







win7(64位)平台下Cygwin+Eclipse搭建Hadoop单机开发环境 (一) Cygwin(64位)的安装 + ssh的配置
win7(64位)平台下Cygwin+Eclipse搭建Hadoop单机开发环境 (二) Hadoop的安装
win7(64位)平台下Cygwin+Eclipse搭建Hadoop单机开发环境 (三) 在Eclipse中配置Hadoop
win7(64位)平台下Cygwin+Eclipse搭建Hadoop单机开发环境 (四) 导入Hadoop源码+wordcount程序+运行
=========================================================================================
Hadoop是开源项目,我们当然想能够边编写自己的程序,又能学习Hadoop的源码啦。(当然,做到这,可以直接在MyEclipse里面创建mapreduce项目了,但这个不是本篇的内容了。)在开始之前,请确保已经在Cygwin terminal中,start-up.sh了Hadoop。
1、在MyEclipse新建一java项目 “MyHadoop”
2、选中新建的项目 ——> “build path” ——> “Configure build path” ——> 选中"Libraries" ——> “add external jars”
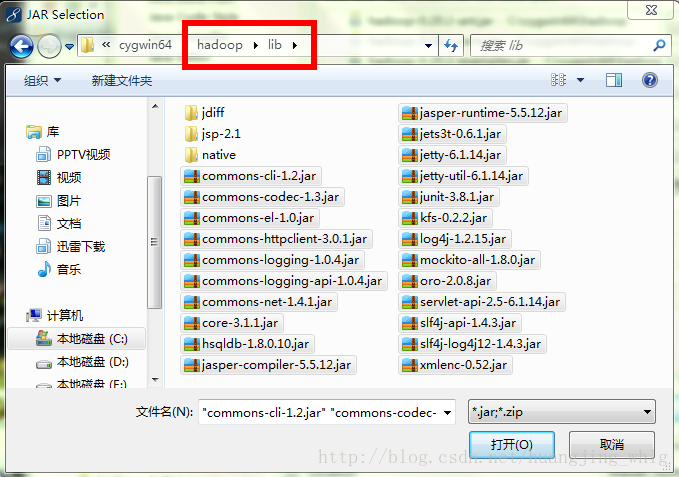
将以上这些都添加到所建项目的路径里面。
3、选中“Source”选项卡,将Hadoop的几个重要的源文件包加入进去
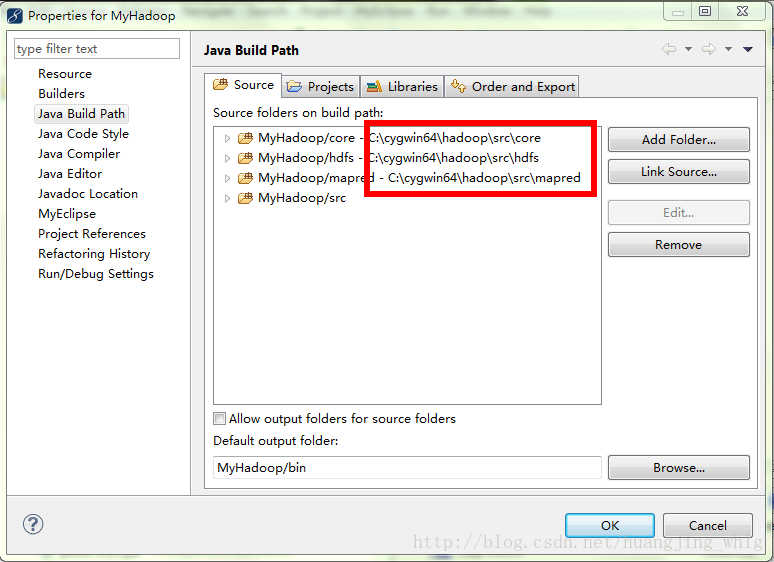
4、将C:\cygwin64\hadoop\src\examples\org\apache\hadoop\examples\WordCount.java拷贝过来,调整一下源码,使不报错为止。
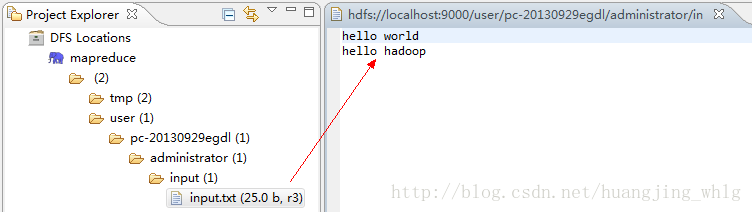
5、准备hdfs文件,过程略(用Hadoop fs put)。
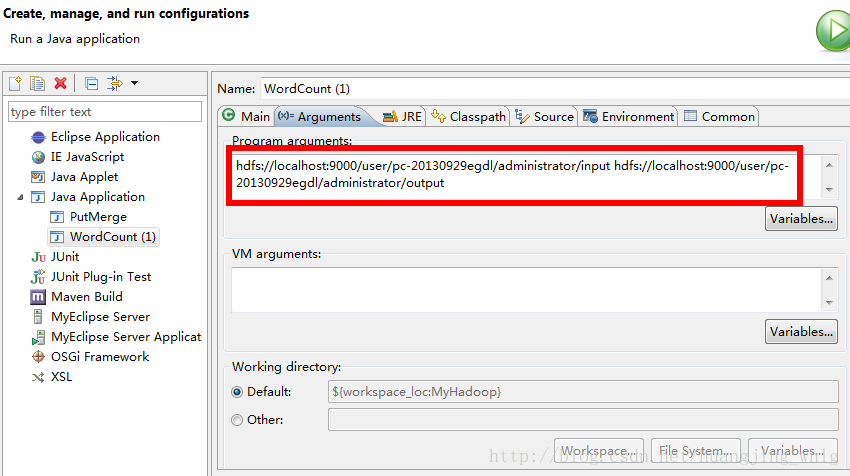
6、配置WordCount运行参数
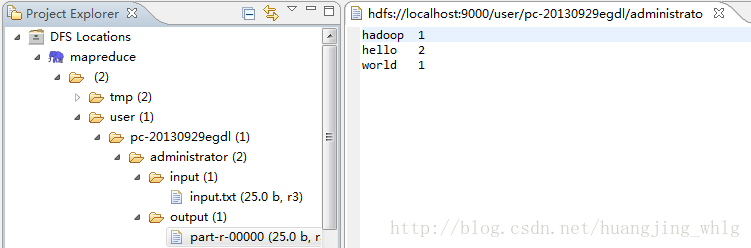
7、运行
14/09/12 13:25:21 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
14/09/12 13:25:22 WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
14/09/12 13:25:22 INFO input.FileInputFormat: Total input paths to process : 1
14/09/12 13:25:22 INFO mapred.JobClient: Running job: job_local_0001
14/09/12 13:25:22 INFO input.FileInputFormat: Total input paths to process : 1
14/09/12 13:25:22 INFO mapred.MapTask: io.sort.mb = 100
14/09/12 13:25:22 INFO mapred.MapTask: data buffer = 79691776/99614720
14/09/12 13:25:22 INFO mapred.MapTask: record buffer = 262144/327680
14/09/12 13:25:22 INFO mapred.MapTask: Starting flush of map output
14/09/12 13:25:23 INFO mapred.MapTask: Finished spill 0
14/09/12 13:25:23 INFO mapred.TaskRunner: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
14/09/12 13:25:23 INFO mapred.LocalJobRunner:
14/09/12 13:25:23 INFO mapred.TaskRunner: Task 'attempt_local_0001_m_000000_0' done.
14/09/12 13:25:23 INFO mapred.LocalJobRunner:
14/09/12 13:25:23 INFO mapred.Merger: Merging 1 sorted segments
14/09/12 13:25:23 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 39 bytes
14/09/12 13:25:23 INFO mapred.LocalJobRunner:
14/09/12 13:25:23 INFO mapred.TaskRunner: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
14/09/12 13:25:23 INFO mapred.LocalJobRunner:
14/09/12 13:25:23 INFO mapred.TaskRunner: Task attempt_local_0001_r_000000_0 is allowed to commit now
14/09/12 13:25:23 INFO mapred.JobClient: map 100% reduce 0%
14/09/12 13:25:23 INFO output.FileOutputCommitter: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://localhost:9000/user/pc-20130929egdl/administrator/output
14/09/12 13:25:23 INFO mapred.LocalJobRunner: reduce > reduce
14/09/12 13:25:23 INFO mapred.TaskRunner: Task 'attempt_local_0001_r_000000_0' done.
14/09/12 13:25:24 INFO mapred.JobClient: map 100% reduce 100%
14/09/12 13:25:24 INFO mapred.JobClient: Job complete: job_local_0001
14/09/12 13:25:24 INFO mapred.JobClient: Counters: 14
14/09/12 13:25:24 INFO mapred.JobClient: FileSystemCounters
14/09/12 13:25:24 INFO mapred.JobClient: FILE_BYTES_READ=34009
14/09/12 13:25:24 INFO mapred.JobClient: HDFS_BYTES_READ=50
14/09/12 13:25:24 INFO mapred.JobClient: FILE_BYTES_WRITTEN=68754
14/09/12 13:25:24 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=25
14/09/12 13:25:24 INFO mapred.JobClient: Map-Reduce Framework
14/09/12 13:25:24 INFO mapred.JobClient: Reduce input groups=3
14/09/12 13:25:24 INFO mapred.JobClient: Combine output records=3
14/09/12 13:25:24 INFO mapred.JobClient: Map input records=2
14/09/12 13:25:24 INFO mapred.JobClient: Reduce shuffle bytes=0
14/09/12 13:25:24 INFO mapred.JobClient: Reduce output records=3
14/09/12 13:25:24 INFO mapred.JobClient: Spilled Records=6
14/09/12 13:25:24 INFO mapred.JobClient: Map output bytes=41
14/09/12 13:25:24 INFO mapred.JobClient: Combine input records=4
14/09/12 13:25:24 INFO mapred.JobClient: Map output records=4
14/09/12 13:25:24 INFO mapred.JobClient: Reduce input records=3
=========================================================================================
END , 撒花














 3743
3743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









