






- 前言
我的第一部手机是12年买的oppo,使用过的朋友应该知道,这个手机自带一款软件,名为:‘nearme,oppo笔记云’。现在也有许多同类软件:有道云笔记,印象笔记等等,都是记录一些笔记和图片之类的。后来换了手机,但是因为用惯了这个软件,就没有换用别的软件。但是问题来了,日积月累,手机里面存了几千条笔记,手机APP和网页同步网站都不支持整体导出功能,只能一条条导出,或者复制到word中,这样做实在繁琐,但是又没有办法,因为没有这样的工具可以导出笔记。后来学了点python的知识,想用python爬取我想要的东西,无奈当时学的太浅,两座大山翻越不过(即:模拟登录和js动态网页分析),此想法便搁浅了许久。直到今天,借着兴致,用了近大半天的时间,终于完成了该代码,初步达到预想的结果。
现将代码及思路分享出来,也希望有更好的想法的小伙伴,不吝赐教。
- 模拟登录,打开大门
想要看qq空间的说说,首先要登录进去,想要看邮箱里的邮件,也需要输入邮箱密码。python想要爬取这些网站的内容,首先要登录进去。当然这里的登录当然不是我们熟悉的那样在登录页面相应的输入框中输入,用户名和密码。python需要模拟登录。
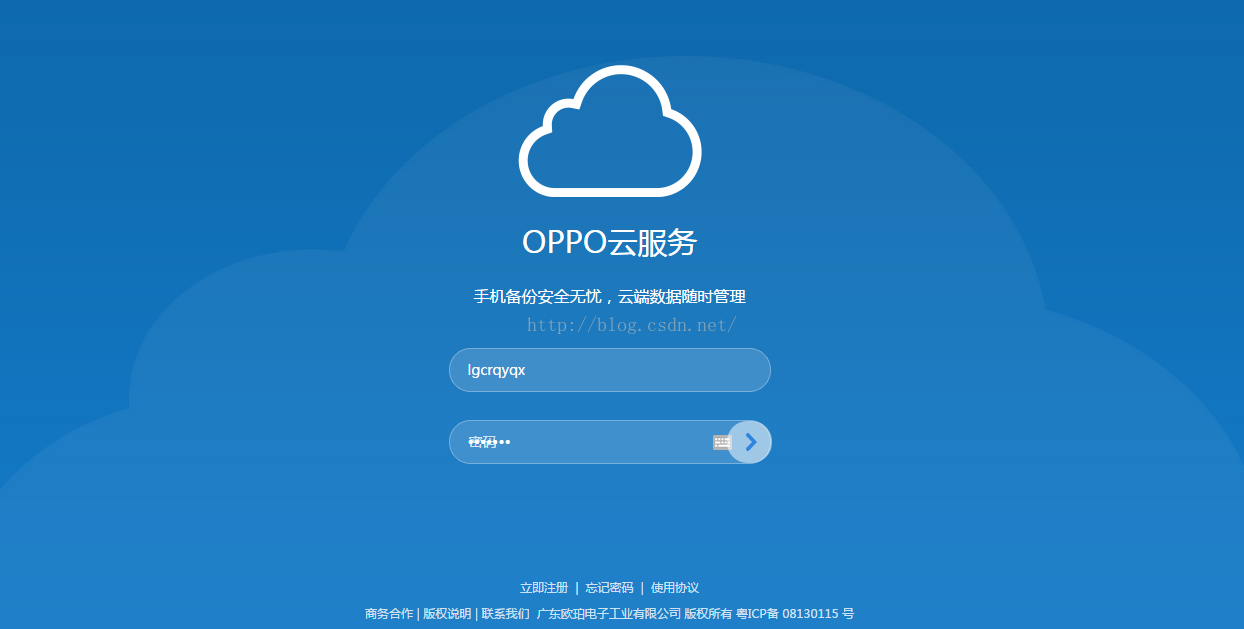
我们提供network分析一下登录的代码:
通过点击登录时而生存了login代码,可以打开看一下:
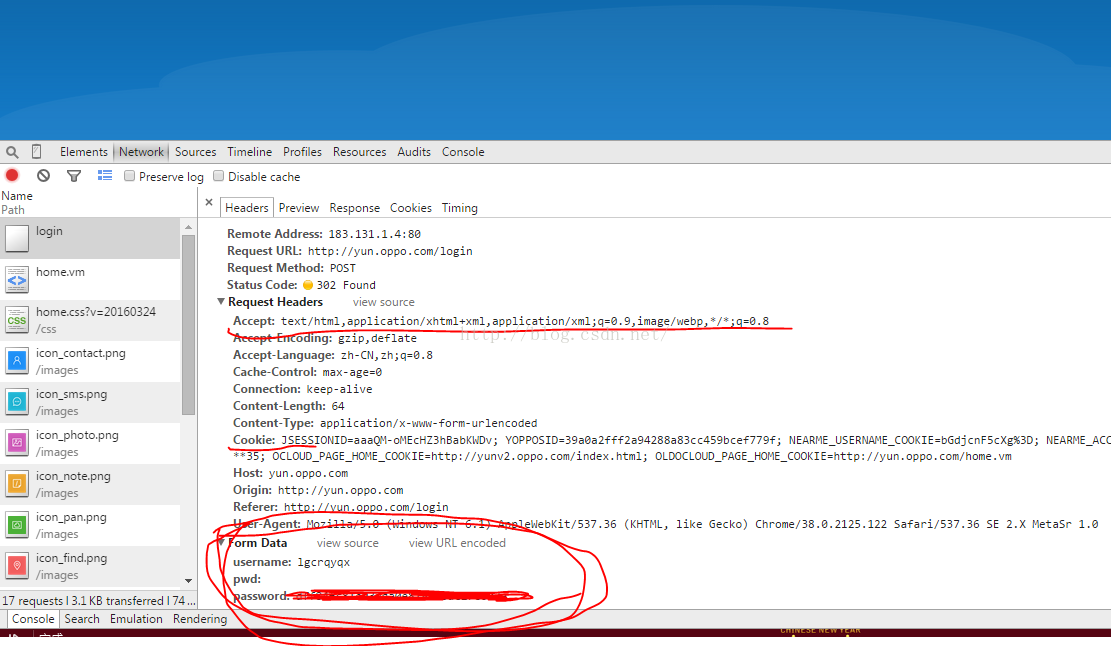
重点看一下我画红线的部分,这些信息在构建模拟登录时都要用到。
接下来,边看代码边分析:
<span style="font-size:24px;">import urllib
from urllib import request
import requests
from bs4 import BeautifulSoup
import json
#模拟登录
login="http://yun.oppo.com/login" #登录网址
UA = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0" #上图中Accept内容
header = { "User-Agent" : UA,
"Referer": "http://yun.oppo.com/login"
} #构建header
note_session = requests.Session()
f = note_session.get(login,headers=header)
soup = BeautifulSoup(f.content,"html.parser")
postData = { 'username': 'lgcrqyqx',
'pwd': '',
'password': '**************', #这些内容可以直接参考上图中圈圈部分,不同网站,会有所不同
}
note_session.post(login,
data = postData,
headers = header)</span>特此说明一下代码中的session():
以下内容摘自:http://www.cnblogs.com/whatbeg/p/5320666.html
会话对象requests.Session能够跨请求地保持某些参数,比如cookies,即在同一个Session实例发出的所有请求都保持同一个cookies,而requests模块每次会自动处理cookies,这样就很方便地处理登录时的cookies问题。在cookies的处理上会话对象一句话可以顶过好几句urllib模块下的操作。即相当于urllib中的:
|
1
2
3
4
|
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
urllib.request.install_opener(opener)
|
这样模拟登录就建好了,我们可以在此基础上登录里面的子页面。
- 匹配笔记网址,几番周折

| <li class="home"><ahref="http://yun.oppo.com/home.vm"><imgsrc="images/icon_home.png" /><p>首页</p></a></li> | |
| <li><ahref="http://sync.yun.oppo.com"><imgsrc="images/icon_contact1.png"/><p>联系人</p></a></li> | |
| <li><ahref="http://sync.yun.oppo.com/shortMessage"><imgsrc="images/icon_sms1.png" /><p>短信</p></a></li> | |
| <li><ahref="http://pan.yun.oppo.com/index.php?album"><imgsrc="images/icon_photo1.png"/><p>云相册</p></a></li> | |
| <li class="active"><ahref="#"><imgsrc="images/icon_note1.png" /><p>云笔记</p></a></li> | |
- 压死骆驼的最后一根稻草
year=input('请输入要导出笔记的年份: \n')
mon =1
for mon in range(1,13,1):
month = "%02d" % mon
f = note_session.get('http://note.yun.oppo.com/note?operation=1¬e_month='+year+'-'+month+'&search_word=',headers=header)
note=f.content.decode()
note=note.replace('{','')
note=note.replace('},','*1')#用一个不常用的字符‘*1’作为下面的将一条条信息隔开的标识
note=note.replace('[','')
note=note.replace(']','')
note=note.split('*1')
n=len(note)
i=0
#以{}为分隔符,将每个月的note分割为每天的note
for i in range(0,n):
note[i]=note[i].replace('}','')
note[i]=str('{'+note[i]+'}')
note[i]=json.loads(note[i])
note[i]=dict(note[i])
try:
date = ('show_note_updated' in note[i].keys())
if date == False :
date =''
else:
date =note[i]['show_note_updated'] #匹配笔记时间
date1 = ('str_content' in note[i].keys())
if date1 == False :
date1 =''
else:
date1 =note[i]['str_content'] #匹配笔记内容
except(TypeError, IndexError):
pass
s=date+':'+date1
ftp = open(year+'.txt','a',encoding='utf-8')
ftp.write(s+'\n\n') #写入txt
ftp.close()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









