







上文文:一共介绍2种简单的中文分词,本人采用的是最新的solr4.9.0版本。
1:solr搜索引擎(4.9.0)本身只带中文分词器。建议初接触搜索引擎的采用这个方案,该分词器源码用java写的。
首先将下载解压后的solr-4.9.0的目录里面F:\大数据\solr\tools\solr-4.9.0\contrib\analysis-extras\lucene-libs找到lucene-analyzers-smartcn-4.9.0.jar文件
把这个分词jar包拷贝到项目中。
第二步,配置schema.xml文件,把这个jar包加载到配置文件中。
<fieldType name="text_solr" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<!-- 此处需要配置主要的分词类 -->
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<!--
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
-->
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<!-- 此处配置同上 -->
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<!--
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
-->
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType>
配置之后 重启服务器。访问solr--从网上借了个图。。不得不说现在的solr4.9版本很先进了。当初公司用的solr3.6 一把眼泪的。。如下图:
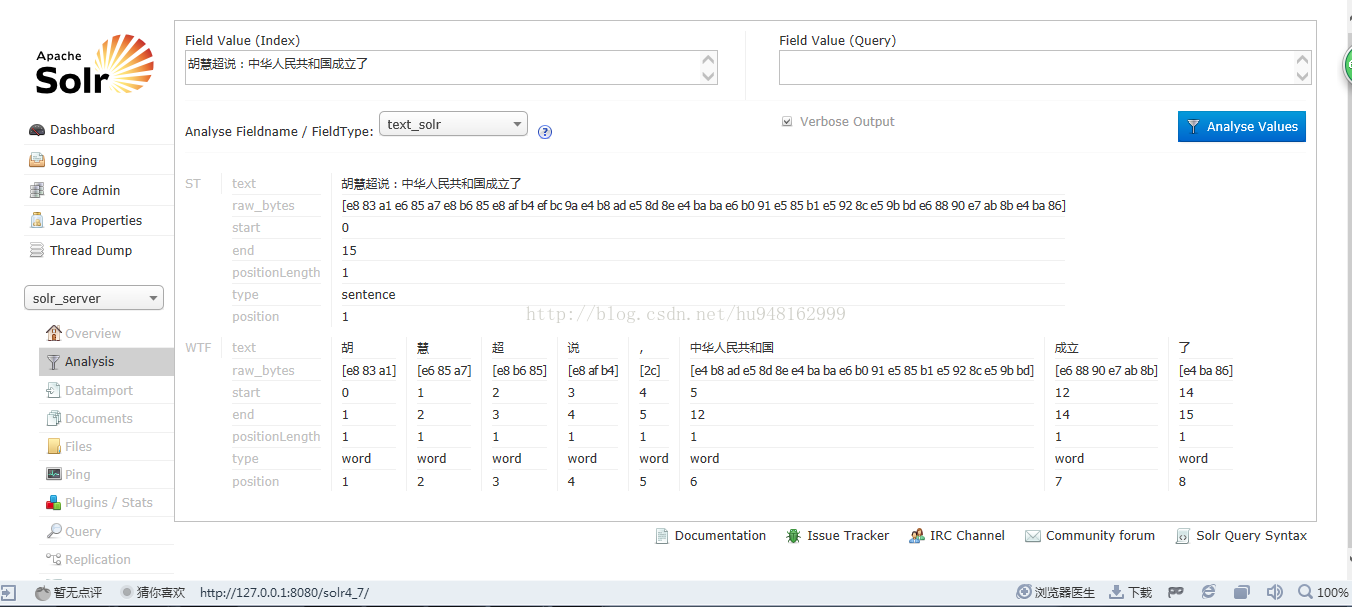
刚我做了一个小测试。从上图来看,看这7个字‘中华人民共和国’这7个字明显没有分词切割。分析其分词效果,可以发现这条语句分词效果不是很。。。可见自带的分词器的算法不是很... 一般自带都能理解。咱就不对其算法进行分析了。
2:接下来我们分析用的比较多的开源中文分词器IK Analysis
lucene的分词基类是Analyzer,所以IK提供了Analyzer的一个实现类IKAnalyzer。首先,我们要实例化一个IKAnalyzer,它有一个构造方法接收一个参数isMaxWordLength,这个参数是标识IK是否采用最大词长分词,还是采用最细粒度切分两种分词算法。实际两种算法的实现,最大词长切分是对最细粒度切分的一种后续处理,是对最细粒度切分结果的过滤,选择出最长的分词结果。
IK 分词算法理解
根据作者官方说法 IK 分词器采用“正向迭代最细粒度切分算法”, 分析它 的源代码, 可以看到分词工具类 IKQueryParser 起至关重要的作用, 它对搜索 关键词采用从最大词到最小词层层迭代检索方式切分,比如搜索词:“中华人 民共和国成立了”, 首先到词库中检索该搜索词中最大分割词, 即分割为: “中 华人民共和国”和“成立了”, 然后对“中华人民共和国”切分为“中华人民”和“人 民共和国”,以此类推。最后,“中华人民共和国成立了”切分为:“中华人民 | 中华 | 华人 | 人民 | 人民共和国 | 共和国 | 共和 | 成立 | 立了”,当然, 该切分方式为默认的细粒度切分,若按最大词长切分,结果为:“中华人民共 和国 | 成立 | 立了”。
solr中,可以搭建很多种分词器。。只需要在之前配置的那个schema.xml文件中追加就行。配置方式大同小异。在网上下载最新的ik分词器,本人采用的是IK Analyzer 2012FF_hf1.zip
http://pan.baidu.com/s/1jGmR9iA
1、将IKAnalyzer2012FF_u1.jar放入webapps\solr\WEB-INF\lib下。
2、将IKAnalyzer配置文件IKAnalyzer.cfg.xml和stopword.dic放入webapps\solr\WEB-INF\classes目录下。
3、在schema.xml中添加IKAnalyzer配置,如下
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
重启服务。发现:
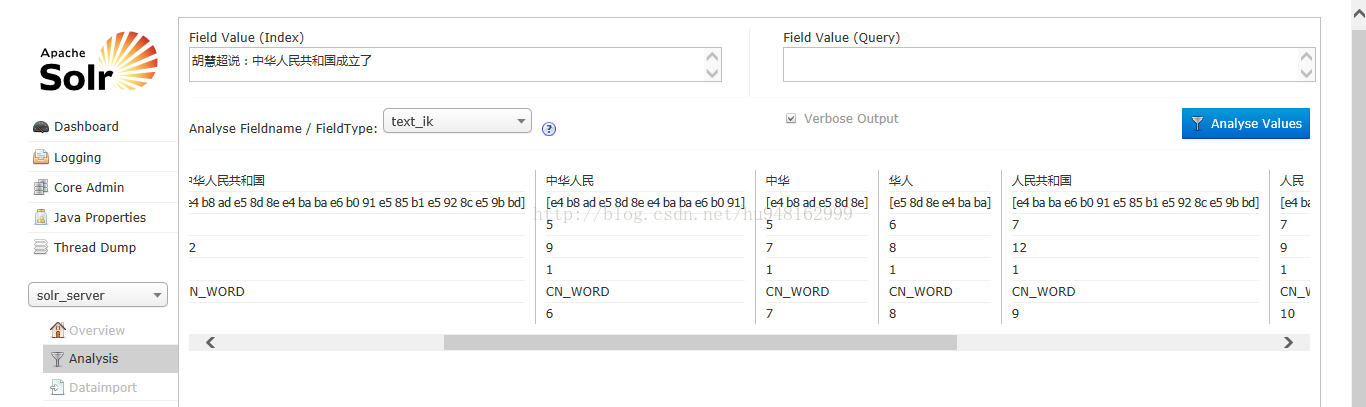
中华人民共和国这7个字 分词效果极为明显,被分为各种常用的词组。具体算法下下次咱分析其源码。














 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









