







0、参考文献
[1]见微知著 http://geek.csdn.net/news/detail/191718
[2]Cyiano http://blog.csdn.net/Cyiano/article/details/72081855
1、概要
细粒度图像识别是现在图像分类中一个颇具挑战性的任务,它的目标是在一个大类中的数百数千个子类中正确识别目标。
相同的子类中物体的动作姿态可能大不相同,不同的子类中物体可能又有着相同的动作姿态,这是识别的一大难点。
细粒度图像分类的关键点在寻找一些存在细微差别的局部区域。
如何有效地对前景对象进行检测,并从中发现重要的局部区域信息,成为了细粒度图像分类算法要解决的关键问题。
对细粒度分类模型,可以按照其使用的监督信息的强弱,分为“基于强监督信息的分类模型”和“基于弱监督信息的分类模型”两大类。
2、基于强监督信息的细粒度图像分类模型
所谓“强监督细粒度图像分类模型”是指:在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(Object Bounding Box)和部位标注点(Part Annotation)等额外的人工标注信息,如图所示。
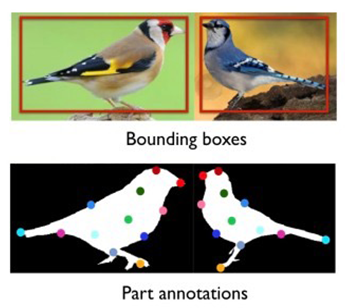
1)Part-based R-CNN 《Part-based R-CNNs for Fine-grained Category Detection》
Part-based R-CNN就是利用R-CNN算法对细粒度图像进行物体级别(例如鸟类)与其局部区域(头、身体等部位)的检测,其总体流程如图所示。
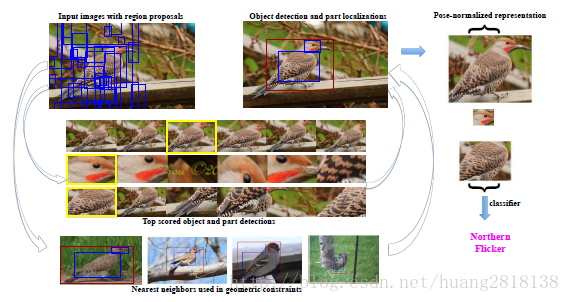
首先利用Selective Search等算法在细粒度图像中产生物体或物体部位可能出现的候选框(Object Proposal)。
之后用类似于R-CNN做物体检测的流程,借助细粒度图像中的Object Bounding Box和Part Annotation可以训练出三个检测模型(Detection Model):一个对应细粒度物体级别检测;一个对应物体头部检测;另一个则对应躯干部位检测。
然后,对三个检测模型得到的检测框加上位置几何约束,例如,头部和躯干的大体方位,以及位置偏移不能太离谱等。这样便可得到较理想的物体/部位检测结果(如图右上)。
接下来将得到的图像块(Image Patch)作为输入,分别训练一个CNN,则该CNN可以学习到针对该物体/部位的特征。
最终将三者的全连接层特征级联(Concatenate)作为整张细粒度图像的特征表示。
显然,这样的特征表示既包含全部特征(即物体级别特征),又包含具有更强判别性的局部特征(即部位特征:头部特征/躯干特征),因此分类精度较理想。但在Part-based R-CNN中,不仅在训练时需要借助Bounding Box和Part Annotation,为了取得满意的分类精度,在测试时甚至还要求测试图像提供Bounding Box。这便限制了Part-based R-CNN在实际场景中的应用。
2)Pose Normalized CNN 《Bird Species Categorization Using Pose Normalized Deep Convolutional Nets》
有感于Part-based R-CNN,S. Branson等人提出在用DPM算法得到Part Annotation的预测点后同样可以获得物体级别和部位级别的检测框,如图所示。
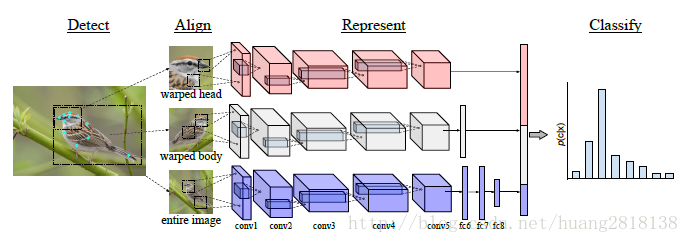
与之前工作不同的是,Pose Normalized CNN对部位级别图像块做了姿态对齐操作。此外,由于CNN不同层的特征具有不同的表示特性(如浅层特征表示边缘等信息,深层特征更具高层语义),该工作还提出应针对细粒度图像不同级别的图像块,提取不同层的卷积特征。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2667
2667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









