






正则表达式(re=regular expression)
通配符
. 当前目录
.. 当前目录的上一级目录
* 0个或多个字符
? 一个任意字符
[[:digit:]]
[[:space:]]
特殊的符号
一个完整的正则使用过程
match 方法是从左往右依次匹配的
如果没有找到匹配, 则返回 None
import re
a = re.match(r"westos", "westoshello")
print a.group()
a = re.match(r"westos", "hellowestoshello")
print a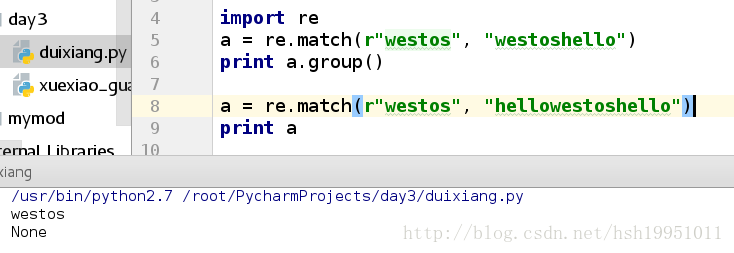
\d 单个数字
\D \d的取反 , 除了数字之外import re
a = re.match(r"\d", "1")
a.group()
print a.group()
a = re.match(r'\d', "w11")
print a
a = re.match(r"\D", "w11")
print a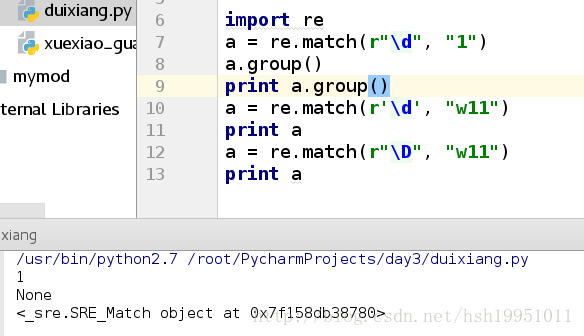
\s 匹配空格, \n, \t,\r
import re
a = re.match(r"\s", "\tw11")
print a
a = re.match(r"\S", "aa\tw11")
print a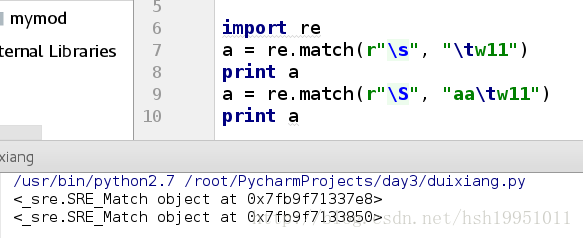
\w(word): 匹配字母, 数字或者下划线
import re
a = re.match(r"\w", "wessstos")
print a
a = re.match(r"\w", "122wessstos")
print a
a = re.match(r"\w", "__wessstos")
print a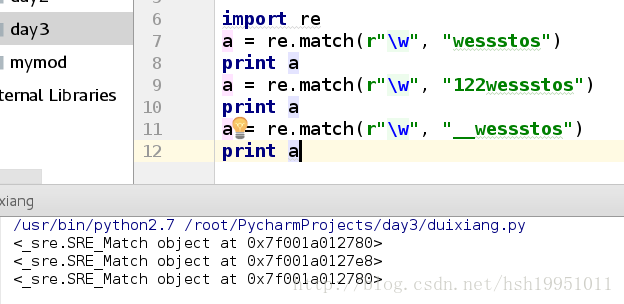
表示数量
* 匹配前一个字符出现0次或无限次, 即可有可无, {0,}
+ 匹配前一个字符出现1次或无限次,即至少出现一次, {1,}
? 匹配前一个字符出现1次或0次,即前面的字符可省略, {0,1}
{m} 匹配前一个字符出现m次
{m,} 匹配前一个字符至少出现m次
{m,n} 匹配前一个字符出现m次到n次
表示边界
^ : 以什么开头
$ : 以什么结尾
应用: 匹配电话号
import re
ree = r"1\d{2}-*\d{4}-*\d{4}$"
ii = ["13187279372", "172883722111", "132-2232-3345", "13348o039l2"]
for i in ii:
a = re.match(ree, i)
if a:
print "%s合法" %(i)
else:
print "%s不合法" %(i)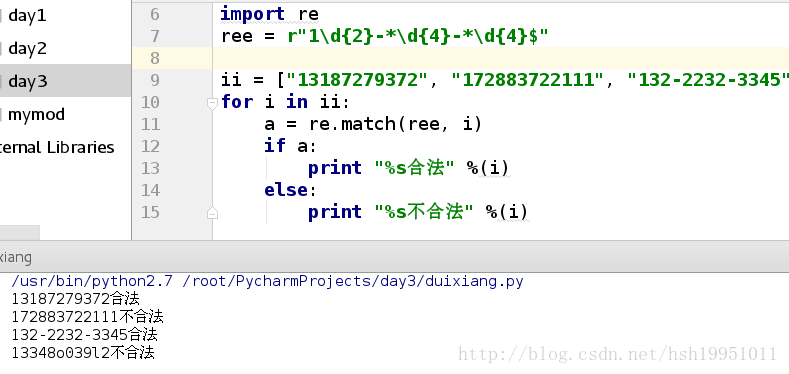
表示分组
| : 匹配| 左右任意一个表达式即可;
(ab): 将括号中的字符作为一个分组
\num: 引用分组第num个匹配到的字符串
(?P): 分组起别名
(?P=name) : 引用分组的别名
应用: 匹配出0-100之间的数字, 包括0和100
import re
reg = r"^0$|^100$|[1-9]\d?$"
while 1:
i = raw_input("请输入0-100之间的数字:")
if re.match(reg, i):
print "%s正确" %(i)
else:
print "%s不正确" %(i)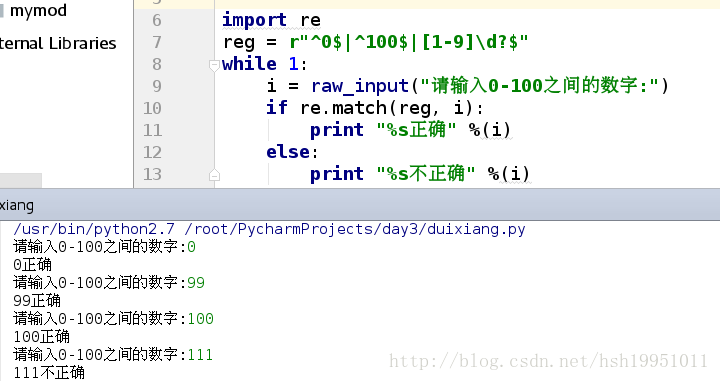
groups以元组方式返回符和条件的分组
import re
mailList =["aa@qq.com", "westos@qq.com", "12fg5@westos.com", "aa@qq.com"
"1westos@qq.com", "1f2fg5@qq.com"]
def mail_user_name(mail_name):
reg = r"(\w{4,20})@(qq.com)$"
a = re.match(reg, mail_name)
print a.groups()
return a.group()
print mail_user_name("westos@qq.com")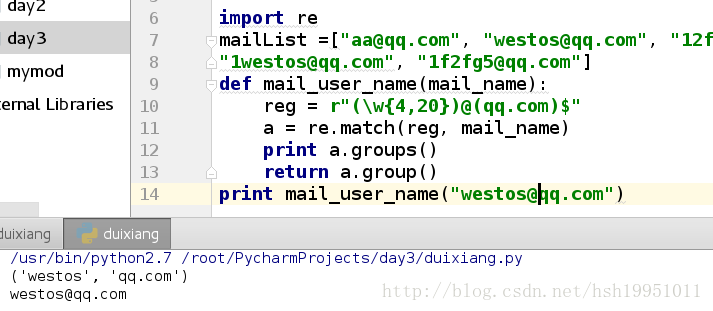
re高级用法
search()方法: 只找到符和条件的第一个并返回;
import re
s = "阅读次数为1000, 转发次数为100"
reg = r"\d+"
a = re.search(reg, s)
print a.group()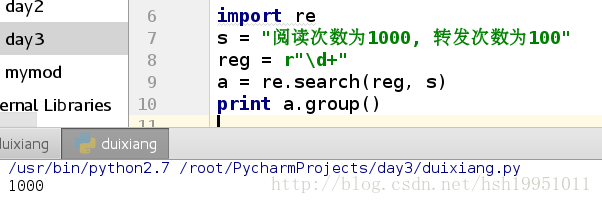
findall()方法: 返回符合条件的所有内容;
import re
s = "阅读次数为1000, 转发次数为100"
reg = r"\d+"
print re.findall(reg, s)
sub()方法: 对符合正则的内容进行替换;
import re
s = "阅读次数为1000, 转发次数为100"
reg = r"\d+"
print re.sub(reg, '0' , s)
split()方法: 指定多个分隔符进行分割;
import re
s = "van 22:112233"
print re.split(r":| ", s)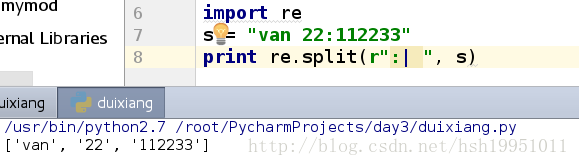
python贪婪和非贪婪
非贪婪模式, 总是匹配尽可能少的字符;
*, ?,+, {m,n}后面加上?, 使得贪婪模式编程非贪婪模式;
import re
s = "This is a number 111-234-22-456"
r = re.match(r".+(\d+-\d+-\d+-\d+)", s)
print r.group(1)
默认情况下 python 正则是贪婪模式的;
r = re.match(r".+?(\d+-\d+-\d+-\d+)", s)
print r.group(1)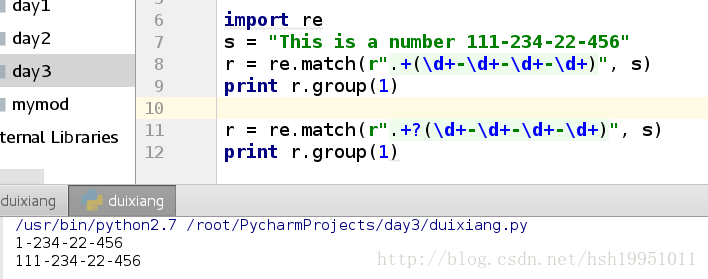














 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









