







劈开迷雾,蘑菇街电商搜索架构及搜索排序实现
前言
蘑菇街的愿景是让一半人类更幸福,而让每位女性用户能便捷的找到心仪的商品则是搜索系统的愿景。作为重要的流量入口,搜索系统一直承担着关键的职责:优化商家流量分配和提升用户体验,让最优质和最符合用户个性化需求的商品排在前面。随着集团品质升级战略的深化,算法排序的不断升级,对搜索系统也提出了更高的要求。
本文会先介绍蘑菇街目前的整体搜索架构,之后以一个在线请求来细化描述搜索排序实现。
现有搜索架构
目前的架构图如下所示:
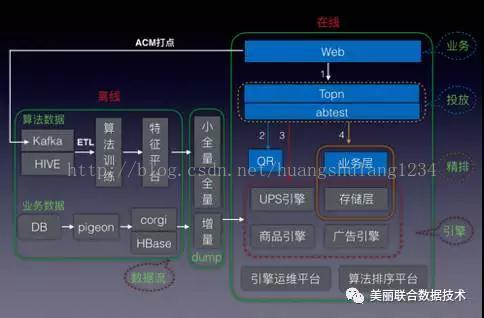
整体架构从大的层面可以分为两部分:在线和离线。在线部分主要是涉及线上请求的系统(运维平台和排序平台是的系统,但主要服务线上系统,所以也划分在在线部分),包括业务层、投放层、精排层、引擎层。离线部分主要是算法训练和数据流相关系统(ACM打点、dump等)。
下面介绍下核心系统的功能。
Topn
topn是搜索系统的统一入口。向上通过统一的接口和检索协议对接不同的搜索业务,业务层只需要关注数据透出结构和来源,不用关注引擎细节和算法逻辑;向下则对接不同的搜索引擎和排序系统,这些系统只需关注自身的搜索及排序逻辑,不需要关心不同的业务接入。同时,topn集成了abtest分流系统及提供算法配置后台,使得多个算法的并行测试和日常上下线非常便捷;另外,通过分组隔离和标准化部署,在可用性和扩展性上提供了最大保障。
Abtest
abtest分流系统实现了uuid/hash/人群标签等多种分流规则,同时也支持自定义分流条件;分层策略能够让多层实验互不干扰。通过统一的实验控制台,结合ACM打点数据,能够实时统计ab数据效果,方便算法同学进行线上评估。统一的SDK使得有ab需求的业务方集成很方便,目前已覆盖集团90%以上的流量入口。
QR
QR系统的主要功能是实现query的改写(Query Rewrite)来扩展query。通常用户输入的搜索词是比较简单的,会根据算法的逻辑进行扩展,然后带到引擎中进行召回和计算。典型的改写功能如切词、同义义词扩展、类目相关性预测、品牌词加权等。QR系统实现上也比较灵活,支持算法的插件化开发,插件之间可以根据业务需求灵活组合。
精排系统
精排系统主要支持算法的个性化排序,以及灵活的算法业务开发。搜索引擎主要负责召回粗排结果,而精排则需要加载更多的特征和更复杂的模型进行排序计算或实时预测。算法排序业务复杂多变,需要较频繁地做ab对比实验,精排通过提供灵活的排序逻辑配置和动态加载机制来支持。实现上精排的底层存储复用了搜索引擎的技术,支持高密度的数据存储和高并发读取。
搜索引擎
基于自研的统一底层框架zindex实现的高性能C++搜索引擎;支持检索、过滤、统计、排序等标准功能;支持海选和多轮排序,提供插件化的排序框架,方便算法同学开发排序算法;支持灵活的索引结构和召回逻辑等。
UPS
User Profile System,用户个性化数据存储系统,包括离线的用户特征数据,以及实时的数据特征(实时点击的商品、实时搜索词、实时加购物车等)。主要服务两大核心业务——搜索和推荐,提供高性能的用户特征数据获取,用于个性化排序和推荐。新版底层基于搜索引擎的统一框架实现,目前线上峰值QPS接近10w,单次请求平均rt在3ms内。
引擎运维平台
提供引擎实例配置、创建、发布部署、索引构建、服务上下线、监控报警等全流程的运维服务。依托docker虚拟化技术和公司的发布系统,支持高效的容器化部署和发布;提供灵活的索引配置和管理;同时提供友好的web控制台进行操作。
算法排序平台
通过统一的可视化后台,为算法同学提供一站式服务,包括快速创建算法场景、模型、排序策略略、脚本,以及上线前的评测等。
为算法同学屏蔽了复杂的线上系统,加快了算法上线的效率和稳定性。平台目前已对接推荐和搜索的多个系统和场景。
dump系统
dump系统的职责是规范和管理搜索数据流,以统一的方式将上游的数据源同步到下游的存储,比如从DB到搜索引擎。从数据特性和系统需求上,提供三种形式:增量、全量、小全量。增量主要解决实时数据的变更和推送;全量主要提供离线高吞吐的数据构建;而小全量主要解决算法数据的更新。另外,在数据的可靠性上也提供了有效的保障。
特征管理平台
特征平台对算法特征进行统一的管理,包括规范特征的定义,算法训练特征生成的统一调度,特征生成后的统一存储,特征的推送上线,特征校验和监控等。算法同学只需专注模型训练和算法调优,特征的上线和复用则交给特征平台。
ACM数据采集系统
ACM采集系统主要解决用户行为数据的埋点、采集、清洗和追踪,为算法的模型训练和实时报表统计提供可靠的数据源。
实现上通过统一的打点日志规范(即自定义的ACM规范),在服务端进行拼装,然后在客户端进行埋点,之后统一收集到数据仓库,通过清洗后提供给算法训练或者做实时统计。
上面主要介绍了搜索系统整体架构和核心系统,看起来可能比较抽象。下面以一个真实的在线请求来详细阐述排序实现。
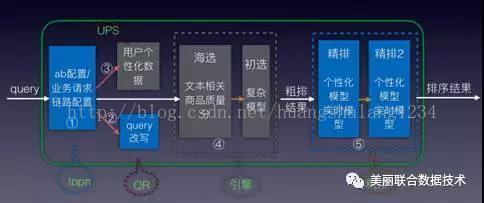
在线搜索流程
在蘑菇街app搜索框上输入 “nike”,搜索请求会经过以下链路(如下图):
1.topn
topn接收到用户query,会根据用户信息和请求来源等进行判断,获取对应的 abtest配置以及后续请求链路的配置,比如该请求是否要请求UPS、请求哪个引擎、是否需要精排等 。
线上topn配置示例如下图所示:

一条典型的配置信息包括以下内容:
-
排序code,用于指定搜索引擎的排序插件;
-
Abtest配置,这里我们用了UUID分流方式,指定某一位对应的值即可;
-
SearchEngine配置,会对应不同的业务实例 (比如商品引擎、店铺引擎);
-
QR配置,是否要请求QR;
-
UPS配置,是否请求UPS以及要获取的字段;
-
ReranConf精排配置,用于指定精排的排序插件和排序模型;
对照上图的配置,可以清楚知道哪些流量走哪个排序,对应请求后端的哪些系统。
2.QR
QR的目的是扩展query以召回更丰富的商品集,不同的query会触发不同的改写插件。可以看下“nike”这个query经过QR做了哪些改写:
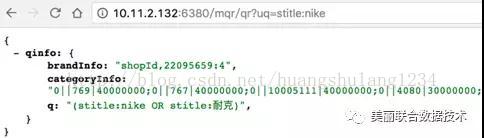
-
nike品牌词触发旗舰店加权(商家扶持)。上图的brankInfo。
-
query类目相关性。上图的categoryInfo,数字表示对应的类目ID和权重。
-
同义词扩展。“nike”有同义词“耐克”。
-
切词这里没有,因为nike本身就是一个完整的词。
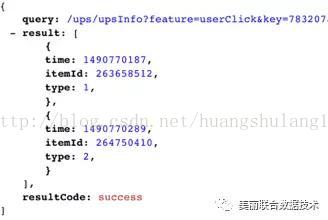
3.UPS
UPS主要存储用户的历史和实时行为,包括收藏、点击、加购、下单等,这些个性化信息提供给精排系统做个性化的排序。比如可以获取用户最近点击的商品列表,精排系统根据这些点击商品进行相似商品加权。接口提供单个UID+行为的获取和批量获取。 比如获取UID=783207的点击数据,大概结构如下:
4.搜索引擎
topn在请求QR获取改写后的query和UPS获取用户个性化信息后,结合自身的排序配置信息,拼成最终的query串传递给搜索引擎,做商品召回和粗排。
搜索引擎的排序是通过排序插件的方式开放给算法同学开发的,支持海选和多轮粗排序。topn配置里的sort=ltr_test_antispam 在引擎中的排序配置如下:
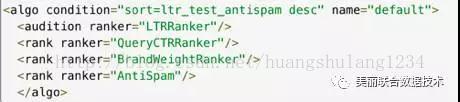
一个算法(algo)排序对应一轮海选(audition)加多轮粗排(rank):
-
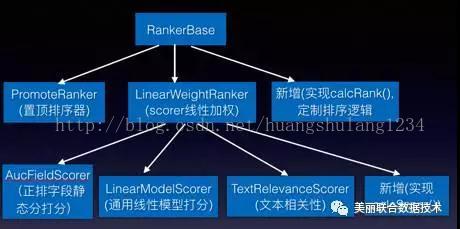
海选配置的是LTRRanker,是我们基于机器学习的线性排序器(ranker)。一个ranker可以包含多个打分器(scorer)。ranker和scorer的关系图如下所示,比如我们的线性ranker包含:商品质量分打分器、通用线性模型打分器、文本相关性打分器。多个打分器通过不同的权重进行线性加权生成最终的排序分数。海选的排序和打分逻辑相对通用和简单,召回性能也高,通常召回的商品数量较大(2w~10w),这些商品再进入到后续的多轮粗排。
-
粗排配置的是三轮排序:QueryCTRRanker、BrandWeightRanker、AntiSpam,分别是基于query点击率预估的排序、品牌加权排序、反作弊过滤。粗排以链式执行,上一轮粗排的结果是下一轮粗排的输入。粗排的计算逻辑要复杂很多,参与排序的商品量也相应少,排序结果透出给精排系统(不需要做个性化重排序的场景下,结果直接返回给前端),粗排召回量通常在千级别(1000~5000)。
5.精排系统
精排系统主要做个性化重排序以及业务重排序,对应的排序模型和算法随业务变化较快,对数据和模型的实时性要求也更高。排序逻辑跟引擎类似,也支持多轮排序,典型的排序如同店打散、类目打散等。
精排系统最终返回topK排序结果给前端,整个在线请求完成。
总结
本文主要介绍了目前蘑菇街搜索系统的整体架构,以及在线请求链路的细化分析。
随着业务的发展,期间经历过很多次的迭代,才慢慢进化成现在的体系,不过可预计的将来现有架构也将进一步演变,我们的最终目标高效支持业务和算法。
本文只是囫囵吐枣,让大家对搜索系统有个整体印象,架构中的每个系统都有很多有价值的细节可挖,期待在后续的文章中跟大伙继续分享。另外,也会讲讲搜索架构是如何一步步演变过来的,敬请期待。
来源:公众号:美丽联合数据技术
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
-END-














 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









