







参与第五届泰迪杯,侥幸获得二等奖,简单记录一下。
一、问题的背景
在当今的大数据时代里,伴随着互联网和移动互联网的高速发展,人们产生的数据总量呈现急剧增长的趋势,当前大约每六个月互联网中产生的数据总量就会翻一番。互联网产生的海量数据中蕴含着大量的信息,已成为政府和企业的一个重要数据来源,互联网数据处理也已成为一个有重大需求的热门行业。借助网络爬虫技术,我们能够快速从互联网中获取海量的公开网页数据,对这些数据进行分析和挖掘,从中提取出有价值的信息,能帮助并指导我们进行商业决策、舆论分析、社会调查、政策制定等工作。但是,大部分网页数据是以半结构化的数据格式呈现的,我们需要的信息在页面上往往淹没在大量的广告、图标、链接等“噪音”元素中。如何从网页中有效提取所需要的信息,一直是互联网数据处理行业关注的重点问题之一。
二、问题目标
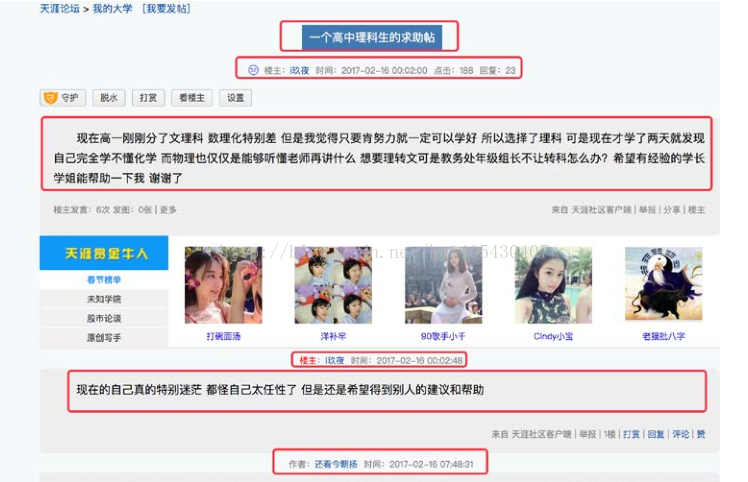
对于任意 BBS 类型的网页,获取其 HTML 文本内容,设计一个智能提取该页面的主贴、所有回帖的算法。如下面的网页截图所示,提取主贴和回帖的区域,提取出相应数据字段(只需要提取文本, 图片、视频、音乐等媒体可以直接忽略),并按规定的数据格式(Json 格式)存储。
重要说明:
1. Json 数据字段说明:
post :主题帖
author: 用户名
title:标题
content:帖子内容
publish_date:帖子的发布日期,格式: yyyy-MM-dd
replys: 该页的回帖列表
每条回帖的主要字段同 post, 若回帖无 title 字段,可为空
2. 算法要求:
算法必须具有通用性,必须支持互联网的任意类型 BBS 网站,不得只针对附件所
给的样例网站、或特定类型的开源论坛(例如 discuz、phpwind)
二、数据样例
对于任意 BBS 类型的网页,获取其 HTML 文本内容,设计一个智能提取该页面的主贴、所有回帖的算法。如下面的网页截图所示,提取主贴和回帖
1. 样例输入数据格式:(每行一条论坛的内容页的 url)
http://bbs.tianya.cn/post-stocks-1841155-1.shtml (包含主贴的 url)
http://bbs.tianya.cn/post-stocks-1841155-3.shtml (不包含主贴的 url)
2. 样例输出数据格式(必须按如下格式提交结果):
每行数据有 {原始 url}\t {提取结果的 json 字符串}, 表示某一个 html 页面(url)提取出来的数据,示例数据格式:http://x.heshuicun.com/forum.php?mod=viewthread&tid=80 {"post":{"content":"本帖最后由 临风有点冷 于 2012-7-27 08:26 编辑 从这条新闻中你得到了什么教训 在网上看个新闻,大概内容是:老公买了一只藏獒幼仔,没时间养,一直是老婆在养;一次老公老婆吵架,老公把老婆打了,结果藏獒冲出来果断把老公手咬断了!看完新闻我问老公:“从这条新闻中你得到了什么教训?” 本想听他说不能打老婆,没想到这货居然说:“ 游客,如果您要查看本帖隐藏内容请回复”","title":"从这条新闻中你得到了什么教训?","publish_date":"20120727"},"replys":[{"content":"的分数高如果认购二哥让他退给我","title":"从这条新闻中你得到了什么教训?
","publish_date":"20160904"},{"content":"1231231231321321","title":"从这条新闻中你得到了什么教训?","publish_date":"20161115"},{"content":"","title":"从这条新闻中你得到了什么教训?","publish_date":"20161208"}]}
三、解题
对于任意论坛来说,每个楼层之间的html代码结构必为相似的,所以第一步,通过枚举+结构对比的方式,提取出一个楼层的html代码。如下图:
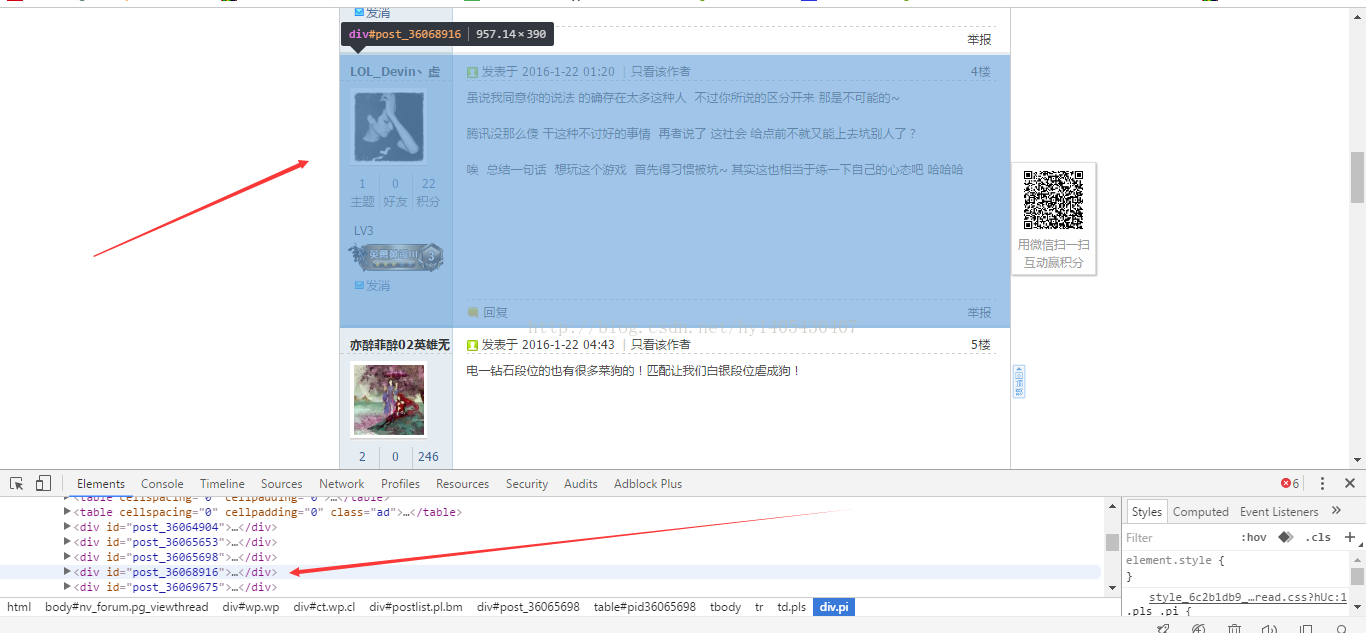
可以看懂啊,每层楼都被一个id为post_xxxxx的div包含在内。
继续提取作者信息,作者信息我们使用了两种思路研究,一种是直接标签提取,作者一般会在有author这样的标签中,我们罗列了以下标签:
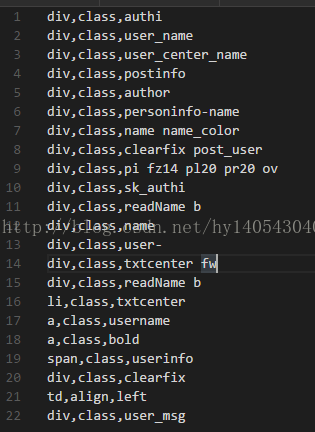
第二种思路算是有点奇淫巧技,对于大多数论坛内的楼层,作者一半位于最左上角,也就是第一个有实际内容的a标签:
def getAuthor(document): #可以精确分割bbs时提取作者
soup = BeautifulSoup(document,'html.parser')
alist = soup.find_all('a')
#print('author')
for i in alist:
if len(i.get_text())>0:
# print(i.get_text())
return i.get_text()
#print('me')
return '' 正文内容,使用标签提取以及基于文本密度模型的Web正文抽取方法,在提取时会遇到一些干扰因素,罗列并过滤:

关键代码放出来,没有认真整理,比较烂:
extractor.py
import requests as req
import re
DBUG = 0
reBODY = r'<body.*?>([\s\S]*?)<\/body>'
reCOMM = r'<!--.*?-->'
reTRIM = r'<{0}.*?>([\s\S]*?)<\/{0}>'
reTAG = r'<[\s\S]*?>|[ \t\r\f\v]'
reIMG = re.compile(r'<img[\s\S]*?src=[\'|"]([\s\S]*?)[\'|"][\s\S]*?>')
class Extractor():
def __init__(self, url = "", blockSize=5, timeout=5, image=False):
self.url = url
self.blockSize = blockSize
self.timeout = timeout
self.saveImage = image
self.rawPage = ""
self.ctexts = []
self.cblocks = []
def getRawPage(self):
try:
resp = req.get(self.url, timeout=self.timeout)
except Exception as e:
raise e
if DBUG: print(resp.encoding)
resp.encoding = resp.apparent_encoding
return resp.status_code, resp.text
#去除所有tag,包括样式、Js脚本内容等,但保留原有的换行符\n:
def processTags(self):
self.body = re.sub(reCOMM, "", self.body)
self.body = re.sub(r'<img.*?>','',self.body)
self.body = re.sub(reTRIM.format("script"), "" ,re.sub(reTRIM.format("style"), "", self.body))
# self.body = re.sub(r"[\n]+","\n", re.sub(reTAG, "", self.body))
self.body = re.sub(reTAG, "", self.body)
#将网页内容按行分割,定义行块 blocki 为第 [i,i+blockSize] 行文本之和并给出行块长度基于行号的分布函数:
def processBlocks(self):
self.ctexts = self.body.split("\n")
self.textLens = [len(text) for text in self.ctexts]
self.cblocks = [0]*(len(self.ctexts) - self.blockSize - 1)
lines = len(self.ctexts)
for i in range(self.blockSize):
self.cblocks = list(map(lambda x,y: x+y, self.textLens[i : lines-1-self.blockSize+i], self.cblocks))
print(self.cblocks)
print(lines)
maxTextLen = max(self.cblocks)
if DBUG: print(maxTextLen)
self.start = self.end = self.cblocks.index(maxTextLen)
print(self.start,self.end,maxTextLen)
while self.start > 0 and self.cblocks[self.start] > min(self.textLens):
self.start -= 1
while self.end < lines - self.blockSize and self.cblocks[self.end] > min(self.textLens):
self.end += 1
return "\n".join(self.ctexts[self.start:self.end])
#如果需要提取正文区域出现的图片,只需要在第一步去除tag时保留<img>标签的内容:
def processImages(self):
self.body = reIMG.sub(r'{{\1}}', self.body)
#正文出现在最长的行块,截取两边至行块长度为 0 的范围:
def getContext(self):
code, self.rawPage = self.getRawPage()
self.body = re.findall(reBODY, self.rawPage)[0]
if DBUG: print(code, self.rawPage)
if self.saveImage:
self.processImages()
self.processTags()
return self.processBlocks()
# print(len(self.body.strip("\n")))
separateAttribute.py
from bs4 import BeautifulSoup
import codecs
import re
#document为html的Str
#根据标签获得信息如果获得的信息为空则返回空字符串
#path为文本路径
#标签格式为: 标签名,属性,属性值 例如div,class,authi
def del_content_blank(s):
clean_str = re.sub(r'\r|\n| |\xa0|\\xa0|\u3000|\\u3000|\\u0020|\u0020', '', str(s))
return clean_str
def getContent(document,path):
soup = BeautifulSoup(document,'html.parser')
list = []
results = []
for line in codecs.open(path,"rb","utf8"):
a = line.replace("\n", "").split(",")
list.append(a)
for i in list:
results = soup.select(i[0] + '[' + i[1] + '^=' + '"' + del_content_blank(i[2]) + '"]')
if (len(results) != 0):
break;
if (len(results) != 0):
soup = BeautifulSoup(str(results[0]), 'html.parser')
return soup.text
else:
return ""
def getAuthor(document): #可以精确分割bbs时提取作者
soup = BeautifulSoup(document,'html.parser')
alist = soup.find_all('a')
#print('author')
for i in alist:
if len(i.get_text())>0:
# print(i.get_text())
return i.get_text()
#print('me')
return ''
def getAuth(document):
#print('auth')
soup = BeautifulSoup(document,'html.parser')
list = []
for line in codecs.open("author.txt","rb","utf8"):
a = line.replace("\n", "").split(",")
list.append(a)
for i in list:
results = soup.select(i[0] + '[' + i[1] + '^=' + '"' + del_content_blank(i[2]) + '"]')
if (len(results) != 0):
break;
if (len(results) != 0):
soup = BeautifulSoup(str(results[0]), 'html.parser')
return soup.get_text()
else:
return ""
#text为除去标签后的信息
#得到时间
def getTimeByRegular(text):
#print(text)
a=re.search("发表于\s*[2][0]\d{2}-\d+-\d+", text)
#print(a.group())
if(a!=None):
return a.group()
else:
a=re.search("发表于[2][0]\d{2}-\d+-\d+",text)
if(a!=None):
return a.group()
else:
a=re.findall("[2][0]\d{2}-\d+-\d+",text)
#print(a)
if(len(a)>0):
return a[0]
else:
return ''
#text为去掉标签后的信息(ps:不要去掉空格以及换行符)
#过滤掉不需要的信息
def filterinfo(text,author,time):
result=''
strs=text.split("\n")
texts=[];
removelist=[]
for str in strs:
if(str!=''):
texts.append(str)
#print(texts)
for str in texts:
file=codecs.open("redundant.txt","rb","utf8")
lines=file.readlines();
for line in lines:
a=del_content_blank(line)
conut=re.findall(a, str)
if(len(conut)!=0):
removelist.append(str)
break;
conut = re.findall(time,str)
if(len(conut)!=0):
removelist.append(str)
break;
conut = re.findall(author,str)
if(len(conut)!=0):
removelist.append(str)
break;
file.close()
l = list(set(removelist))
for remove in l:
texts.remove(remove)
for tex in texts:
result+=tex+"\n"
return resultdo.py
from urllib.request import urlopen ,Request
from bs4 import BeautifulSoup
from extractor import Extractor
from separateAttribute import filterinfo,getTimeByRegular,getAuthor,getContent,getAuth
import urllib
import re
import time
import json
import socket
from collections import OrderedDict
socket.setdefaulttimeout(10)
def del_content_blank(s):
clean_str = re.sub(r'\r|\n| |\xa0|\\xa0|\u3000|\\u3000|\\u0020|\u0020|\t', '', str(s))
return clean_str
def findmax(a):
res = []
length = -1
for i in a:
if(len(i)>length):
length = len(i)
res = i
return res
def Tagtostring(a):
s = str(a)
s=re.sub(r'<\s*script[^>]*>[^<]*<\s*/\s*script\s*>','',s) #过滤script
s=re.sub(r'<style.*?>.*?</style>','',s) #过滤css
s=re.sub(r'<!--.*?-->','',s) #过滤注释
s=re.sub(r'<img.*?>','',s)
return s
def judge(a,b):
al=[]
bl=[]
for j in (a.descendants):
al.append(j.name)
for j in (b.descendants):
bl.append(j.name)
f = 0
for i in range(5):
if al[i] == bl[i]:
f+=1
if f>4:
return True
else:
return False
def connect(url):
try:
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
req = Request(url=url,headers=head)
res = urlopen(req)
H = BeautifulSoup(res,"html.parser",from_encoding="GB2312")
return H
except (urllib.error.HTTPError, urllib.error.URLError, socket.timeout, ConnectionAbortedError,ConnectionResetError) as e:
return {"replys": [], "post": {"content": "", "publish_data": "", "author": "", "title": ""}}
def gettitle(H):
if H.title is None:
return 'title'
else:
title = str(H.title.get_text())
return title
def getinfo(H,url):
dic = {}
if type(H)==type(dic):
return
else:
j = H.find('title') #type tag
rule = ['link','meta','link','script','a','li','html','head','input','span','font','form','dt','p',
'i','ul','ol','dl','br','b','img','noscript','dd','body','title']
tlist = []
for i in H.descendants:
if type(i) == type(j):
if i.name in rule:
continue
tlist.append(i)
nlist = []
for i in tlist:
if len(list(i.descendants))>30 and len(re.findall(r'[2][0]\d{2}-\d+-\d+',Tagtostring(i)))>0:
nlist.append(i)
row = []
l = len(nlist)
for i in range(l):
t = []
t.append(i)
j = i + 1
while j < l:
if nlist[j].find_parent() == nlist[i].find_parent() and judge(nlist[i],nlist[j]): #判断父节点和子节点结构相似性
t.append(j)
j+=1
row.append(t)
res = findmax(row)
authlist = []
timelist = []
conlist = []
if len(res)<2: #只有一层楼 采用文本密度提取
ext = Extractor(url=url,blockSize=6, image=False)
content = ext.getContext()
#content = Document(str(H)).summary()
#content = re.sub(r'<.*?>','',content)
#content = re.sub(r'</.*?>','',content)
conlist.append(content)
#print('content:',content)
auth = getAuth(str(H))
authlist.append(auth)
#print('auth:',auth)
time = getTimeByRegular(str(H))
timelist.append(time)
#print('time',time)
else:#帖子较多时,通过分割楼层提取
for i in res:
#print('====:',nlist[i]) #type tag
s = Tagtostring(nlist[i])
author = getAuthor(s)
authlist.append(author)
#print('author:',author)
time = getTimeByRegular(s)
timelist.append(time)
#print('time:',time)
content =getContent(s,"content.txt")
#print('content:',content)
if content =='':
content =filterinfo(BeautifulSoup(s,'html.parser').get_text(),author,time)
#print(content)
conlist.append(content)
#print("********************\n")
return authlist,timelist,conlist
def formattime(time):
res = []
for i in time:
i=re.search("[2][0]\d{2}-\d+-\d+",i)
if i!=None:
res.append(i.group())
return res
def do(url):
H = connect(url)
dic = {}
if type(H) == type(dic):
return {"replys": [], "post": {"content": "", "publish_data": "", "author": "", "title": ""}}
auth,time,content = getinfo(H,url)
time = formattime(time)
#print('time',time)
#print(auth,time,content)
title = gettitle(H)
res = {}
length =len(auth)
f ='{'+'\"post\":{\"content\":\"'+del_content_blank(content[0])+'\",\"author\":\"'+auth[0]+'\",\"title\":\"'+title+'\",\"publish_data\":\"'+time[0]+'\"'+ '},';
f+='\"replys\":['
for i in range(1,length):
f+='{\"content\":\"'+del_content_blank(content[i])+'\",\"author\":\"'+auth[i]+'\",\"title\":\"'+'\",\"publish_data\":\"'+time[i]+'\"'+ '}'
if i!=length-1:
f+=','
f+=']}'
print(f)
#print(f)
return f
do("http://bbs.lol.qq.com/forum.php?mod=viewthread&tid=3067734&extra=page%3D1")

json解析一下:
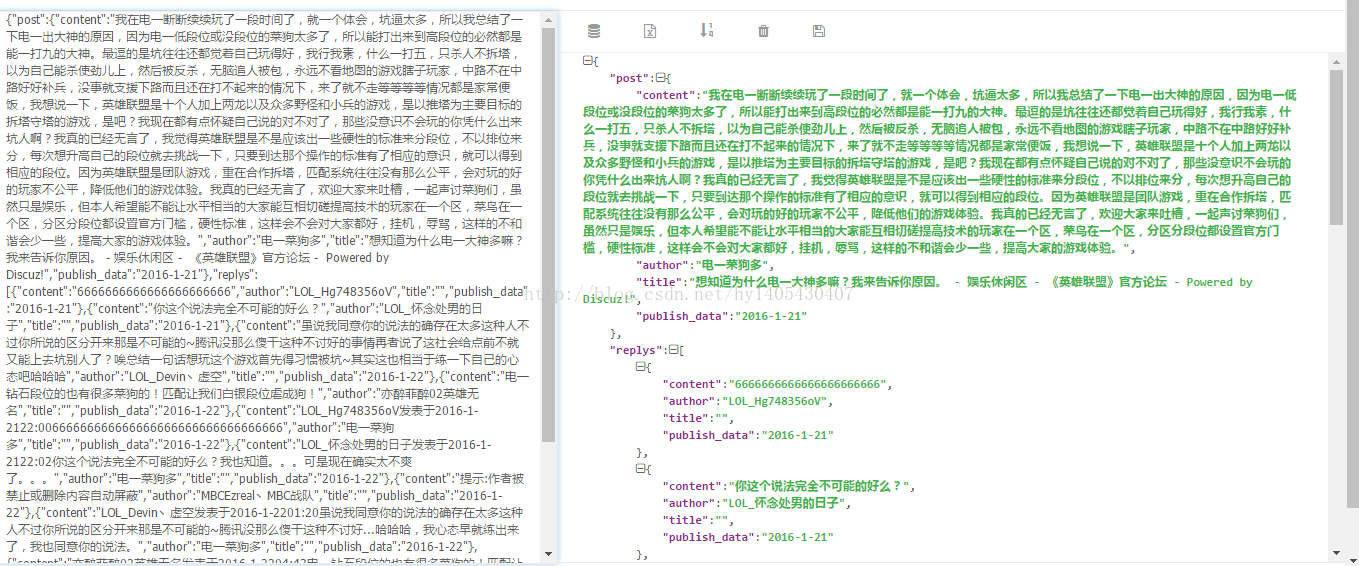














 6622
6622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









