







总说
简单来说,这个其实类似 Deep photo吧,都是加了分割mask的。和Deep Photo的区别就是,那么仍旧采用Gram-matrix-matching的方式进行style loss的计算。这个采用的是CNNMRF的style loss。
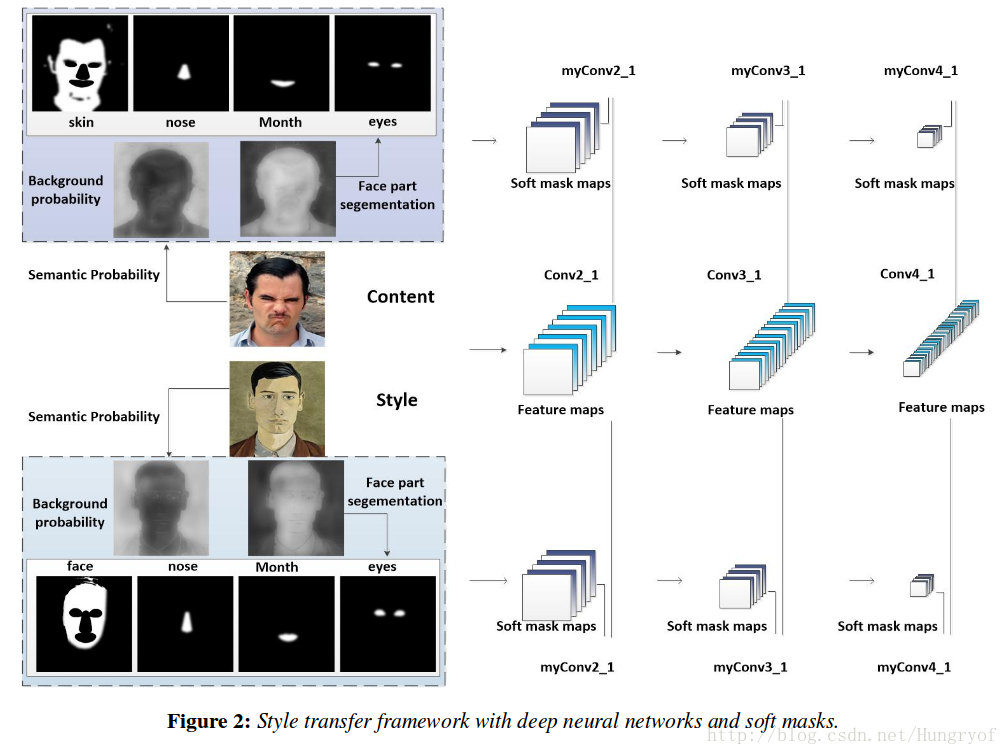
框架也是一样,采用一个能提取特征的model,一般就选VGG19了。然后在隐藏层上进行一些loss的计算。主要是content loss和style loss,都是这些东西。这文章和CNNMRF的区别就是,加入了soft masks,否则还真的完全没区别啊。不过加入semantic mask的话,也是借鉴了 Deep photo吧。。简单来说就是用了CNNMRF的style loss加上Deep photo的semantic mask也加入进style loss的计算。 结合起来就完事。速度也慢,和deep photo的一样,迭代的方法能快? 也没和Deep photo比效果,和CNNMRF比算啥啊。唉唉。不过另外说一点,就是这个不是用hard mask,而是用soft mask来弄,算是和他们不太一样的地方吧。
简述方法
简单来说就是他们先将content 图 xc 以及style 图 xs 放进CRF-RNN(用于分割的网络),得到最后一层前面的activations,然后rescale到0-1之间,这就是probability map。得到 mc 和 ms ,分别对应这
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









