









logistic回归分析,主要在流行病学中应用较多,比较常用的情形是探索某疾病的危险因素,根据危险因素预测某疾病发生的概率。
例如,想探讨胃癌发生的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群肯定有不同的体征和生活方式等。
这里的因变量就是是否胃癌,即“是”或“否”,为两分类变量,自变量就可以包括很多了,例如年龄、性别、饮食习惯、幽门螺杆菌感染等。
自变量既可以是连续的,也可以是分类的。
通过logistic回归分析,就可以大致了解到底哪些因素是胃癌的危险因素。机器学习实战中研究就是关于马患胃癌的分析。
理论知识部分:
Logistic Regression 的hypotheses函数
在Linear Regression中,如果我们假设待预测的变量y是离散的一些值,那么这就是分类问题。如果y只能取0或1,这就是binary classification的问题。我们仍然可考虑用Regression的方法来解决binary classification的问题。但是此时,由于我们已经知道y \in {0,1},而不是整个实数域R,我们就应该修改hypotheses函数h_\theta(x)的形式,可以使用Logistic Function将任意实数映射到[0,1]的区间内。即
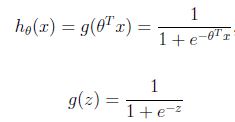
其中我们对所有feature先进行线性组合,即\theta' * x = \theta_0 * x_0 + \theta_1 * x_1 +\theta_2 * x_2 ..., 然后把线性组合后的值代入Logistic Function(又叫sigmoid function)映射成[0,1]内的某个值。Logistic Function的图像如下
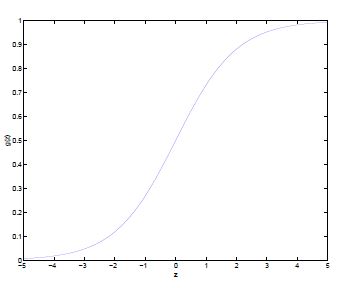
当z->正无穷大时,函数值->1;当z->负无穷大时,函数值->0.因此新的hypotheses函数h_\theta(x)总是在[0,1]这个区间内。我们同样增加一个feature x_0 = 1以方便向量表示。Logistic Function的导数可以用原函数来表示,即
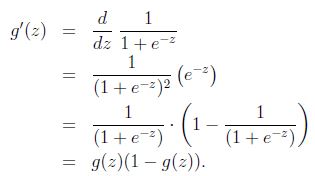
这个结论在后面学习参数\theta的时候还会使用到。
2 用最大似然估计和梯度上升法学习Logistic Regression的模型参数\theta
给定新的hypotheses函数h_\theta(x),我们如何根据训练样本来学习参数\theta呢?我们可以考虑从概率假设的角度使用最大似然估计MLE来fit data(MLE等价于LMS算法中的最小化cost function)。我们假设:
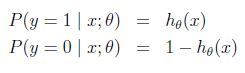
即用hypotheses函数h_\theta(x)来表示y=1的概率; 1-h_\theta(x)来表示y=0的概率.这个概率假设可以写成如下更紧凑的形式
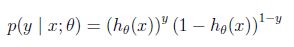
假设我们观察到了m个训练样本,它们的生成过程独立同分布,那么我们可以写出似然函数
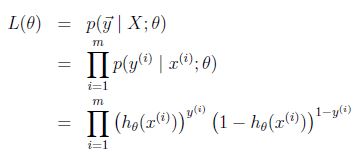
取对数后变成log-likelihood

我们现在要最大化log-likelihood求参数\theta. 换一种角度理解,就是此时cost function J = - l(\theta),我们需要最小化cost function 即- l(\theta)。
类似于我们在学习Linear Regression参数时用梯度下降法,这里我们可以采用梯度上升法最大化log-likelihood,假设我们只有一个训练样本(x,y),那么可以得到SGA(增量梯度上升)的update rule
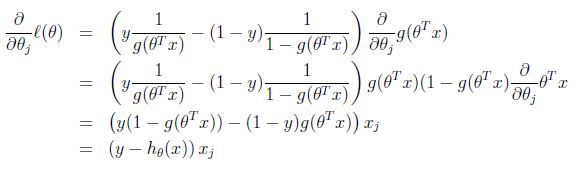
里面用到了logistic function的导数的性质 即 g' = g(1-g).于是我们可以得到参数更新rule
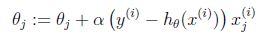
这里是不断的加上一个量,因为是梯度上升。\alpha是learning rate. 从形式上看和Linear Regression的参数 LMS update rule是一样的,但是实质是不同的,因此假设的模型函数h_\theta(x)不同。在Linear Regression中只是所有feature的线性组合;在Logistic Regression中是先把所有feature线性组合,然后在带入Logistic Function映射到区间[0,1]内,即此时h_\theta(x)就不再是一个线性函数。其实这两种算法都是Generalized Linear Models的特例。
python 实现部分(来自机器学习实战第五章):
from numpy import *
def loadDataSet():
dataMat=[]; labelMat=[]
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def gradAscent(dataMatIn,classLabels):
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
m,n = shape(dataMatrix)
alpha = 0.001
maxIteration = 500
weights = ones((n,1))
for k in range(maxIteration):
h = sigmoid(dataMatrix * weights)
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose() * error
return weights
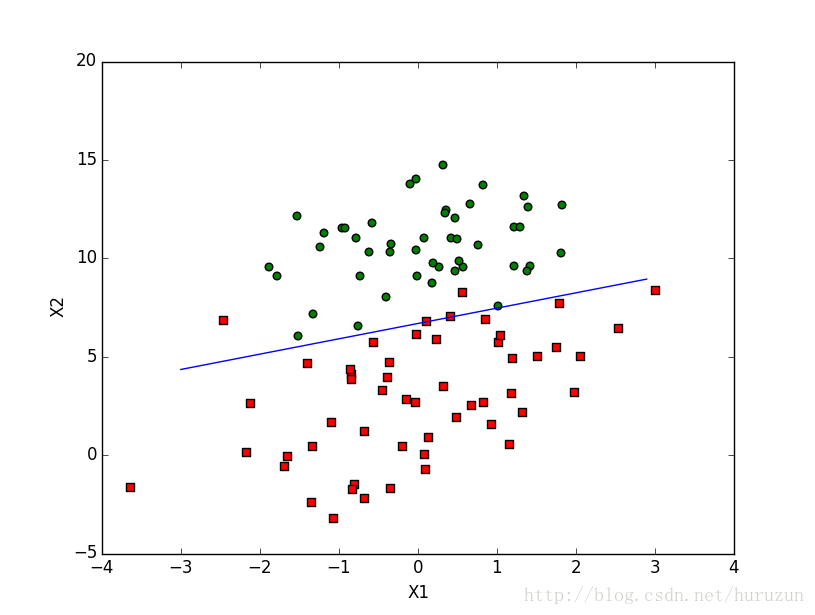
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):# get x,y locate at xcord ycord
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
if __name__ == "__main__":
dataArr,labelMat = loadDataSet()
print(dataArr)
print(labelMat)
weights = gradAscent(dataArr, labelMat)
print(weights)
plotBestFit(weights.getA())
gradAscent 函数中最重要的一步对theta迭代,前面公式进行了推导。plotBestFit 画出决策边界。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









