







1.简介
这是一个非常简单的实例,主要是为了这个简单的实例了解caffe的工作流程。
2.操作流程
1.获取数据
在caffe-master/data/mnist文件夹中只有一个get_mnist.sh可执行文件,我们需要执行这个文件获取mnist所需要的数据。
- 执行命令:
./data/mnist/get_mnist.sh - get_mnist.sh源码解析:
通过源码我们可以知道,这个脚本主要是下载t10k-images-idx3-ubyte t10k-labels-idx1-ubyte train-images-idx3-ubyte train-labels-idx1-ubyte 这四个文件 然后解压 - 执行完命令后的文件目录:
get_mnist.sh文件是原有的,其他四个文件是下载的。

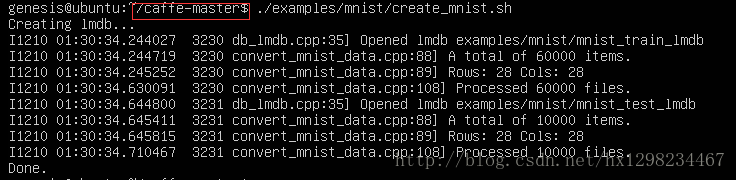
2.将数据转化为lmdb格式
- 命令:./examples/mnist/create_mnist.sh
- 注意:在这里可能会遇到一个bug,如下:
- 问题描述:
- 原因是:脚本运行必须在caffe文件夹的根目录下运行,,而我在examples/mnist/目录下运行脚本,所以报错。
- 问题描述:

3.训练
命令:./examples/mnist/train_lenet.sh
train_lenet.sh源码解析:
- 源码:
- 解释:train是我们在安装caffe的时候已经编译好的二进制文件,tools文件夹中还有很多工具,训练调用的是caffe源码中tools文件夹中的二进制文件,solver后面跟的是定义优化方式的prototxt文件
- 源码:
注意:训练的时候,如果安装的时候选择了CPU_ONLY的话,在*.prototxt文件中,把“mode:GPU”改成“mode:CPU”
lenet_solver.prototxt文件源码解析:


4.结果
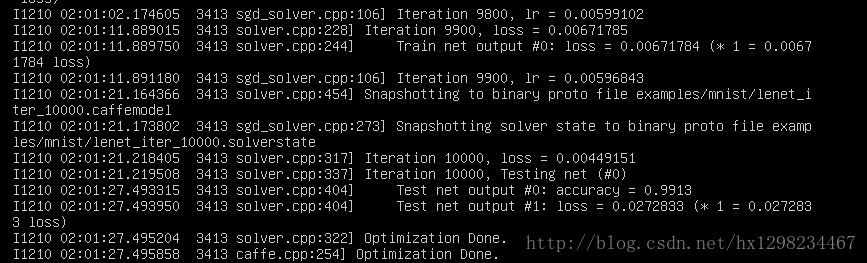
这里仅用CPU进行训练,大概用15分钟左右,准确率为99.13%。














 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









