






1.shuffle操作
Shuffle是MapReduce框架中的一个特定的phase,介于Map phase和Reduce phase之间,当Map的输出结果要被Reduce使用时,输出结果需要按key哈希,并且分发到每一个Reducer上去,这个过程就是shuffle。由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。
2.SPARK 阔依赖 和窄依赖 transfer action lazy策略之间的关系
宽依赖 和窄依赖 说明该操作是 是否有shuffler 操作 成长(lineage )的来源
最有趣的部分是DAGScheduler。下面详解它的工作过程。RDD的数据结构里很重要的一个域是对父RDD的依赖。如图3所示,有两类依赖:窄(Narrow)依赖和宽(Wide)依赖。

窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区,和两个父RDD的分区对应于一个子RDD 的分区。图3中,map/filter和union属于第一类,对输入进行协同划分(co-partitioned)的join属于第二类。
宽依赖指子RDD的分区依赖于父RDD的所有分区,这是因为shuffle类操作,如图3中的groupByKey和未经协同划分的join。
窄依赖对优化很有利。逻辑上,每个RDD的算子都是一个fork/join(此join非上文的join算子,而是指同步多个并行任务的barrier): 把计算fork到每个分区,算完后join,然后fork/join下一个RDD的算子。如果直接翻译到物理实现,是很不经济的:一是每一个RDD(即使 是中间结果)都需要物化到内存或存储中,费时费空间;二是join作为全局的barrier,是很昂贵的,会被最慢的那个节点拖死。如果子RDD的分区到 父RDD的分区是窄依赖,就可以实施经典的fusion优化,把两个fork/join合为一个;如果连续的变换算子序列都是窄依赖,就可以把很多个 fork/join并为一个,不但减少了大量的全局barrier,而且无需物化很多中间结果RDD,这将极大地提升性能。Spark把这个叫做流水线 (pipeline)优化
transfer action 设计来源是 lazy evaluation 另外 scala 空间和rrd 空间的限制
这里有两个设计要点。首先是lazy evaluation。熟悉编译的都知道,编译器能看到的scope越大,优化的机会就越多。Spark虽然没有编译,但调度器实际上对DAG做了线性复 杂度的优化。尤其是当Spark上面有多种计算范式混合时,调度器可以打破不同范式代码的边界进行全局调度和优化。下面的例子中把Shark的SQL代码 和Spark的机器学习代码混在了一起。各部分代码翻译到底层RDD后,融合成一个大的DAG,这样可以获得更多的全局优化机会。
另一个要点是一旦行动算子产生原生数据,就必须退出RDD空间。因为目前Spark只能够跟踪RDD的计算,原生数据的计算对它来说是不可见的(除非以后 Spark会提供原生数据类型操作的重载、wrapper或implicit conversion)。这部分不可见的代码可能引入前后RDD之间的依赖,如下面的代码:
这里容易受到mr 模型的理解限制,直观上以为要shuffer 了就一定要执行,但实际是只有 action 方法 (要输出到rdd 以外的域(输出不是rdd) ,和要不要shuffer,要不要reduce没有关系,这里ACTION 的方法的reduce 和MR reduce 不是同一个东西 )才会导致提交作业并执行。
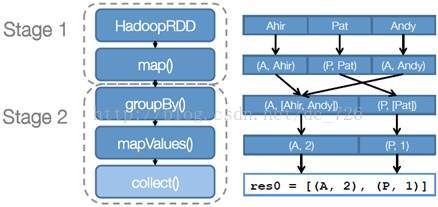
stage划分示意图
Hadoop job task
参考:http://www.myexception.cn/internet/1755297.html














 1612
1612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









