







一、对朴素简单直接方法
把m*n 和n*l的矩阵A和B相乘,这估计是最容易想到的方法了:
把A(m*n)的元素,每个发送l次,把B(n*l)的元素每个发送m次。将发送到一起的数据相乘求和,得到最后的结果。
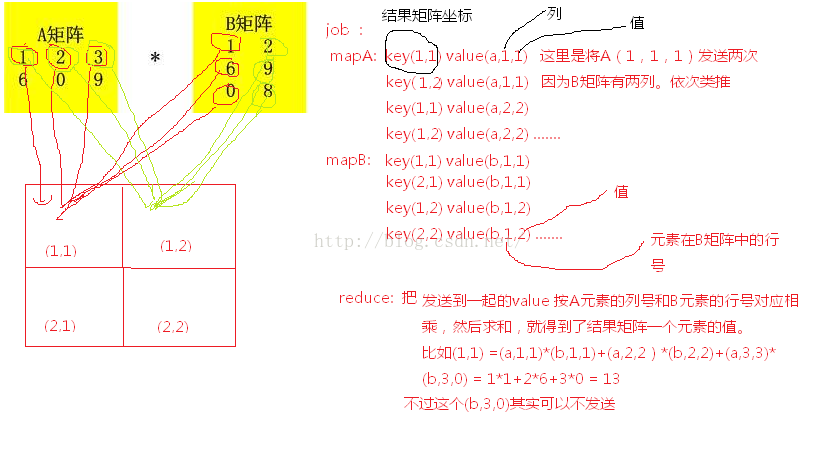
缺点:每个值要被发送多次。m*n 和n*l的矩阵,发送的元素有m*l*2次,比如100万的方正相乘,那么中间文件有100*100百万*百万的记录,这么多元素在网络上传输,结果你懂的。另外,这个并没有有效的避开0元素,也就是说对稀疏矩阵来说很浪费。而且必须要知道矩阵的下标和行列数。因为在map里需要用到。实际情况是,现实中的矩阵,并不一定都是用递增的整数来表示下标的。有可能是人名,帐号等。
上面的方法乍一看还ok,用小数据测试一下也是正确的,不过这个方法问题在于,reduce里收到的数据也许非常非常多,多到内存放不下。然后节点就heapSpace overFlow了。话说回来如果一定要在这个方法上改进,可以把map reduce分成两步。第一步还是和上面一样,但是key中再加一个字段k,表示,这是结果矩阵中坐标为(i,j)的元素的第k个用来求和的元素。k其实是A的列号和B的行号。这样上面的过程就变成
A: key(1,1,1) value(a,1) key(1,1,2) value(a,2) key(1,1,3) value(a,3)
key(1,2,1) value(a,1) key(1,2,2) value(a,2) ..........
B: key(1,1,1) value(b,1) key(1,1,2) value(b,6) key(1,1,3) value(b,0)
key(2,1,1) value(b,1) key(2,1,2) value(b,6) ...........
然后在reduce中对元素求乘积 生成:
key(1,1) value= (a,1)*(b,1) key(1,1) value= (a,2)*(b,6) key(1,1) value= (a,3)*(b,0). 其实连元素来自A还是B都可以省了。
再来第二轮mapreduce,对上一步mapreduce的结果再group by,求和。这样改进之后,没有reduce内存溢出的问题。看起来像是多大的矩阵都可以计算,其实由于没能解决一个A或B的元素要发送很多次的问题,在计算超级大的矩阵的时候,这个方法还是完全不能用。
二、 分解成行和列来控制
观察上面的最细的矩阵乘法,如果矩阵是比较稀疏的,其实有很多东西就白白发送了,发出去在reduce里其实没有用到。也是这个原因导致中间文件急剧膨胀,如果矩阵超级大,即使在mapreduce里,也要跑相当长时间。再来回忆一下矩阵乘法,能发现一些规律。
假设现在有两个矩阵,分别是同现矩阵和用户评分矩阵,现在要把两个矩阵相乘来获得推荐分数。
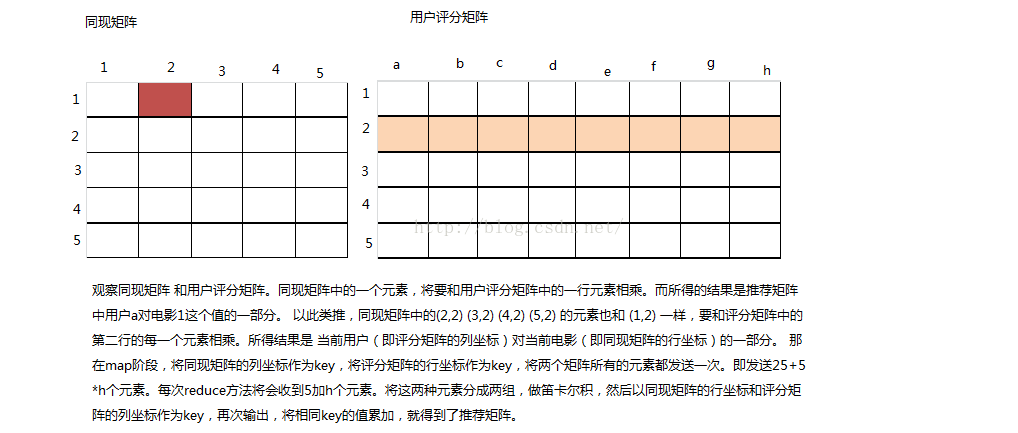
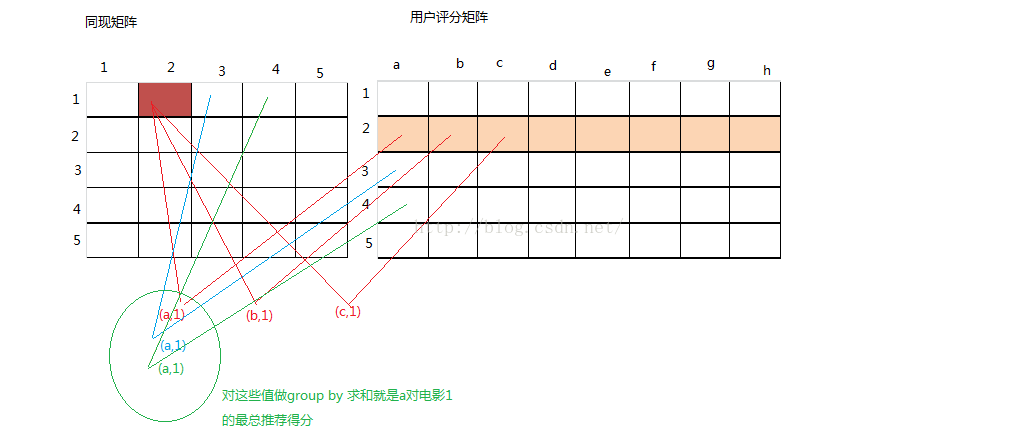
通过观察,把A矩阵的一列和B矩阵的一行发送到同一个reduce中,然后在reduce中,对来自A的元算和来自B的元素做笛卡尔乘积,对笛卡尔乘积的结果再做一次mapReduce,对相应的坐标求和就可以得到结果矩阵的一个个元素了。
优点:相对与最细的矩阵乘法而言,大大压缩了中间文件的大小,对稀疏矩阵而言,避免了找不到对应元素而造成的浪费。在这个方法里,为0的元素不发送就行了。另外一个明显的优点就是,我用不着一定用数字来表示矩阵的坐标,是字符串也行。只要A矩阵的列坐标和B矩阵的行坐标对的上就行。
缺点:变成了两轮mapreduce才搞得定。另一个明显缺点是,在一个reduce的节点内存里面,未必放的下A的一行+B的一列。因为仅凭key不能区分数据是来自A矩阵还是B矩阵,最起码要往内存里读一次才知道怎么做笛卡尔乘积。当然写成一个文件放到reduce本地,然后再来算也行,不过这样有点低效了,不如直接在内存里来的快。这样其实还是限制了这个方法的范围,我觉得1百万乘以1百万的稀疏矩阵用这个方法来做还是撑的住的,当然得看矩阵稀疏程度。














 8420
8420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









