







目录
1 文章说明
这周学习了一篇文章,文章的名字叫做FlowNet: Learning Optical Flow with Convolutional Networks。
这篇文章已经发布在IEEE International Conference on Computer Vision (ICCV), 2015。

一般的卷积神经网络都被用来进行分类,最近的一些神经网络结构可以用于对每个像素点进行预测。
这篇文章主要介绍的就是他们把一般的卷积神经网络去掉全连接层,改成两个网络,一种是比较一般普通的全是卷积层的神经网络,另一个除了卷积层之外还包括一个关联层。并且对这两种网络分别进行点对点的训练,使网络能从一对图片中预测光流场,每秒达到5到10帧率,并且准确率也达到了业界标准。
文章下载地址:http://lmb.informatik.uni-freiburg.de/Publications/2015/DFIB15/
实现代码地址:http://lmb.informatik.uni-freiburg.de/resources/binaries/
该作者的其他文章:http://lmb.informatik.uni-freiburg.de/research/convnets/
相关视频资料(需要跳墙):https://www.youtube.com/channel/UC351jap1wiOJvKXr3mhODlg
2 光流原理
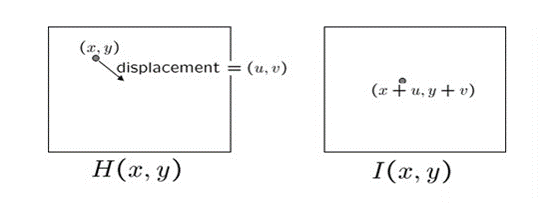
光流原理网上有很多,简单来说, 是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
光流实现的假设前提:
1.相邻帧之间的亮度恒定。
2.相邻视频帧的取帧时间连续,或者,相邻帧之间物体的运动比较“微小”。
3.保持空间一致性;即,同一子图像的像素点具有相同的运动。
因为光流的预测涉及到每个像素点的精确的位置信息,这不仅涉及到图像的特征,还涉及到两个图片之间对应像素点的联系,所以用于光流预测的神经网络与之前的神经网络不同。
3 神经光流网络结构介绍
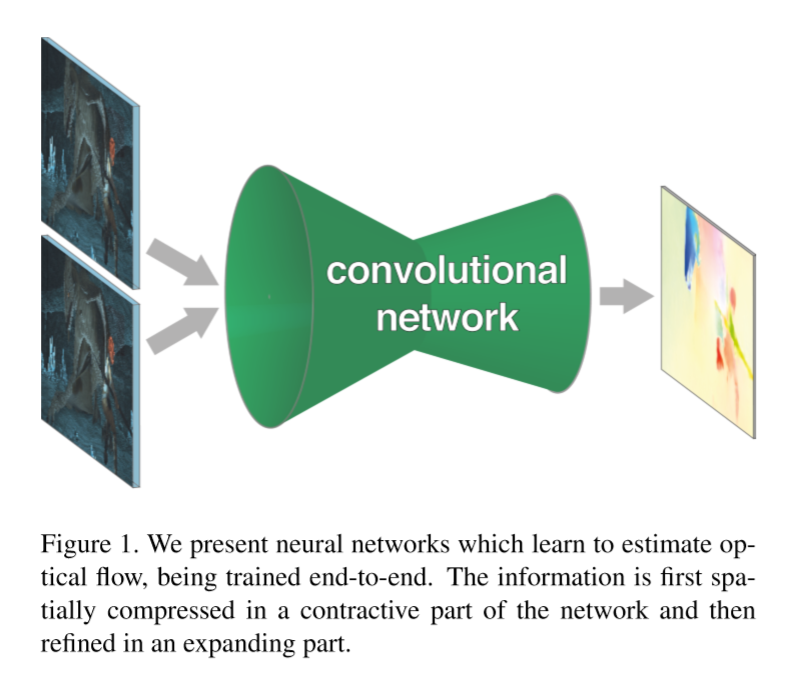
他们的两个神经网络大体的思路就是这样。
首先他们有一个收缩部分,主要由卷积层组成,用于深度的提取两个图片的一些特征。
但是pooling会使图片的分辨率降低,为了提供一个密集的光流预测,他们增加了一个扩大层,能智能的把光流恢复到高像素。
他们用back progation 对这整个网络进行训练。
3.1 收缩部分网络结构
flownetsimple结构
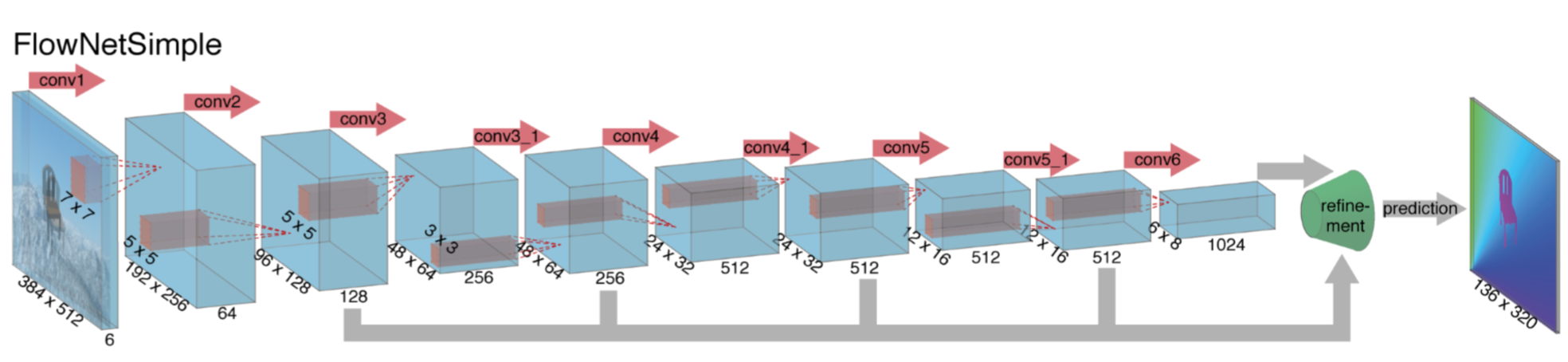
一个简单的实现方法就是把输入的图片对叠加在一起,让他们通过一个比较普通的网络结构,让这个网络来决定如何从这一图片对中提取出光流信息, 这一只有卷积层组成的网络叫做flownetsimple。
这种卷积网络有九个卷积层,其中的六个stride为2, 每一层后面还有一个非线性的relu操作,这一网络没有全连接层,所以这个网络不能够把任意大小的图片作为输入,卷积filter随着卷积的深入递减,第一个7*7,接下来两个5*5,之后是3*3,featuremaps因为stride是2每层递增两倍。
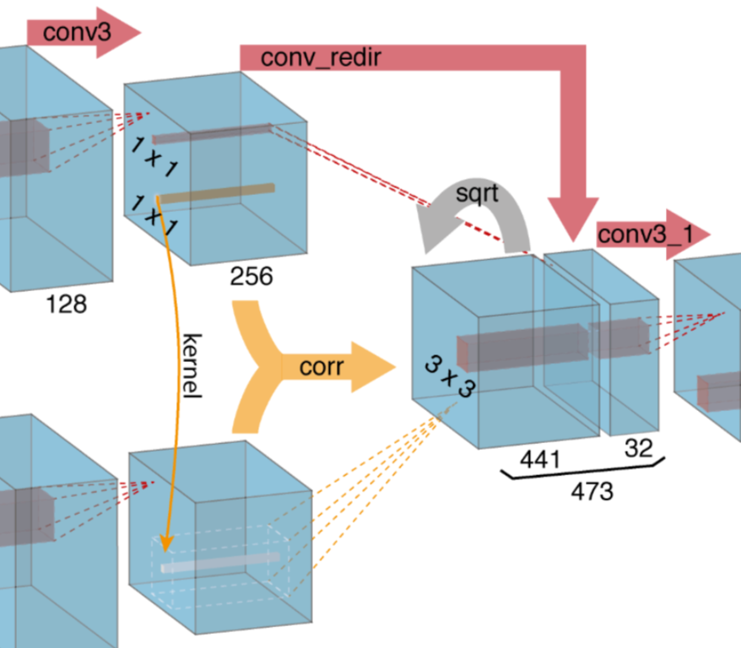
flownetcorr结构
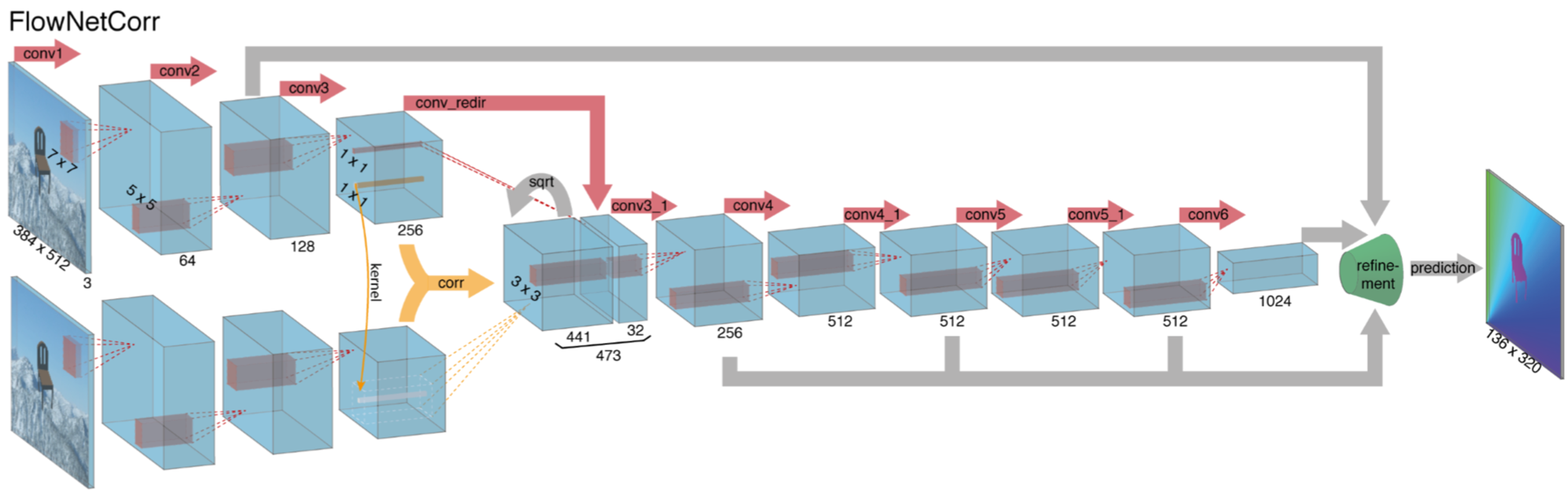
另一个方式 网络先独立的提取俩图片的特征,再在高层次中把这两特征混合在一起。
这与正常的匹配的方法一致,先提取两个图片的特征,再对这些特征进行匹配,这个网络叫做flownetcorr。
如果展开来看他的关联层:
这一步的公式如下:
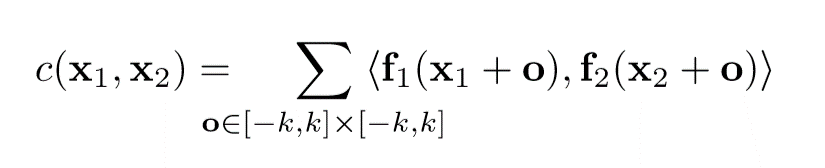
这一公式相当与神经网络的一步卷积层,但普通的卷积是与filter进行卷积,这个是两个数据进行卷积,所以它没有可以训练的权重。
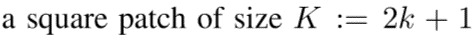
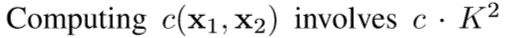
这一公式有ck2的运算, 为了计算速度的原因,我们限制最大的比较位移值。
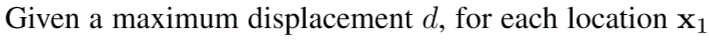
3.2 放大部分网络结构
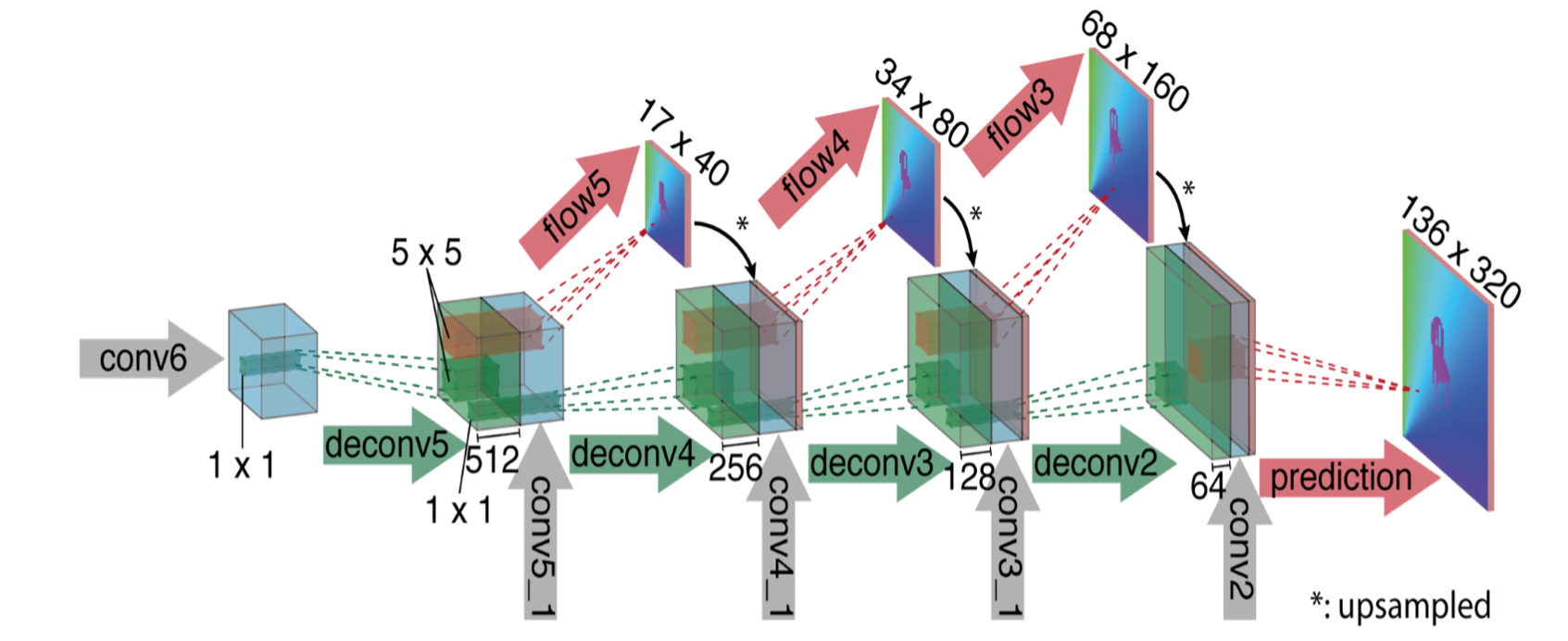
扩大部分主要是由上卷基层组成,上卷基层由unpooling(扩大featuremap,与pooling的步骤相反)和一个卷积组成,我们对featuremaps使用upconvolution,并且把它和收缩部分对应的feature map(灰色箭头)以及一个上采样的的光流预测(红色)联系起来。每一步提升两倍的分辨率,重复四次,预测出来的光流的分辨率依然比输入图片的分辨率要小四倍。
这一部的意义就是:
This way we preserve both the high-level information passed from coarser feature maps and fine local information provided in lower layer feature maps.
文章中说在这个分辨率时再接着进行双线性上采样的refinement已经没有显著的提高。
所以采用优化方式:the variational approach 。
记为 +v,这一层需要更高的计算量,但是增加了流畅性,和subpixel-accurate flow filed。
4 训练数据集
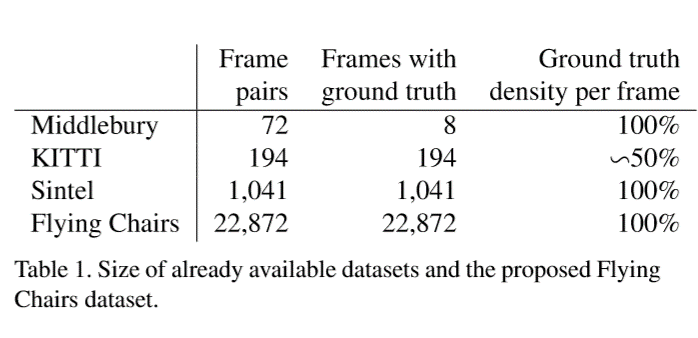
使用了四种数据集,前三种是目前比较常见的训练光流所用的数据集,flying chairs是文章自己创建的数据集。
这些数据集的相关资料视频在google和youtube上都可以查到,其中:
Middlebury数据集:用于训练的图片对只有8对,从图片对中提取出的,用于训练光流的ground truth用四种不同的技术生成,位移很小,通常小于10个像素。
Kitti数据集:有194个用于训练的图片对,但只有一种特殊的动作类型(类似行车记录仪?),并且位移很大,视频使用一个摄像头和ground truth由3D激光扫描器得出,远距离的物体,如天空没法被捕捉,导致他的光溜ground truth比较稀疏。
Mpi sintel数据集:是从人工生成的动画sintel中提取训练需要的光流ground truth,是目前最大的数据集,每一个版本都包含1041个可一用来训练的图片对,提供的gt十分密集,大幅度,小幅度的运动都包含。
sintel数据集包括两种版本:
sintel final:包括运动模糊和一些环境氛围特效,如雾等。
sintel clean:没有上述final的特效。
现在的这些数据集在物体和运动特征上都不相同,为了增加正确率,我们针不同的数据集对网络进行优化,相关的优化方法就是fine-tunning,记为+ft。
用于训练大规模的cnns,sintel的dataset依然不够大,所以作者他们自己弄出来一个flying chairs数据集。
4.1 flying chairs数据集

这一数据集背景是来自flickr的标签为‘city’,‘landscape’,‘mountain’的1024*768像素的图片,剪切成四分之一,用512*384作为背景。
前景是可以得到的可以生成的3d椅子模型,从这些模型中去掉一些相似的椅子模型,留下809种椅子,每一种有62个视角。
为了产生运动信息,产生第一张图片的时候会随机产生一个位移变量,与背景图片与椅子位移相关, 再通过这种位移变量产生第二个图片和光流。
每一个图像对的这些变量,包括,椅子的类型,数量,大小,和产生的位置都是随机的,位移向量也是随机的产生的。
尽管flying-chair数据集已经很大,但是为了避免过拟合,而采用了data Augmentation的方法,让数据扩大,样式变多,不单调,防止分类变得严格。
数据增多的方法包括给原图像位移,反转,方法,加高斯噪音,改变亮度,对比对,gamma值和,颜色,这一操作都用gpu生成。
效果如下:

训练cnn使用是修改版的caffe 框架,用adam作为优化方式,每一个像素都是训练样本。
5 实验与结果分析
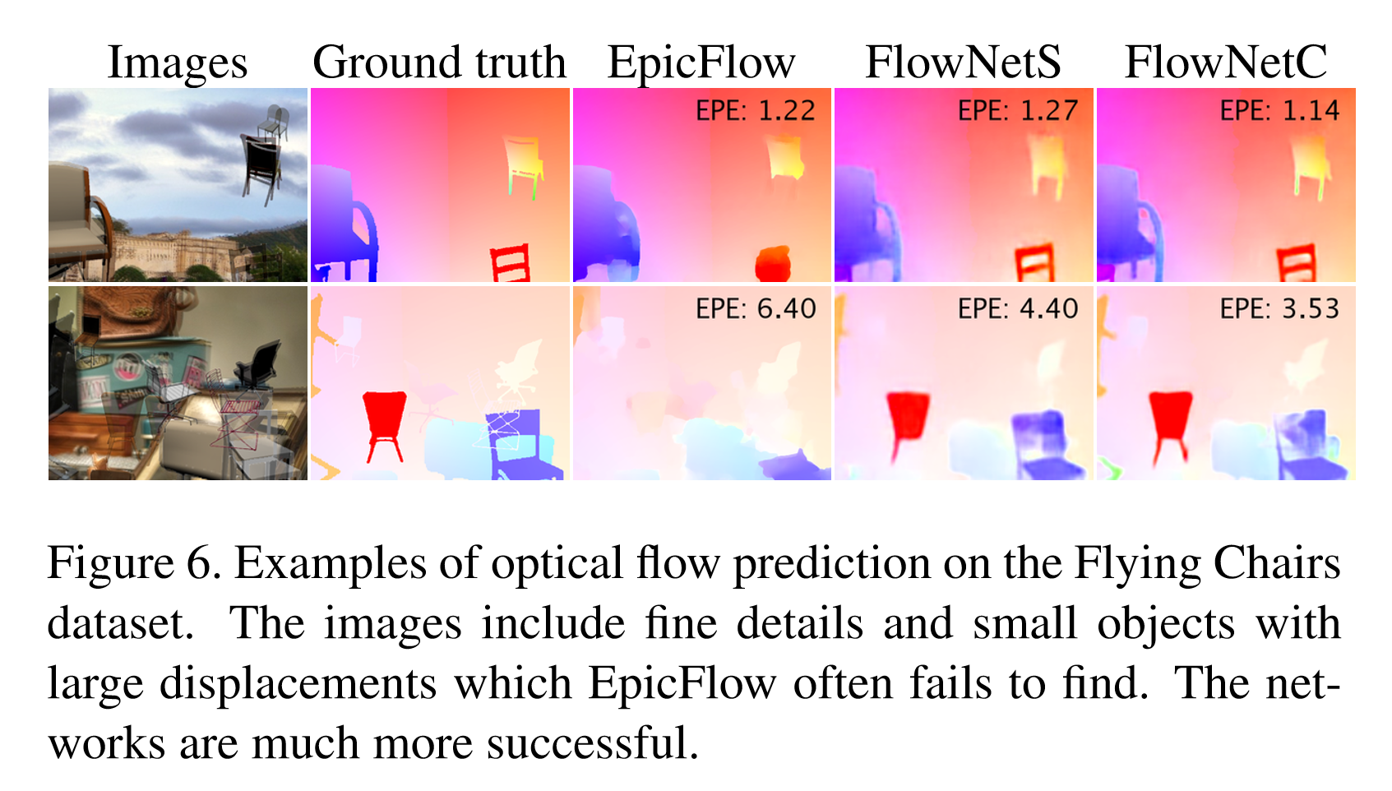
三种光流预测方法在飞椅子数据集上预测的表现
其中:EPE是一种对光流预测错误率的一种评估方式。
指所有像素点的gound truth和预测出来的光流之间差别距离(欧氏距离)的平均值。
可以看见Epicflow 这个很好的预测方法,但在一些大位移的情况下会找不到光流,而两种flownet好于它。
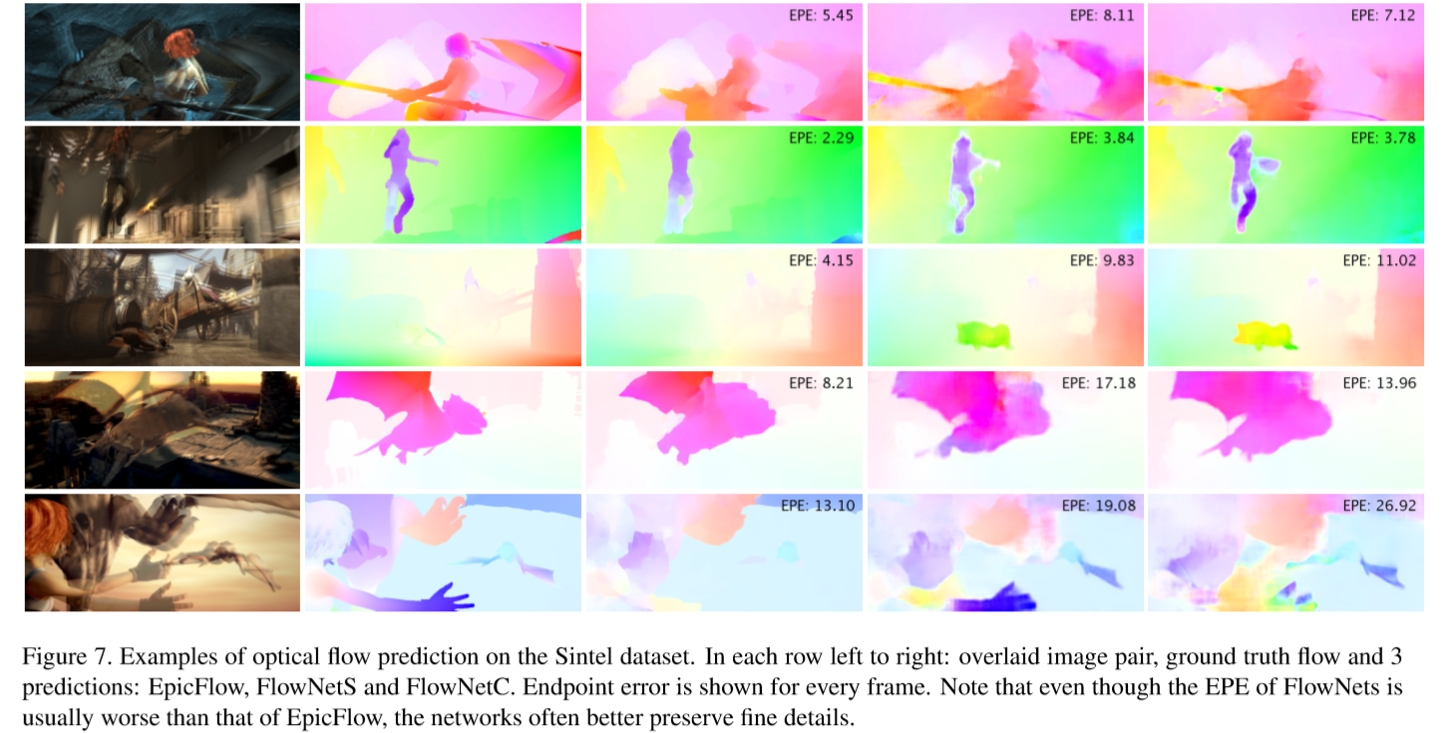
三种光流预测方法使用sinte数据集测试的光流预测效果
尽管flownet的正确率很烂,但是他能保存留下更多的细节信息(文章里说的)。
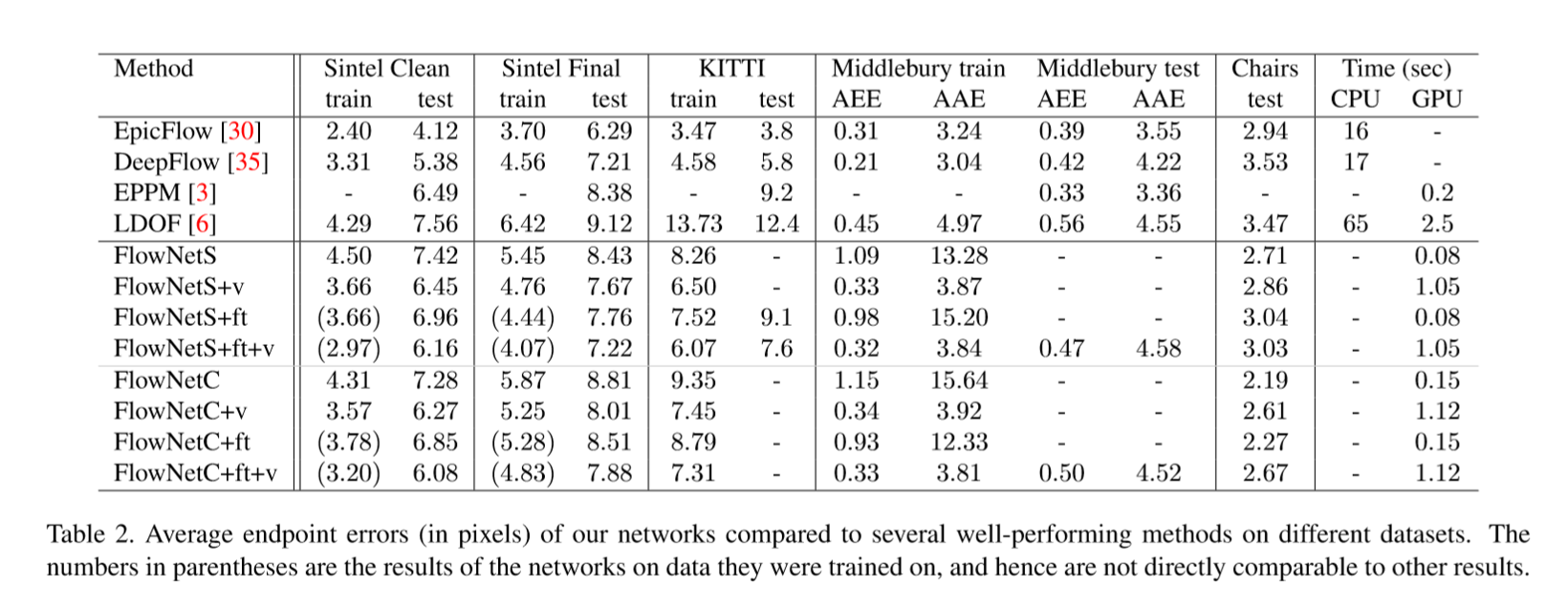
Sintel Clean数据集中: flownetc比flownets要好。
Sintel Final数据集中:相正好反,flownets比flownetc要好。可以看见在fls+ft+v时候的错误率甚至可与deepflow比肩。
Flyingchair数据集中:
Flownet大获全胜,其中c要比s好很多:
也仅仅只有在这一个数据集中,一些改善网络的方法,会使整个准确率下降,显然这个网络已经要比这些改善方式好很多
预示着,在训练集上更真实一些,flownet会比其他数据集表现的更好。
Kitti数据集中:Flownet很一般,c在位移比较大的情况下比s差一点。
Timming数据:文章中写到,一些方法只有在cpu上的runtimes运行库,flownet只在gpu上执行,NVIDIA GTX Titan GPU。
6 Flownetsimple与Flownetcorr对比
仅仅看数据会感觉flownetcorr虽然加了关联层,但与s对比并没有太大的改善,因为flownetsimple的正确率也已经很不错了,flownetcorr并没有太大的优势。
但的是flownetcorr在flyingchair和sintel clean数据集的表现要好于flownetsimple,注意到sintel clean是没有运动blur和fog特效等的,和flyingchair数据集比较类似,这意味着flownetcorr网络能更好的学习训练数据集,更加过拟合over-fitting(文章原话)。
所以如果使用更好的训练数据集,flownetcorr网络会更有优势。














 1308
1308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









