









提到数据挖掘,我们第一反应就是之前听到的啤酒和尿不湿的故事,该故事就是典型的数据挖掘中的关联规则。购物篮分析区别于传统的线性回归的主要区别为,关联分析针对离散数据;
常见关联规则:
关联规则:牛奶=>鸡蛋【支持度=2%,置信度=60%】
支持度:分析中的全部事务的2%同时购买了牛奶和鸡蛋,需设定域值,来限定规则的产生;
置信度:购买了牛奶的筒子有60%也购买了鸡蛋,需设定域值,来限定规则的产生;
最小支持度阈值和最小置信度阈值:由挖掘者或领域专家设定。
与关联分析相关的专业术语包括:
项集:项(商品)的集合
k-项集:k个项组成的项集
频繁项集:满足最小支持度的项集,频繁k-项集一般记为Lk
强关联规则:满足最小支持度阈值和最小置信度阈值的规则
接下来以两步法为例,揭秘下关联分析的做法:
如下有9个购物篮(T100-T900):两步法先找出所有的频繁项集;第二步再由频繁项集产生强关联规则。

算法步骤:
Step1:扫描D,对每个候选项计数,生成候选1-项集C1,并算出每项的关联度计数(即该项出现的频数);
Step2:定义最小支持度阀值为2(即剔除频数低于2的项),记剩余的项集为L1;
Step3:由L1 两两配对生成新的2-项集C2;
Step4:扫描D,对C2里每个项计数,定义最小支持度阀值为2(即剔除频数低于2的项),记剩余的项集为2-项集L2;
Step5:由L2 两两配对生成新的3-项集C3;
……如此循环,直至出现最大的n-项集结束;
以上述例子为例,图解过程如下:
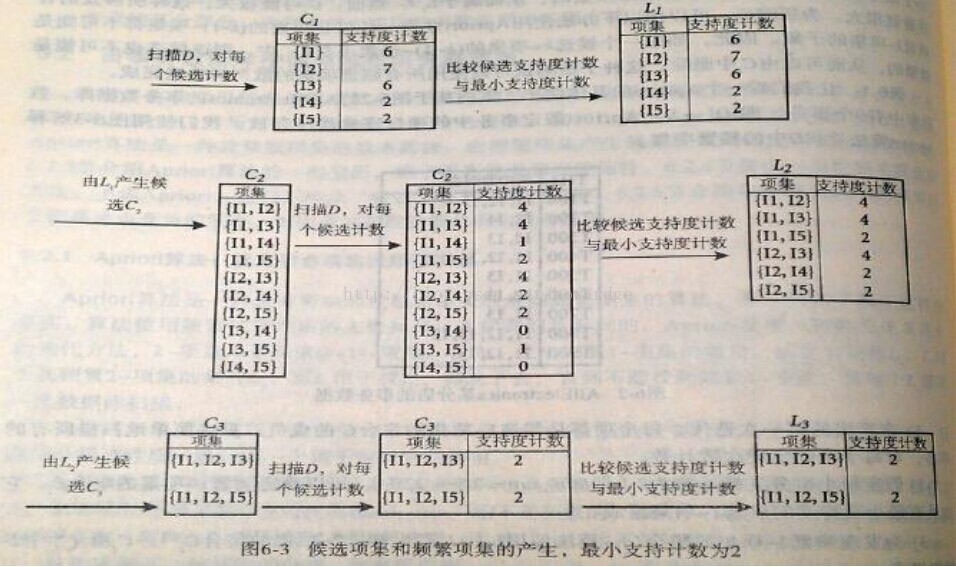
如图为例,我们计算频繁项集{I1,I2,I5},可以发现I1^I2=>I5,由于{I1,I2,I5}出现了2次,{I1,I2}出现了4次,故置信度为2/4=50%
类似可以算出:
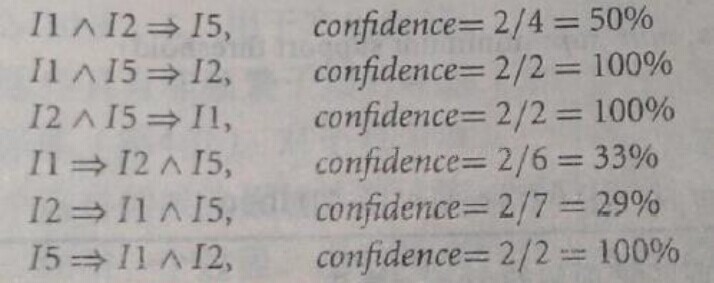
利用R进行购物篮分析,R中关联分析函数为arules,我们采用内置的Groceries的数据集(如下);
Inspect(Groceries)

具体的R语言实现如下:
library(arules)
data(Groceries)
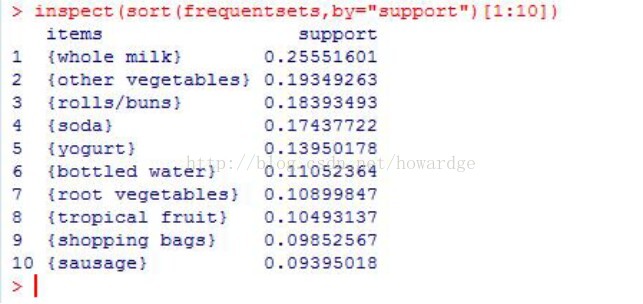
frequentsets=eclat(Groceries,parameter=list(support=0.05,maxlen=10))
inspect(sort(frequentsets,by="support")[1:10]) #根据支持度对求得的频繁项集排序
结果如下:可见所有的关联规则的排名:
接下来以阀值挑选我们的需要的关联项:
rules=apriori(Groceries,parameter=list(support=0.01,confidence=0.5))
inspect(rules)

由此可见购物篮就完成,其中lift是相关度指标,lift=1表示L和R独立,lift越大表明L和R在同一购物篮绝非偶尔现象,更加支持我们的购物篮决策。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









