







简要步骤
简单选择排序与冒泡排序的区别在于:简单选择排序直接将待排位置的数据与其他未排位置的数据比较,若为反序则交换;而冒泡排序则是将相邻的反序数据进行交换,所以在性能上简单选择排序是略优于冒泡的。
初始序列:{ 4, 6, 3, 0, 2, 5, 1 }
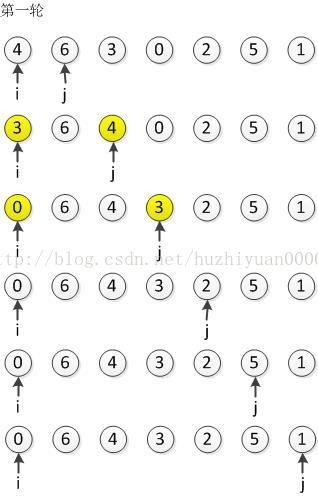
可以通过比较简单选择排序和冒泡排序在同一初始序列上的第一轮扫描过程,不难发现前者的优势,下面是冒泡排序的博客地址:
http://blog.csdn.net/huzhiyuan0000000/article/details/76697090
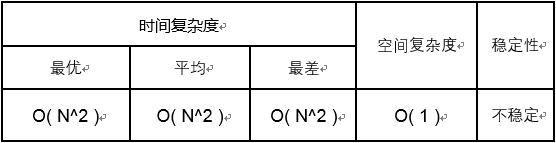
性能分析
时间复杂度:简单选择排序和冒泡排序的平均时间复杂度相同,同样为O( N^2 )。但是当数据正序时,冒泡排序只需要一轮扫描就可以知道数据是正序的,所以冒泡排序的最优时间复杂度是O( N );与冒泡不同,简单选择排序通过一轮扫描并不能知道是不是所有的数据都在正确的位置上,只能知道当前待排位置上的数据是否正确,所以简单选择排序的最优,最差时间复杂度都是O( N^2 )。
空间复杂度:在数据交换时,需要额外一个辅助空间,空间复杂度为O( 1 )。
稳定性:简单选择排序有稳定的版本,但是就本文的实现方法而言是不稳定的,以序列{ 2, 2, 1 }为例,第一个{ 2 }会和{ 1 }交换,导致两个{ 2 }的顺序改变。
优化
我们以序列{5, 4, 3, 2, 1}为例:
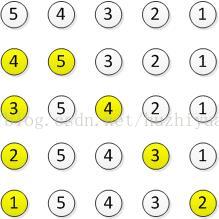
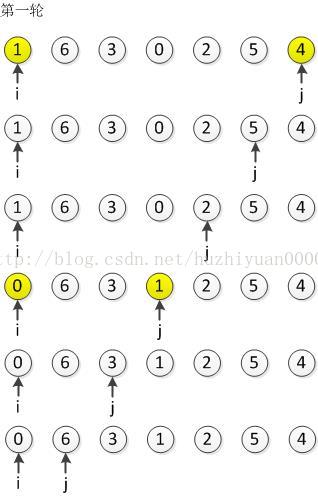
在第一轮扫描中上面的代码竟然交换了4次,而且比较小的数据{ 2 }也被移到了末尾,那么我们如何才能尽量避免这种情况呢?当从前往后扫描时,较小值会移动末尾,那么从后往前扫描呢?为了比较方便,给出序列{ 4, 6, 3, 0, 2, 5, 1 }从尾到头的第一轮扫描过程:
代码
为了方面比较,已经将返回值设为交换次数。
#include <stdio.h>
#include <stdlib.h>
void Swap(int *a, int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
/*
* 从前往后扫描的简单选择排序
*/
int SimpleSelectionSort1(int arr[], int length)
{
int count = 0;
if(arr == NULL || length < 0)
{
printf("\n输入错误!");
exit(-1);
}
for (int i = 0; i < length-1; i++)
for (int j = i+1; j < length; j++)
if (arr[i] > arr[j])
{
count++;
Swap(&arr[i], &arr[j]);
}
return count;
}
/*
* 从后往前扫描的简单选择排序
*/
int SimpleSelectionSort2(int arr[], int length)
{
int count = 0;
if(arr == NULL || length < 0)
{
printf("\n输入错误!");
exit(-1);
}
for(int i = 0; i < length-1; i++)
for(int j = length-1; j > i; j--)
if(arr[i] > arr[j])
{
count++;
Swap(&arr[i], &arr[j]);
}
return count;
}
int main()
{
int count;
int arr[] = {4,6,3,0,2,5,1};
int length = sizeof(arr)/sizeof(arr[0]);
printf("排序前:");
for(int i=0; i<length; i++)
{
printf(" %d",arr[i]);
}
// count = SimpleSelectionSort1(arr, length);
count = SimpleSelectionSort2(arr, length);
printf("\n排序后:");
for(int i=0; i<length; i++)
{
printf(" %d",arr[i]);
}
printf("\n交换次数: %d",count);
return 0;
}













 3919
3919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









