







为什么需要集群管理与调度
上文我们简单介绍了深度学习、分布式CPU+GPU集群的实现原理,以及分布式深度学习的原理,我们简单回顾一下:
分布式CPU+GPU集群的实现:
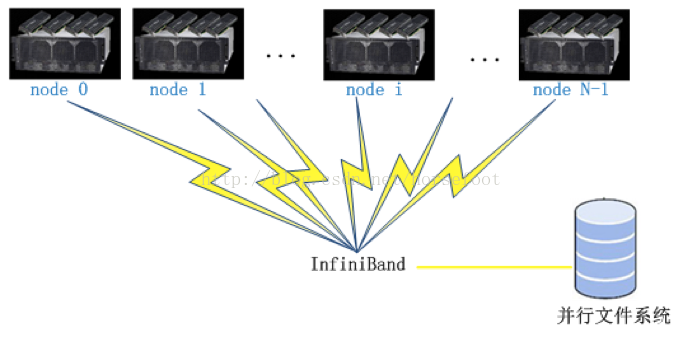
GPU集群并行模式即为多GPU并行中各种并行模式的扩展,如上图所示。节点间采用InfiniBand通信,节点间的GPU通过RMDA通信,节点内多GPU之间采用基于infiniband的通信。
分布深度学习框架的实现:
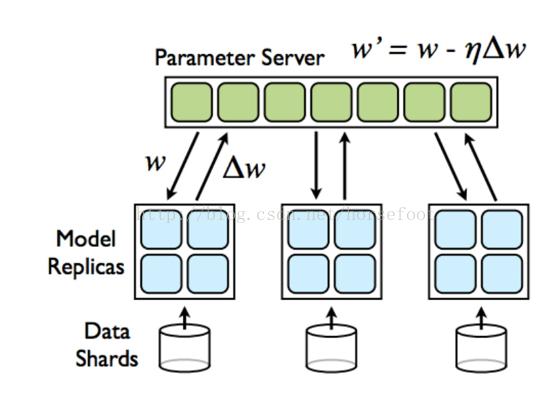
如下图所示,在tensorflow中,计算节点称做worker节点,Worker节点主要完成模型的训练与计算。参数服务器可以是多台机器组成的集群,类似分布式的存储架构,涉及到数据的同步,一致性等等, 一般是key-value的形式,可以理解为一个分布式的key-value内存数据库,然后再加上一些参数更新的操作,采取这种方式可以几百亿的参数分散到不同的机器上去保存和更新,解决参数存储和更新的性能问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4728
4728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









