







一直想接触一点深度学习的东西,但是都没有去了解。最近尝试玩一玩Tensorflow,然后试了一下自带的手写数字识别example。
实验平台:Win10 + PyCharm 2016.3.2 + Anaconda 3 + Python 3.5 + CUDA 8.0.44(GTX950) + cudnn5 + Tensorflow 1.0.0
先放代码:
# -*- coding: utf-8 -*-
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
# 尝试下载数据包
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
# y_actual = W * x + b
x = tf.placeholder(tf.float32, [None, 784]) # 占位符
y_actual = tf.placeholder(tf.float32, shape=[None, 10]) # 占位符(实际值)
W = tf.Variable(tf.zeros([784, 10])) # 初始化权值W
b = tf.Variable(tf.zeros([10])) # 初始化偏置b
# 建立抽象模型
y_predict = tf.nn.softmax(tf.matmul(x, W) + b) # 加权变换并进行softmax回归,得到预测值
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_actual * tf.log(y_predict), reduction_indices=1)) # 求交叉熵
train = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) # 用梯度下降法使得残差最小
# 建立测试训练模型
correct_prediction = tf.equal(tf.argmax(y_predict, 1), tf.argmax(y_actual, 1)) # 若预测值与实际值相等则返回boolen值1,不等为0
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float')) # 将返回的beelen数组转换为float类型,并求均值,即得到准确度
# 初始化所有变量
init = tf.initialize_all_variables()
# 在一切操作之后,都用sess来run它们
with tf.Session() as sess:
sess.run(init)
for i in range(1000): # 训练阶段,迭代1000次
batch_xs, batch_ys = mnist.train.next_batch(100) # 按批次训练,每批100行数据
# 执行训练(此处为占位符x, y_actual载入数据,然后使用配置好的train来训练)
sess.run(train, feed_dict={x: batch_xs, y_actual: batch_ys})
if i % 100 == 0: # 每训练100次,测试一次
print("accuracy:", sess.run(accuracy, feed_dict={x: mnist.test.images, y_actual: mnist.test.labels}))
代码mnist = input_data.read_data_sets('MNIST_data/', one_hot=True),该函数中会获取以下几个数据包:
TRAIN_IMAGES = 'train-images-idx3-ubyte.gz'
TRAIN_LABELS = 'train-labels-idx1-ubyte.gz'
TEST_IMAGES = 't10k-images-idx3-ubyte.gz'
TEST_LABELS = 't10k-labels-idx1-ubyte.gz'上述images和labels数据包是按照一定格式存储的文件,可以用WinHex来查看。我自己转换了图片或文本格式的方便观察(如下所示),点击此处。
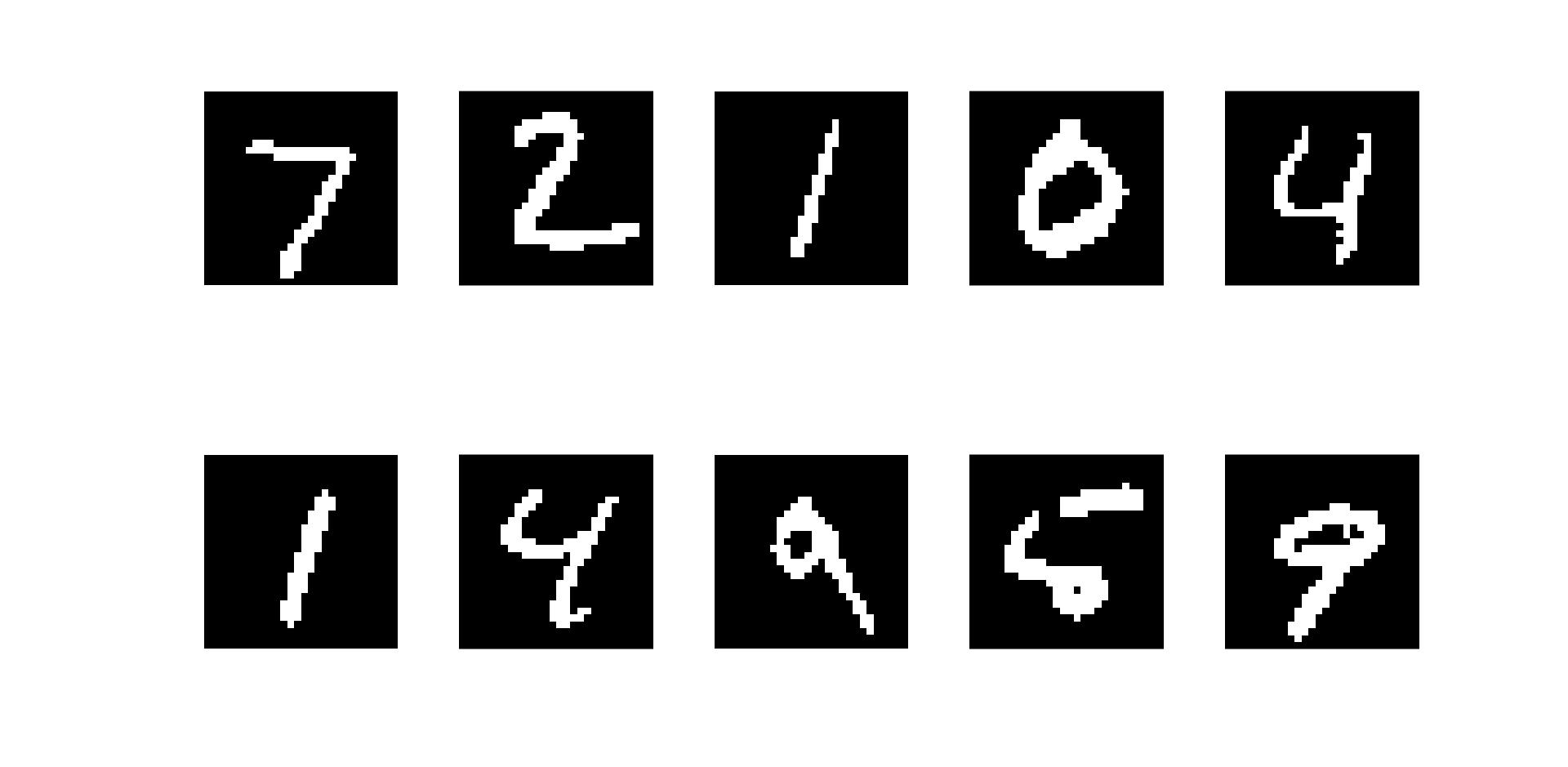














 1972
1972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









