






损失函数:
除最小均方误差(mse)外 还有交叉熵(cross entropy)
交叉熵损失函数为:

对权重求导:

参考:http://blog.csdn.net/u012162613/article/details/44239919
word embedding
Distributed representation 用来表示词,通常被称为“Word Representation”或“Word Embedding”
最词向量表示一个词原来是one hot vector,出现或者我们关注的词可能非常大,那么这个词向量的维度很高。
word embedding是一种词向量降维方法。
比如六级词汇有7000个词,那么表示这个词的one hot vector是一个灰常稀疏的7000维度的向量。
word embedding把一个词转成比如128维的向量,每一维是一个浮点数,而且通过这种向量可以计算距离(距离可以描述词义的相近程度)
转化方法是基于词相关矩阵+神经网络、降维的方法。(具体我也不懂,直角坐标系抽象了空间的维度,128维抽象了词的维度)
参考:http://blog.sina.com.cn/s/blog_584a006e0101rjlm.html
KL距离
(Kullback-Leibler Divergence)又称相对熵,KL散度。
一个离散随机变量服从分布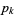 ,另一个离散随机变量服从分布
,另一个离散随机变量服从分布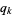 ,两个随机变量的KL距离为:
,两个随机变量的KL距离为:
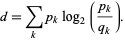
当两个水机变量的分布一致时,d=0。
Let a discrete distribution have probability function , and let a second discrete distribution have probability function . Then the relative entropy of 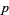 with respect to
with respect to 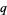 , also called the Kullback-Leibler distance, is defined by
, also called the Kullback-Leibler distance, is defined by
| |
Although 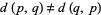 , so relative entropy is therefore not a true metric, it satisfies many important mathematical properties. For example, it is a convex function of
, so relative entropy is therefore not a true metric, it satisfies many important mathematical properties. For example, it is a convex function of 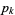 , is always nonnegative, and equals zero only if
, is always nonnegative, and equals zero only if 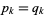 .
.
,
lstm中的门:link http://blog.csdn.net/malefactor/article/details/51183989
参考:http://www.jianshu.com/p/9dc9f41f0b29

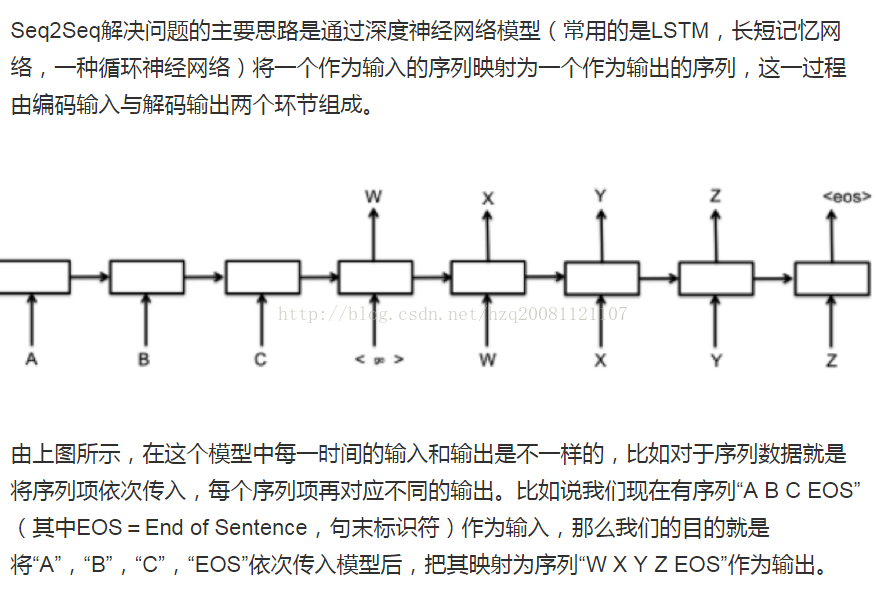
seq2seq
refer:http://www.jianshu.com/p/124b777e0c55














 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









