







牛顿法与梯度下降法
martin
牛顿法与梯度下降算法的适用范围
- 这两种算法都只能找到局部最小值,也就是说容易陷入局部最优。
- 两种算法都必须给出一个初始点。
- 牛顿法使用二阶逼近,梯度下降法使用一阶逼近。
- 牛顿法对局部凸的函数能找到极小值,对局部凹的函数能找到极大值,对局部不凸不凹的可能找到鞍点。
- 梯度下降法一般不会找到最大值,但同样可能会找到鞍点。
- 当初始点选取合理的情况下,牛顿法比梯度下降法收敛的速度快。
- 牛顿法要估计二阶导数,计算难度相对要大。
牛顿法
一元函数二阶逼近
首先在初始点
x0
处写出二阶泰勒级数:
f(x0+Δx)=f(x0)+f′(x0)Δx+f′′(x0)2Δx2+o(Δx2)=g(Δx)+o(Δx2)
我们知道关于 Δx 的二次函数 g(Δx) 的极值点为 −f′(x0)f′′(x0) ,(可以类比二次函数, y=ax2+bx+c ,它的极值点坐标为 −b2a ),那么本着逼近的精神 f(x) 的极值点估计在 x0−−f′(x0)f′′(x0) 附近,于是定义 x1=x0−−f′(x0)f′′(x0) ,并重复此步骤得到此序列:
xn+1=xn−f′(xn)f′′(xn)
多元函数二阶逼近
如果函数
f(x)
是一个多元函数,
x
是一个向量,那么牛顿法序列变为:
思路与技巧完全相同,只是使用梯度 ∇f(xn) 取代一阶导数 f′(xn) ,使用Hessian矩阵 Hf(xn) 代替二阶导数 f′′(xn) 。
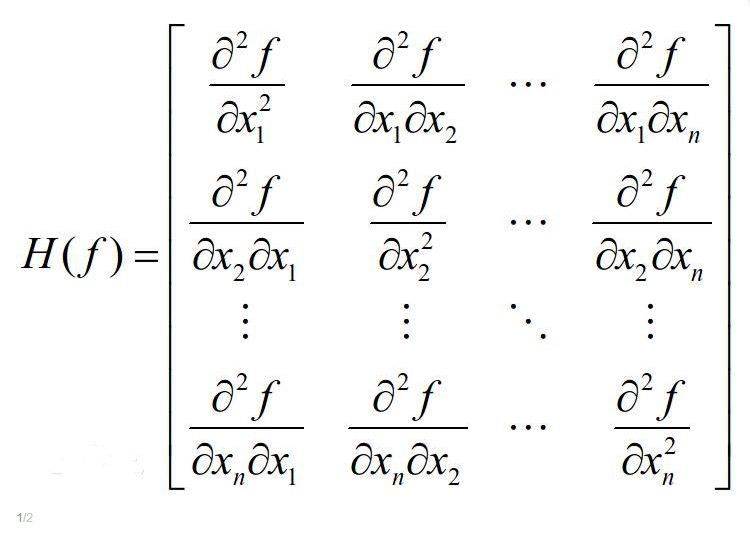
梯度下降法
参考我之前写的文章:http://blog.csdn.net/ice_martin/article/details/60972131














 8093
8093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









