








本文个人博客地址:http://www.huweihuang.com/article/kubernetes/core-principle/kubernetes-core-principle-scheduler/
1. 1. Scheduler简介
Scheduler负责Pod调度。在整个系统中起"承上启下"作用。
承上:负责接收Controller Manager创建的新的Pod,为其选择一个合适的Node。
启下:Node上的kubelet接管Pod的生命周期。
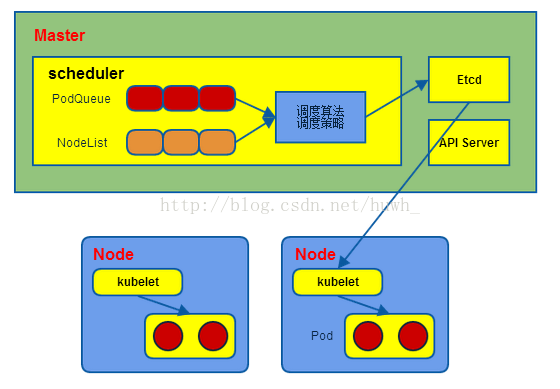
Scheduler:
1)通过调度算法为待调度Pod列表的每个Pod从Node列表中选择一个最适合的Node,并将信息写入etcd中
2)kubelet通过API Server监听到kubernetes Scheduler产生的Pod绑定信息,然后获取对应的Pod清单,下载Image,并启动容器。
2. 2. 调度流程
1、预选调度过程,即遍历所有目标Node,筛选出符合要求的候选节点,kubernetes内置了多种预选策略(xxx Predicates)供用户选择
2、确定最优节点,在第一步的基础上采用优选策略(xxx Priority)计算出每个候选节点的积分,取最高积分。
调度流程通过插件式加载的“调度算法提供者”(AlgorithmProvider)具体实现,一个调度算法提供者就是包括一组预选策略与一组优选策略的结构体。
3. 3. 预选策略
说明:返回true表示该节点满足该Pod的调度条件;返回false表示该节点不满足该Pod的调度条件。
3.1. 3.1. NoDiskConflict
判断备选Pod的数据卷是否与该Node上已存在Pod挂载的数据卷冲突,如果是则返回false,否则返回true。
3.2. 3.2. PodFitsResources
判断备选节点的资源是否满足备选Pod的需求,即节点的剩余资源满不满足该Pod的资源使用。
- 计算备选Pod和节点中已用资源(该节点所有Pod的使用资源)的总和。
- 获取备选节点的状态信息,包括节点资源信息。
- 如果(备选Pod+节点已用资源>该节点总资源)则返回false,即剩余资源不满足该Pod使用;否则返回true。
3.3. 3.3. PodSelectorMatches
判断节点是否包含备选Pod的标签选择器指定的标签,即通过标签来选择Node。
- 如果Pod中没有指定spec.nodeSelector,则返回true。
- 否则获得备选节点的标签信息,判断该节点的标签信息中是否包含该Pod的spec.nodeSelector中指定的标签,如果包含返回true,否则返回false。
3.4. 3.4. PodFitsHost
判断备选Pod的spec.nodeName所指定的节点名称与备选节点名称是否一致,如果一致返回true,否则返回false。
3.5. 3.5. CheckNodeLabelPresence
检查备选节点中是否有Scheduler配置的标签,如果有返回true,否则返回false。
3.6. 3.6. CheckServiceAffinity
判断备选节点是否包含Scheduler配置的标签,如果有返回true,否则返回false。
3.7. 3.7. PodFitsPorts
判断备选Pod所用的端口列表中的端口是否在备选节点中已被占用,如果被占用返回false,否则返回true。
4. 4. 优选策略
4.1. 4.1. LeastRequestedPriority
优先从备选节点列表中选择资源消耗最小的节点(CPU+内存)。
4.2. 4.2. CalculateNodeLabelPriority
优先选择含有指定Label的节点。
4.3. 4.3. BalancedResourceAllocation
优先从备选节点列表中选择各项资源使用率最均衡的节点。
参考《Kubernetes权威指南》














 6305
6305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









