







k-means原理
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
问题
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,K-Means算法被用来找出这几个点群。

算法概要
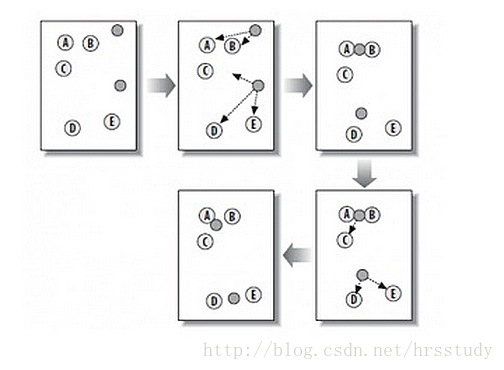
从上图中,我们可以看到,A, B, C, D, E 是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
随机在图中取K(这里K=2)个种子点。
然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
k-means算法缺点
1、需要提前指定k
2、k-means算法对种子点的初始化非常敏感
k-means++算法
k-means++是选择初始种子点的一种算法,其基本思想是:初始的聚类中心之间的相互距离要尽可能的远。
方法如下:
1.从输入的数据点集合中随机选择一个点作为第一个聚类中心
2.对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3.选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4.重复2和3直到k个聚类中心被选出来
5.利用这k个初始的聚类中心来运行标准的k-means算法
第2、3步选择新点的方法如下:
a.对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
b.然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先用Sum(D(x))乘以随机值Random得到值r,然后用currSum += D(x),直到其currSum>r,此时的点就是下一个“种子点”。原因见下图:

假设A、B、C、D的D(x)如上图所示,当算法取值Sum(D(x))*random时,该值会以较大的概率落入D(x)较大的区间内,所以对应的点会以较大的概率被选中作为新的聚类中心。
k-means 计算 anchor boxes
根据YOLOv2的论文,YOLOv2使用anchor boxes来预测bounding boxes的坐标。YOLOv2使用的anchor boxes和Faster R-CNN不同,不是手选的先验框,而是通过k-means得到的。
YOLO的标记文件格式如下:
<object-class> <x> <y> <width> <height>
object-class是类的索引,后面的4个值都是相对于整张图片的比例。
x是ROI中心的x坐标,y是ROI中心的y坐标,width是ROI的宽,height是ROI的高。
卷积神经网络具有平移不变性,且anchor boxes的位置被每个栅格固定,因此我们只需要通过k-means计算出anchor boxes的width和height即可,即object-class,x,y三个值我们不需要。
由于从标记文件的width,height计算出的anchor boxes的width和height都是相对于整张图片的比例,而YOLOv2通过anchor boxes直接预测bounding boxes的坐标时,坐标是相对于栅格边长的比例(0到1之间),因此要将anchor boxes的width和height也转换为相对于栅格边长的比例。转换公式如下:
w=anchor_width*input_width/downsamples
h=anchor_height*input_height/downsamples
例如:
卷积神经网络的输入为416*416时,YOLOv2网络的降采样倍率为32,假如k-means计算得到一个anchor box的anchor_width=0.2,anchor_height=0.6,则:
w=0.2*416/32=0.2*13=2.6
h=0.6*416/32=0.6*13=7.8
距离公式
因为使用欧氏距离会让大的bounding boxes比小的bounding boxes产生更多的error,而我们希望能通过anchor boxes获得好的IOU scores,并且IOU scores是与box的尺寸无关的。
为此作者定义了新的距离公式:
d(box,centroid)=1−IOU(box,centroid)
在计算anchor boxes时我们将所有boxes中心点的x,y坐标都置为0,这样所有的boxes都处在相同的位置上,方便我们通过新距离公式计算boxes之间的相似度。
代码实现
计算anchor boxes的python工具已上传至GitHub:
https://github.com/PaulChongPeng/darknet/blob/master/tools/k_means_yolo.py
k_means_yolo.py代码如下:
# coding=utf-8
# k-means ++ for YOLOv2 anchors
# 通过k-means ++ 算法获取YOLOv2需要的anchors的尺寸
import numpy as np
# 定义Box类,描述bounding box的坐标
class Box():
def __init__(self, x, y, w, h):
self.x = x
self.y = y
self.w = w
self.h = h
# 计算两个box在某个轴上的重叠部分
# x1是box1的中心在该轴上的坐标
# len1是box1在该轴上的长度
# x2是box2的中心在该轴上的坐标
# len2是box2在该轴上的长度
# 返回值是该轴上重叠的长度
def overlap(x1, len1, x2, len2):
len1_half = len1 / 2
len2_half = len2 / 2
left = max(x1 - len1_half, x2 - len2_half)
right = min(x1 + len1_half, x2 + len2_half)
return right - left
# 计算box a 和box b 的交集面积
# a和b都是Box类型实例
# 返回值area是box a 和box b 的交集面积
def box_intersection(a, b):
w = overlap(a.x, a.w, b.x, b.w)
h = overlap(a.y, a.h, b.y, b.h)
if w < 0 or h < 0:
return 0
area = w * h
return area
# 计算 box a 和 box b 的并集面积
# a和b都是Box类型实例
# 返回值u是box a 和box b 的并集面积
def box_union(a, b):
i = box_intersection(a, b)
u = a.w * a.h + b.w * b.h - i
return u
# 计算 box a 和 box b 的 iou
# a和b都是Box类型实例
# 返回值是box a 和box b 的iou
def box_iou(a, b):
return box_intersection(a, b) / box_union(a, b)
# 使用k-means ++ 初始化 centroids,减少随机初始化的centroids对最终结果的影响
# boxes是所有bounding boxes的Box对象列表
# n_anchors是k-means的k值
# 返回值centroids 是初始化的n_anchors个centroid
def init_centroids(boxes,n_anchors):
centroids = []
boxes_num = len(boxes)
centroid_index = np.random.choice(boxes_num, 1)
centroids.append(boxes[centroid_index])
print(centroids[0].w,centroids[0].h)
for centroid_index in range(0,n_anchors-1):
sum_distance = 0
distance_thresh = 0
distance_list = []
cur_sum = 0
for box in boxes:
min_distance = 1
for centroid_i, centroid in enumerate(centroids):
distance = (1 - box_iou(box, centroid))
if distance < min_distance:
min_distance = distance
sum_distance += min_distance
distance_list.append(min_distance)
distance_thresh = sum_distance*np.random.random()
for i in range(0,boxes_num):
cur_sum += distance_list[i]
if cur_sum > distance_thresh:
centroids.append(boxes[i])
print(boxes[i].w, boxes[i].h)
break
return centroids
# 进行 k-means 计算新的centroids
# boxes是所有bounding boxes的Box对象列表
# n_anchors是k-means的k值
# centroids是所有簇的中心
# 返回值new_centroids 是计算出的新簇中心
# 返回值groups是n_anchors个簇包含的boxes的列表
# 返回值loss是所有box距离所属的最近的centroid的距离的和
def do_kmeans(n_anchors, boxes, centroids):
loss = 0
groups = []
new_centroids = []
for i in range(n_anchors):
groups.append([])
new_centroids.append(Box(0, 0, 0, 0))
for box in boxes:
min_distance = 1
group_index = 0
for centroid_index, centroid in enumerate(centroids):
distance = (1 - box_iou(box, centroid))
if distance < min_distance:
min_distance = distance
group_index = centroid_index
groups[group_index].append(box)
loss += min_distance
new_centroids[group_index].w += box.w
new_centroids[group_index].h += box.h
for i in range(n_anchors):
new_centroids[i].w /= len(groups[i])
new_centroids[i].h /= len(groups[i])
return new_centroids, groups, loss
# 计算给定bounding boxes的n_anchors数量的centroids
# label_path是训练集列表文件地址
# n_anchors 是anchors的数量
# loss_convergence是允许的loss的最小变化值
# grid_size * grid_size 是栅格数量
# iterations_num是最大迭代次数
# plus = 1时启用k means ++ 初始化centroids
def compute_centroids(label_path,n_anchors,loss_convergence,grid_size,iterations_num,plus):
boxes = []
label_files = []
f = open(label_path)
for line in f:
label_path = line.rstrip().replace('images', 'labels')
label_path = label_path.replace('JPEGImages', 'labels')
label_path = label_path.replace('.jpg', '.txt')
label_path = label_path.replace('.JPEG', '.txt')
label_files.append(label_path)
f.close()
for label_file in label_files:
f = open(label_file)
for line in f:
temp = line.strip().split(" ")
if len(temp) > 1:
boxes.append(Box(0, 0, float(temp[3]), float(temp[4])))
if plus:
centroids = init_centroids(boxes, n_anchors)
else:
centroid_indices = np.random.choice(len(boxes), n_anchors)
centroids = []
for centroid_index in centroid_indices:
centroids.append(boxes[centroid_index])
# iterate k-means
centroids, groups, old_loss = do_kmeans(n_anchors, boxes, centroids)
iterations = 1
while (True):
centroids, groups, loss = do_kmeans(n_anchors, boxes, centroids)
iterations = iterations + 1
print("loss = %f" % loss)
if abs(old_loss - loss) < loss_convergence or iterations > iterations_num:
break
old_loss = loss
for centroid in centroids:
print(centroid.w * grid_size, centroid.h * grid_size)
# print result
for centroid in centroids:
print("k-means result:\n")
print(centroid.w * grid_size, centroid.h * grid_size)
label_path = "/raid/pengchong_data/Data/Lists/paul_train.txt"
n_anchors = 5
loss_convergence = 1e-6
grid_size = 13
iterations_num = 100
plus = 0
compute_centroids(label_path,n_anchors,loss_convergence,grid_size,iterations_num,plus)
参考
http://coolshell.cn/articles/7779.html
http://www.cnblogs.com/shelocks/














 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









