







网络管理,由于分布式集群,那么无论master还是worker都离不开网络通讯。Network包位于核心源码org.apache.spark.network中。
Connection
Connection是一个抽象,它有两个子类ReceivingConnection、SendingConnection。接收连接和发送连接。
ReceivingConnection
接收连接。这里面有几个比较中要的方法:getRemoteConnectionManagerId()、processConnectionManagerId(header: MessageChunkHeader)、read()
getRemoteConnectionManagerId():获取远程连接的消息Id,这个方法调用了父类的实现。
processConnectionManagerId源码如下:
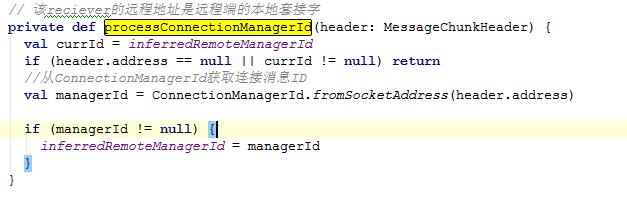
这里面有个内部类Inbox,它是一个消息存储集合。里面有个属性
val messages = new HashMap[Int,BufferMessage]()
所有连接到该节点的机器都会被记录到这个messages集合中。
SendingConnection
发送连接。它和ReceivingConnection恰恰相反。
ConnectionId
生成连接的ID对象。生成的原则包括:
override def toString =connectionManagerId.host + "_" + connectionManagerId.port +"_" + uniqId
ConnectionManager
ConnectionManager,顾名思义管理connection。里面定义定了内部类MessageStatus、配置参数还有一系列的线程池等等。
MessageStatus:消息状态,用于跟踪连接消息状态。
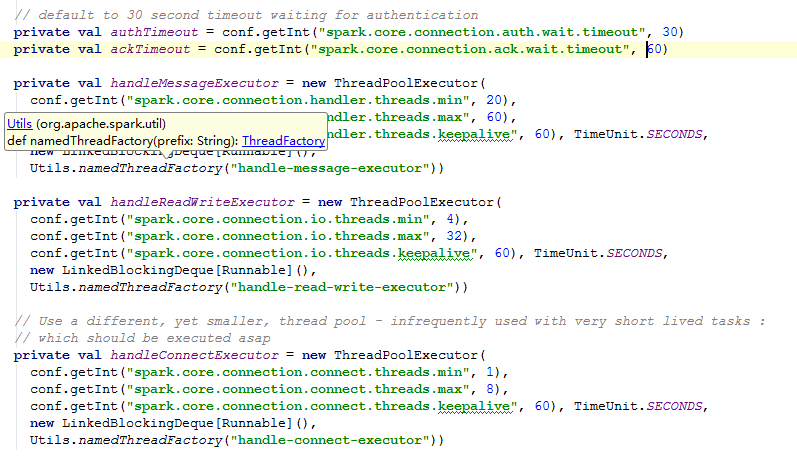
配置参数:
Netty
Server
BlockServer
BlockServer服务器提供的Spark数据块。它有两层协议:
l C2S:用于请求blocks协议(客户端到服务器):按照目录结构
l S2C:用于请blocks协议(服务器到客户端)
frame-length (4bytes), block-id-length (4 bytes), block-id, block-data.
frame-length不包括自身长度。如果block-id-length长度为负,那么这是一个错误消息, 而不是块的数据。真正的长度是frame-length的绝对值。
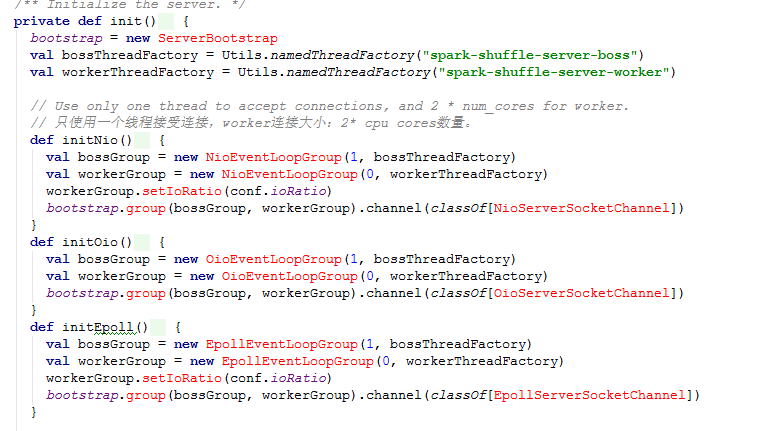
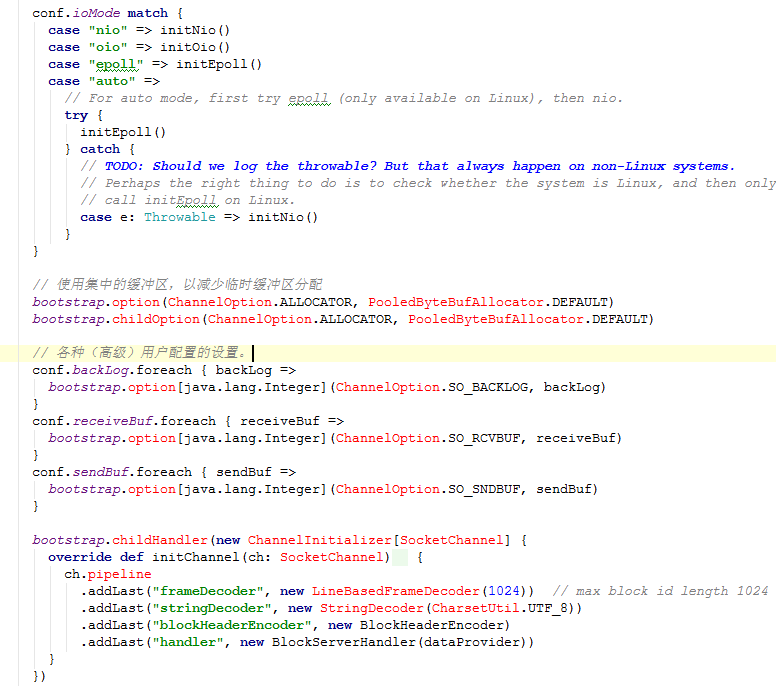
下面是初始化init源码:
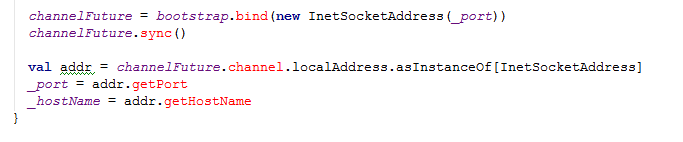
BlockServerHandler
BlockServerHandler请求从客户端和写数据块block回来的处理程序。消息应已被LineBasedFrameDecoder处理和StringDecoder首次如此channelRead0被调用一次每行(即block ID)。
Client
BlockFetchingClient
BlockFetchingClient从org.apache.spark.network.netty.server.BlockServer抓取数据。
查看里面一个比较中要的方法:fetchBlocks。该方法向远程服务器的序列划block,并执行回调。它是异步的,并立即返回。
源码如下:
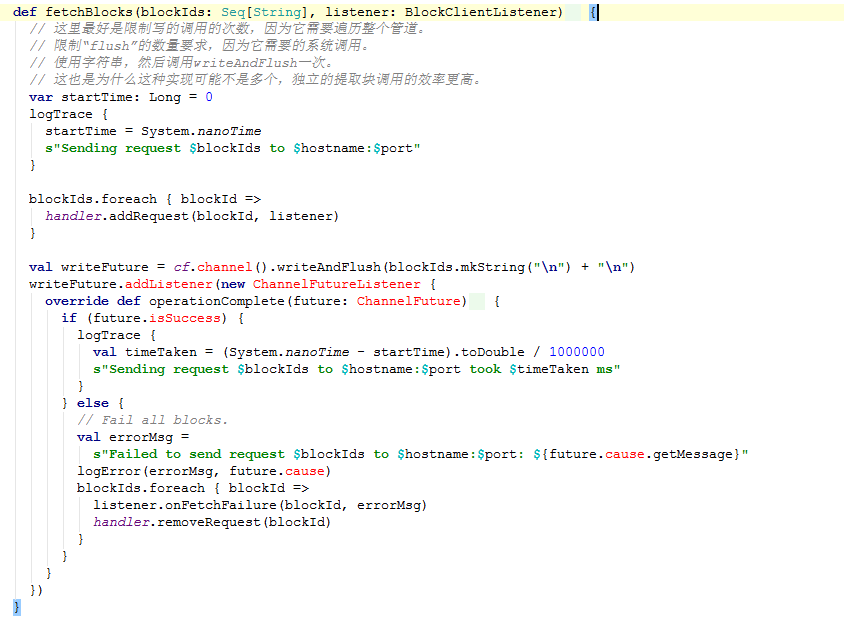
Conf
| Property Name | Default | Meaning |
| spark.driver.host | (local hostname) | Hostname or IP address for the driver to listen on. This is used for communicating with the executors and the standalone Master. |
| spark.driver.port | (random) | Port for the driver to listen on. This is used for communicating with the executors and the standalone Master. |
| spark.fileserver.port | (random) | Port for the driver's HTTP file server to listen on. |
| spark.broadcast.port | (random) | Port for the driver's HTTP broadcast server to listen on. This is not relevant for torrent broadcast. |
| spark.replClassServer.port | (random) | Port for the driver's HTTP class server to listen on. This is only relevant for the Spark shell. |
| spark.blockManager.port | (random) | Port for all block managers to listen on. These exist on both the driver and the executors. |
| spark.executor.port | (random) | Port for the executor to listen on. This is used for communicating with the driver. |
| spark.port.maxRetries | 16 | Default maximum number of retries when binding to a port before giving up. |
| spark.akka.frameSize | 10 | Maximum message size to allow in "control plane" communication (for serialized tasks and task results), in MB. Increase this if your tasks need to send back large results to the driver (e.g. using collect() on a large dataset). |
| spark.akka.threads | 4 | Number of actor threads to use for communication. Can be useful to increase on large clusters when the driver has a lot of CPU cores. |
| spark.akka.timeout | 100 | Communication timeout between Spark nodes, in seconds. |
| spark.akka.heartbeat.pauses | 6000 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). Acceptable heart beat pause in seconds for akka. This can be used to control sensitivity to gc pauses. Tune this in combination of `spark.akka.heartbeat.interval` and `spark.akka.failure-detector.threshold` if you need to. |
| spark.akka.failure-detector.threshold | 300.0 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). This maps to akka's `akka.remote.transport-failure-detector.threshold`. Tune this in combination of `spark.akka.heartbeat.pauses` and `spark.akka.heartbeat.interval` if you need to. |
| spark.akka.heartbeat.interval | 1000 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). A larger interval value in seconds reduces network overhead and a smaller value ( ~ 1 s) might be more informative for akka's failure detector. Tune this in combination of `spark.akka.heartbeat.pauses` and `spark.akka.failure-detector.threshold` if you need to. Only positive use case for using failure detector can be, a sensistive failure detector can help evict rogue executors really quick. However this is usually not the case as gc pauses and network lags are expected in a real Spark cluster. Apart from that enabling this leads to a lot of exchanges of heart beats between nodes leading to flooding the network with those. |














 2947
2947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









