据这个编码值来解析JSP文件并生成相应的Servlet,所以必须确保这个配置与JSP文件的编码一致,否则在JSP翻译成Servlet的过程中,JSP内的中文字符会被翻译成乱码。
2、contentType="text/html;charset=UTF-8":这个配置会被设置到响应头中,也就是说由JSP生成的Servlet会调用response.setContentType()。客户端浏览器会根据这个配置来解析
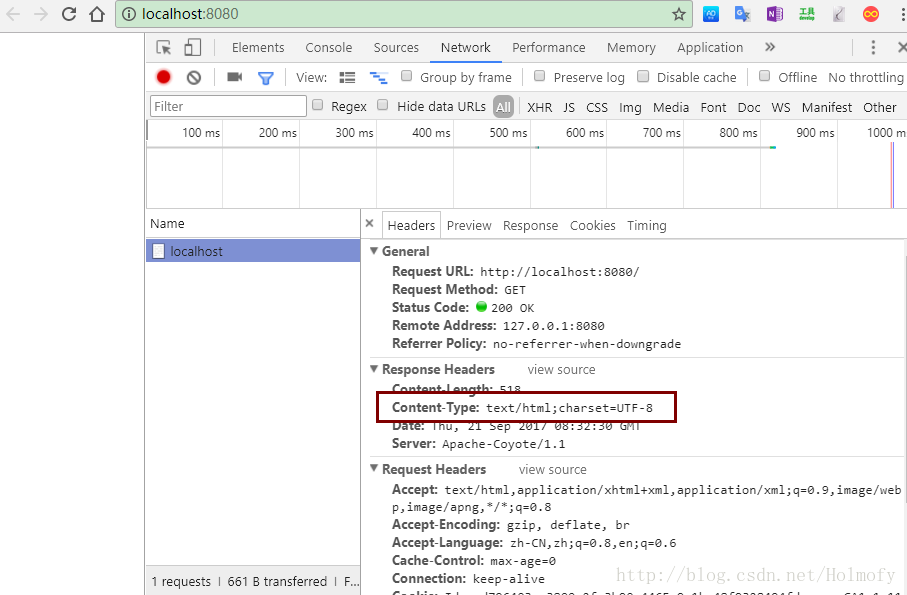
3、<meta charset="UTF-8">:这个是响应体的内容,作用和第二种一样。事实上这只是html5的写法,html4中常用的写法是<meta http-equiv="content-type" content="text/html; charset=UTF-8">。
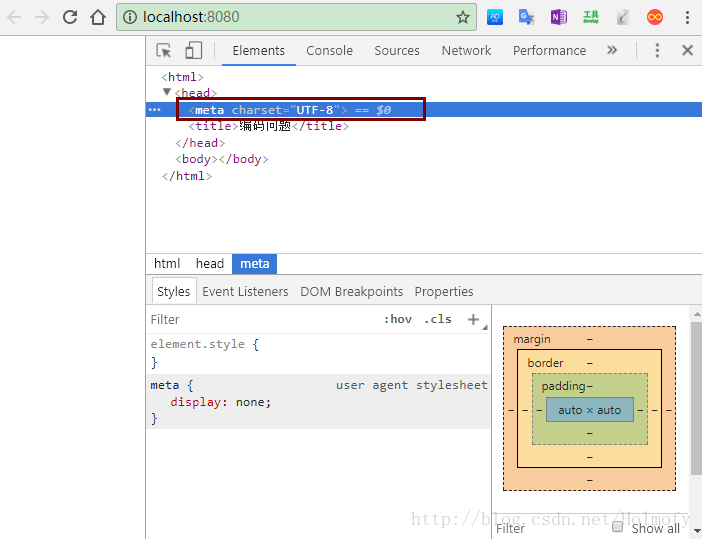
Servlet程序
Servlet程序中出现乱码主要出现在表单提交的时候。GET提交方式与POST提交方式出现乱码原因也各不相同。这里搞两个表单的html分别测试两种情况:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>编码问题</title>
</head>
<body>
<p>get</p>
<form action="test" method="get">
<input type="text" name="username" placeholder="账号">
<input type="text" name="password" placeholder="密码">
<input type="submit">
</form>
<p>post</p>
<form action="test" method="post">
<input type="text" name="username" placeholder="账号">
<input type="text" name="password" placeholder="密码">
<input type="submit">
</form>
</body>
</html>测试get请求
先来测试get方式的请求:
public class TestServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String username = req.getParameter("username");
String password = req.getParameter("password");
System.out.println("username:" + username);
System.out.println("password:" + password);
PrintWriter writer = resp.getWriter();
writer.write("username:" + username + "\n");
writer.write("password:" + password + "\n");
}
}在web.xml中对Servlet进行相应配置:
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="test" version="3.1" xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee
http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd">
<servlet>
<servlet-name>Test</servlet-name>
<servlet-class>cn.hff.servlet.TestServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>Test</servlet-name>
<url-pattern>/test</url-pattern>
</servlet-mapping>
</web-app>测试过程图如下(毫无疑问的出现了乱码,而且服务端乱码和客户端乱码还不一样):
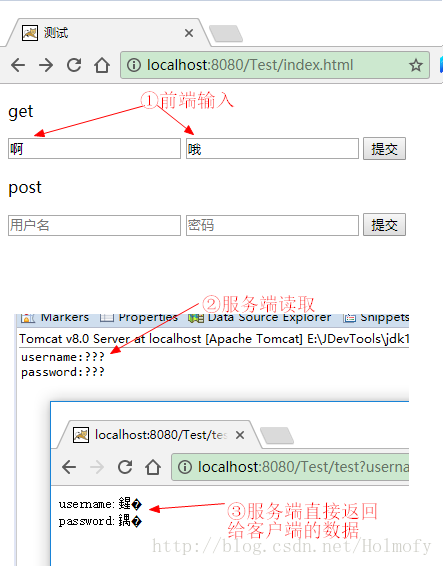
GET请求的过程
在解决这个问题前我们再来熟悉一下GET请求的一些特点
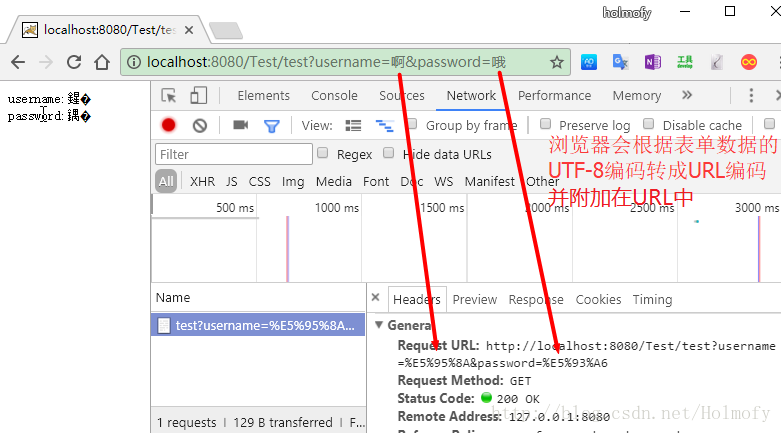
Tomcat8.0之前,默认使用ISO-8859-1编码(西欧8位字符集)去解析URI,所以这就导致使用request.getParameter读取乱码,这就是为什么控制台会打三个问号的原因。
为了解决这个问题我们需要修改Tomcat的conf/server.xml配置文件。找到HTTP/1.1的Connector配置:
<Connector URIEncoding="ISO-8859-1" connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/>第一种方式就是直接把URIEncoding修改成UTF-8:
<Connector URIEncoding="UTF-8" connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/>事实上Tomcat8.0之后
conf/server.xml中的默认URIEncoding就是UTF-8,这里我为了测试改成了Tomcat8.0之前的ISO-8859-1编码
有关于编码的问题可以参考我的这篇文章:从ASCII、ISO-8859、GB2312、GBK到Unicode的UCS-2、UCS-4、UTF-8、UTF-16、UTF-32
第二种方式是让URI的解码方式和请求体解码方式一致:
<Connector useBodyEncodingForURI="true" connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/>同时我们需要在request.getParameter之前将请求体的解码方式设置为UTF-8:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置请求体的编码,对于GET请求需要与useBodyEncodingForURI配合使用
req.setCharacterEncoding("UTF-8");
String username = req.getParameter("username");
String password = req.getParameter("password");
System.out.println("username:" + username);
System.out.println("password:" + password);
PrintWriter writer = resp.getWriter();
writer.write("username:" + username + "\n");
writer.write("password:" + password + "\n");
}官方文档中建议使用第一种URIEncoding的方式。第二种配置方式主要为了兼容 Tomcat 4.1.x之前的版本。
服务端响应过程
进行上面的设置后,虽然服务端的乱码问题解决了,但客户端的响应仍然是乱码。
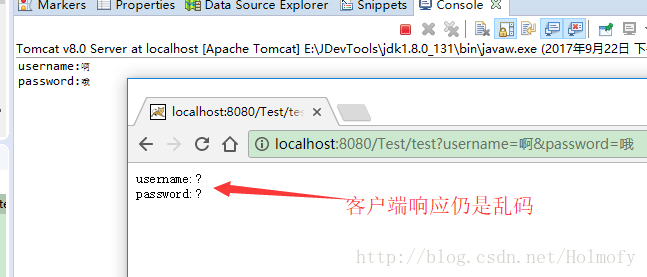
这是因为Tomcat的HTTP响应信息默认也是使用ISO-8859-1编码,我们需要在response.getWriter方法之前调用resp.setCharacterEncoding("UTF-8")将编码值设为UTF-8,同时我们要调用response.setContentType方法让客户端浏览器按照UTF-8的编码方式进行解析。
修改后的代码如下:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String username = req.getParameter("username");
String password = req.getParameter("password");
System.out.println("username:" + username);
System.out.println("password:" + password);
resp.setCharacterEncoding("UTF-8");
// 这里我把MIME type设置为text/plain不同文本格式,为了让\n能正常换行
resp.setContentType("text/plain;charset=UTF-8");
PrintWriter writer = resp.getWriter();
writer.write("username:" + username + "\n");
writer.write("password:" + password + "\n");
//如果将MIME type设置为text/html超文本格式,则需要把\n替换成<br>来达到换行的效果
//resp.setCharacterEncoding("UTF-8");
//resp.setContentType("text/html;charset=UTF-8");
//PrintWriter writer = resp.getWriter();
//writer.write("username:" + username + "<br>");
//writer.write("password:" + password + "<br>");
}测试post请求
public class TestServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String username = req.getParameter("username");
String password = req.getParameter("password");
System.out.println("username:" + username);
System.out.println("password:" + password);
PrintWriter writer = resp.getWriter();
writer.write("username:" + username + "\n");
writer.write("password:" + password + "\n");
}
}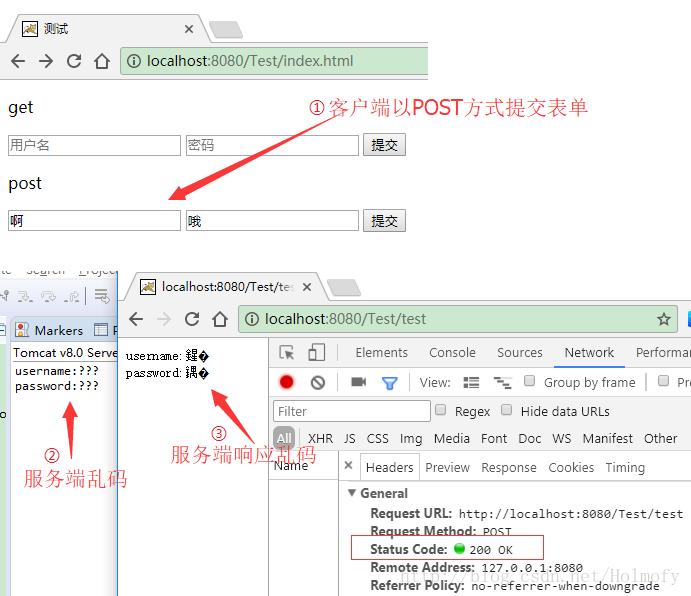
默认情况下和GET请求出现一样的乱码。
POST请求过程
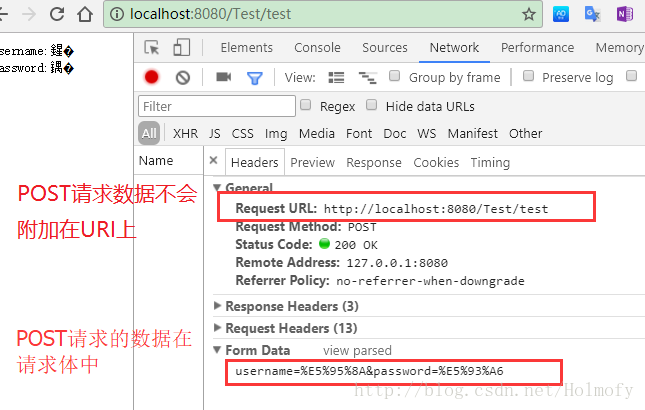
和GET请求不同,POST请求的参数数据存放在请求体中,并没有附加在URI上,所以前面针对GET进行URI的配置就没必要了。因为数据存放在请求体中,所以我们可以直接调用request.setCharsetEncoding方法对请求体的解码方式进行设置:
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 对于POST请求,我们不需要设置URI的解码方式,
// 直接调用request.setCharacterEncoding方法即可
req.setCharacterEncoding("UTF-8");
String username = req.getParameter("username");
String password = req.getParameter("password");
System.out.println("username:" + username);
System.out.println("password:" + password);
// 服务端响应的过程都是一样的,响应过程和GET处理方式一样
resp.setCharacterEncoding("UTF-8");
resp.setContentType("text/plain;charset=UTF-8");
PrintWriter writer = resp.getWriter();
writer.write("username:" + username + "\n");
writer.write("password:" + password + "\n");
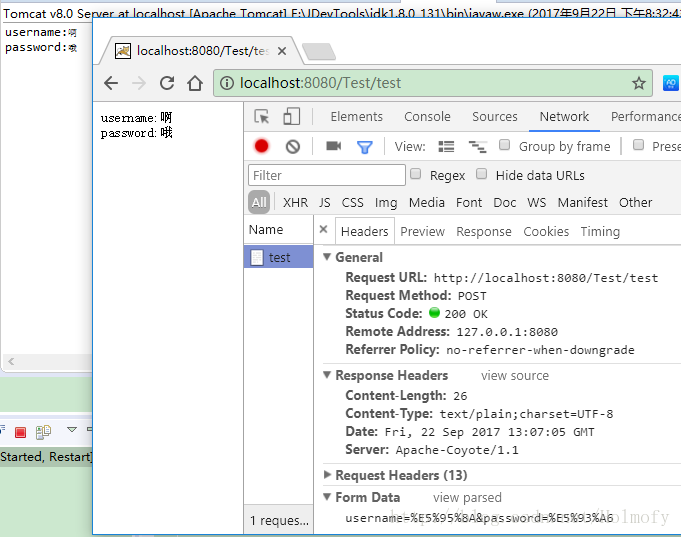
}
自定义过滤器设置编码
每个Servlet调用request.setCharacterEncoding确实很烦,最好的方式就是写一个Filter方便统一管理所有的编码。Filter代码如下:
package cn.hff.filter;
public class UTF8EncodingFilter implements Filter{
public void init(FilterConfig filterConfig) throws ServletException {/*No Operation*/}
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException{
// 设置请求体编码
request.setCharacterEncoding("UTF-8");
// 设置响应体编码
response.setCharacterEncoding("UTF-8");
response.setContentType("text/html;charset=UTF-8");
// 继续执行责任链
chain.doFilter(request, response);
}
public void destroy() {/*No Operation*/}
}然后在web.xml配置下过滤器:
<web-app>
...
<filter>
<filter-name>UTF8Filter</filter-name>
<filter-class>cn.hff.filter.UTF8EncodingFilter</filter-class>
</filter>
<filter-mapping>
<!-- 对所有请求设置请求体编码 -->
<filter-name>UTF8Filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
...
</web-app使用Tomcat内建过滤器设置请求体编码
事实上Tomcat已经实现了上面的过滤器功能,而且过滤器的编码可以自行配置,使用时直接在web.xml中进行如下配置即可:
<web-app>
...
<!-- 请求体编码 -->
<filter>
<filter-name>RequestEncodingFilter</filter-name>
<filter-class>org.apache.catalina.filters.SetCharacterEncodingFilter</filter-class>
<init-param>
<!-- 配置编码 -->
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<async-supported>true</async-supported>
</filter>
<filter-mapping>
<filter-name>RequestEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
...
</web-app>Tomcat的SetCharacterEncodingFilter文档地址:http://tomcat.apache.org/tomcat-8.0-doc/config/filter.html#Set_Character_Encoding_Filter
Tomcat相关源码分析
通过源码看Tomcat解析请求参数的过程
以下源码出自
apache-tomcat-8.0.36-src,该版本源码可以从这里下载,不同版本可能略有差异
请求参数处理相关源码
package org.apache.catalina.connector;
...
/// Request的装饰器
public class RequestFacade implements HttpServletRequest {
...
protected Request request = null;
@Override
public String getParameter(String name) {
...
// 本质上是调用内部被包装对象的getParamter方法
return request.getParameter(name);
}
@Override
public void setCharacterEncoding(String env)
throws java.io.UnsupportedEncodingException {
if (request == null) {
throw new IllegalStateException(
sm.getString("requestFacade.nullRequest"));
}
// 本质上也是调用被包装对象的setCharacterEncoding方法
request.setCharacterEncoding(env);
}
}
//
package org.apache.catalina.connector;
...
/// 实际的Request实现类,也就是被包装的对象
public class Request
implements HttpServletRequest {
...
@Override
public String getParameter(String name) {
if (!parametersParsed) {
parseParameters(); // 已经解析过了就不再解析了
}
return coyoteRequest.getParameters().getParameter(name);
}
protected void parseParameters() {
parametersParsed = true; // 只在第一次获取请求参数的时候解析
// Parameters对象中保存了原始的参数信息
Parameters parameters = coyoteRequest.getParameters();
boolean success = false;
try {
parameters.setLimit(getConnector().getMaxParameterCount());
// 这个编码值可以通过setCharacterEncoding方法设置
String enc = getCharacterEncoding();
// 是否配置了useBodyEncodingForURI
boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI();
if (enc != null) {
parameters.setEncoding(enc);
if (useBodyEncodingForURI) {
// 设置请求参数的编码值
parameters.setQueryStringEncoding(enc);
}
} else {
// /// 默认的编码方式为ISO-8859-1
// public static final String DEFAULT_CHARACTER_ENCODING="ISO-8859-1";
parameters.setEncoding
(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
if (useBodyEncodingForURI) {
// 使用默认编码方式解码
parameters.setQueryStringEncoding
(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
}
}
// 由Parameters对象处理请求参数
parameters.handleQueryParameters();
...// 省略若干代码
}
@Override
public void setCharacterEncoding(String enc)
throws UnsupportedEncodingException {
if (usingReader) { return; }
B2CConverter.getCharset(enc);
// 设置编码
coyoteRequest.setCharacterEncoding(enc);
}
@Override
public String getCharacterEncoding() {
return coyoteRequest.getCharacterEncoding();
}
}
/
package org.apache.tomcat.util.http;
...
public final class Parameters {
public void handleQueryParameters() {
if( didQueryParameters ) { return; }
didQueryParameters=true; // 只进行一次处理
...
try {
// 将原始数据拷贝一份
decodedQuery.duplicate( queryMB );
} catch (IOException e) {
// Can't happen, as decodedQuery can't overflow
e.printStackTrace();
}
// 进行参数处理
processParameters( decodedQuery, queryStringEncoding );
}
public void processParameters( MessageBytes data, String encoding ) {
// 非空判断
if( data==null || data.isNull() || data.getLength() <= 0 ) {
return;
}
if( data.getType() != MessageBytes.T_BYTES ) {
data.toBytes();
}
ByteChunk bc=data.getByteChunk();
// 转成字节进行处理
processParameters( bc.getBytes(), bc.getOffset(),
bc.getLength(), getCharset(encoding));
}
private static final Charset DEFAULT_CHARSET = StandardCharsets.ISO_8859_1;
private Charset getCharset(String encoding) {
// 获取编码,默认为ISO-8859-1编码
if (encoding == null) { return DEFAULT_CHARSET; }
try {
return B2CConverter.getCharset(encoding);
} catch (UnsupportedEncodingException e) {
return DEFAULT_CHARSET;
}
}
// 实际参数处理的代码
private void processParameters(byte bytes[], int start, int len,
Charset charset) {
...
int decodeFailCount = 0;
int pos = start;
int end = start + len;
while(pos < end) {
int nameStart = pos,nameEnd = -1,valueStart = -1,valueEnd = -1;
boolean parsingName = true;
boolean decodeName = false;
boolean decodeValue = false;
boolean parameterComplete = false;
do {
switch(bytes[pos]) {
case '=':
if (parsingName) {
// name部分解析结束,下一个字符开始就是value部分
nameEnd = pos;
parsingName = false;
valueStart = ++pos; // value部分起始位置
} else {
// value中的“=”号
pos++;
}
break;
case '&':
if (parsingName) {
// name部分解析解析结束,该name没有对应的value
nameEnd = pos;
} else {
// value部分解析结束
valueEnd = pos;
}
// 每遇到一个&符号,一个参数的解析结束
parameterComplete = true;
pos++;
break;
case '%':
case '+':
// Decoding required
if (parsingName) {
decodeName = true;
} else {
decodeValue = true;
}
pos ++;
break;
default:
pos ++;
break;
}
} while (!parameterComplete && pos < end);
...// 省略调试信息
// tmpName暂存name部分的相关字节信息
tmpName.setBytes(bytes, nameStart, nameEnd - nameStart);
// tmpValue暂存value部分的相关字节信息
if (valueStart >= 0) {
tmpValue.setBytes(bytes, valueStart, valueEnd - valueStart);
} else {
tmpValue.setBytes(bytes, 0, 0);
}
...// 省略调试信息
try {
String name;
String value;
// name部分的解码
if (decodeName) {
urlDecode(tmpName);
}
tmpName.setCharset(charset);
name = tmpName.toString();
// value部分的解码
if (valueStart >= 0) {
if (decodeValue) {
urlDecode(tmpValue);
}
tmpValue.setCharset(charset);
value = tmpValue.toString();
} else {
value = "";
}
try {
// 将解码出来的name-value对保存起来
addParameter(name, value);
} catch (IllegalStateException ise) {
...//调试信息
}
} catch (IOException e) {
// 调试信息
}
// 回收临时内存
tmpName.recycle();
tmpValue.recycle();
...// 调试信息
}
...// 调试信息
}响应体相关源码
package org.apache.catalina.connector;
...
public class Response implements HttpServletResponse {
public void setCharacterEncoding(String charset) {
if (isCommitted()) { return; }
if (included) { return; }
if (usingWriter) { return; }
// coyoteResponse.setCharacterEncoding
getCoyoteResponse().setCharacterEncoding(charset);
isCharacterEncodingSet = true;
}
public String getCharacterEncoding() {
// 内部会获取characterEncoding,它的默认值为
// Constants.DEFAULT_CHARACTER_ENCODING,即ISO-8859-1
return (getCoyoteResponse().getCharacterEncoding());
}
public PrintWriter getWriter()
throws IOException {
...
if (ENFORCE_ENCODING_IN_GET_WRITER) {
/*
* If the response's character encoding has not been specified as
* described in <code>getCharacterEncoding</code> (i.e., the method
* just returns the default value <code>ISO-8859-1</code>),
* <code>getWriter</code> updates it to <code>ISO-8859-1</code>
* (with the effect that a subsequent call to getContentType() will
* include a charset=ISO-8859-1 component which will also be
* reflected in the Content-Type response header, thereby satisfying
* the Servlet spec requirement that containers must communicate the
* character encoding used for the servlet response's writer to the
* client).
*/
// 默认情况下是ISO-8859-1编码
setCharacterEncoding(getCharacterEncoding());
}
usingWriter = true;
// checkConverter中会调用coyoteResponse.getCharacterEncoding();
// 获取编码配置
outputBuffer.checkConverter();
if (writer == null) {
// 创建Writer对象
writer = new CoyoteWriter(outputBuffer);
}
return writer;
}
}













 2646
2646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









