







机器学习总结之逻辑回归Logistic Regression
逻辑回归logistic regression,虽然名字是回归,但是实际上它是处理分类问题的算法。简单的说回归问题和分类问题如下:
回归问题:预测一个连续的输出。
分类问题:离散输出,比如二分类问题输出0或1.
逻辑回归常用于垃圾邮件分类,天气预测、疾病判断和广告投放。
一、假设函数
因为是一个分类问题,所以我们希望有一个假设函数![]() ,使得:
,使得:
![clip_image004[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165652645-115514229.jpg "clip_image004[4]")
而sigmoid 函数可以很好的满足这个性质:
![clip_image006[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165950160-681212549.jpg "clip_image006[4]")
故假设函数:
![clip_image007[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165654707-1288651496.png "clip_image007[4]")
其实逻辑回归为什么要用sigmoid函数而不用其他是因为逻辑回归是采用的伯努利分布,伯努利分布的概率可以表示成
![clip_image008[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165655566-2059956804.png "clip_image008[4]")
其中
![]()
得到
![]()
这就解释了logistic回归时为了要用这个函数。
二、代价函数
好了,现在我们确定了假设函数,输入![]() ,如果我们依旧用线性回归的代价函数:
,如果我们依旧用线性回归的代价函数:
![clip_image014[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165659910-490128094.jpg "clip_image014[4]")
其中:
![clip_image016[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165701082-443274991.jpg "clip_image016[4]")
这样的话代价函数![]() 将会非常复杂,有多个局部最小值,也就是非凸的,如下所示:
将会非常复杂,有多个局部最小值,也就是非凸的,如下所示:
![clip_image020[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165951457-394293420.jpg "clip_image020[4]")
然而这并不是我们想要的,我们想要代价函数是凸函数如下:这样我们就可以很容易的找出全局最优解。
![clip_image022[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165952488-2066511924.jpg "clip_image022[4]")
我们回过头来看![]() :
:
![clip_image024[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165705691-95117424.jpg "clip_image024[4]")
由上式我们可得:
![]()
如果我们将![]() 视为样本
视为样本![]() 作为正例的可能性,
作为正例的可能性,![]() 则为反例的可能性,
则为反例的可能性,
两者的比值对数称为对数几率:
![]()
这也就是逻辑回归为什么也称作对数几率回归的原因,我们可以将![]() 视为类后验概率:
视为类后验概率:![]() ,则由:
,则由:
![]()
可得:
![clip_image038[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165713488-311046395.png "clip_image038[4]")
我们用“最大似然估计”来估计![]() ,逻辑回归模型的似然函数如下:
,逻辑回归模型的似然函数如下:
![]()
对数似然函数如下:
![]()
![]()
即令每个样本属于其真实标记的概率越大越好,![]() 是高阶连续可导的凸函数,由凸优化理论可以根据梯度下降法、牛顿法等求最优解
是高阶连续可导的凸函数,由凸优化理论可以根据梯度下降法、牛顿法等求最优解![]() 。
。
实际上,上式即为逻辑回归的代价函数:
![]()
它是由极大似然得来的。
由梯度下降得:
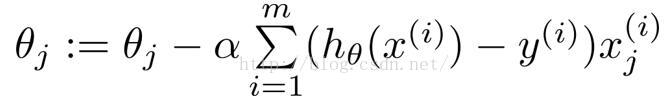
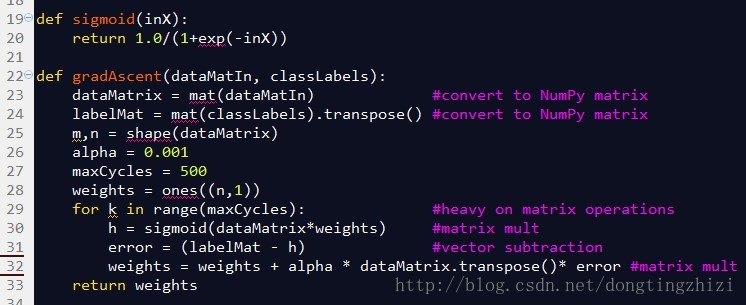
下图是《机器学习实战》中给出的部分实现代码。
三、过拟合问题
对于线性回归或逻辑回归的损失函数构成的模型,可能会有些权重很大,有些权重很小,导致过拟合(就是过分拟合了训练数据),使得模型的复杂度提高,泛化能力较差(对未知数据的预测能力)。
下面左图即为欠拟合,中图为合适的拟合,右图为过拟合。

问题的主因
过拟合问题往往源自过多的特征。
解决方法
1)减少特征数量(减少特征会失去一些信息,即使特征选的很好)
- 可用人工选择要保留的特征;
- 模型选择算法;
2)正则化(特征较多时比较有效)
- 保留所有特征,但减少θ的大小
正则化方法
正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或惩罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化项就越大。
从房价预测问题开始,这次采用的是多项式回归。左图是适当拟合,右图是过拟合。

直观来看,如果我们想解决这个例子中的过拟合问题,最好能将 的影响消除,也就是让
的影响消除,也就是让 。假设我们对
。假设我们对 进行惩罚,并且令其很小,一个简单的办法就是给原有的Cost函数加上两个略大惩罚项,例如:
进行惩罚,并且令其很小,一个简单的办法就是给原有的Cost函数加上两个略大惩罚项,例如:

这样在最小化Cost函数的时候,。
正则项可以取不同的形式,在回归问题中取平方损失,就是参数的L2范数,也可以取L1范数。取平方损失时,模型的损失函数变为:

lambda是正则项系数:
- 如果它的值很大,说明对模型的复杂度惩罚大,对拟合数据的损失惩罚小,这样它就不会过分拟合数据,在训练数据上的偏差较大,在未知数据上的方差较小,但是可能出现欠拟合的现象;
- 如果它的值很小,说明比较注重对训练数据的拟合,在训练数据上的偏差会小,但是可能会导致过拟合。
正则化后的梯度下降算法θ的更新变为:

正则化后的线性回归的Normal Equation的公式为:

其他优化算法
- Conjugate gradient method(共轭梯度法)
- Quasi-Newton method(拟牛顿法)
- BFGS method
- L-BFGS(Limited-memory BFGS)
后二者由拟牛顿法引申出来,与梯度下降算法相比,这些算法的优点是:
- 第一,不需要手动的选择步长;
- 第二,通常比梯度下降算法快;
但是缺点是更复杂。
四、逻辑回归的优点
1、它是直接对分类可能性建模,无需事先假设数据分布,这样就避免了假设分布不准确问题。
2、它不仅预测类别,而且可以得到近似概率预测,这对许多概率辅助决策的任务很有用。
3、对率函数是任意阶可导凸函数,有很好的数学性质,现有许多的数值优化算法都可以直接用于求解。
五、多分类问题
对于多分类问题常用的做法是分解为多个二分类问题,例如:
![clip_image054[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165722879-584067436.jpg "clip_image054[4]")
分解为下面三个二分类逻辑回归问题:
![clip_image056[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165723785-286043417.jpg "clip_image056[4]")
![clip_image058[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165725020-813313349.jpg "clip_image058[4]")
![clip_image060[4]](http://images2015.cnblogs.com/blog/904258/201604/904258-20160414165726223-1073342667.jpg "clip_image060[4]")
对于一个新的样本![]() ,如果第i类使得
,如果第i类使得![]() 最大,我们认为
最大,我们认为![]() 属于i类。
属于i类。
参考文献:
周志华《机器学习》
Andrew NG 机器学习公开课














 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









