







Redis入门
- NoSQL概述
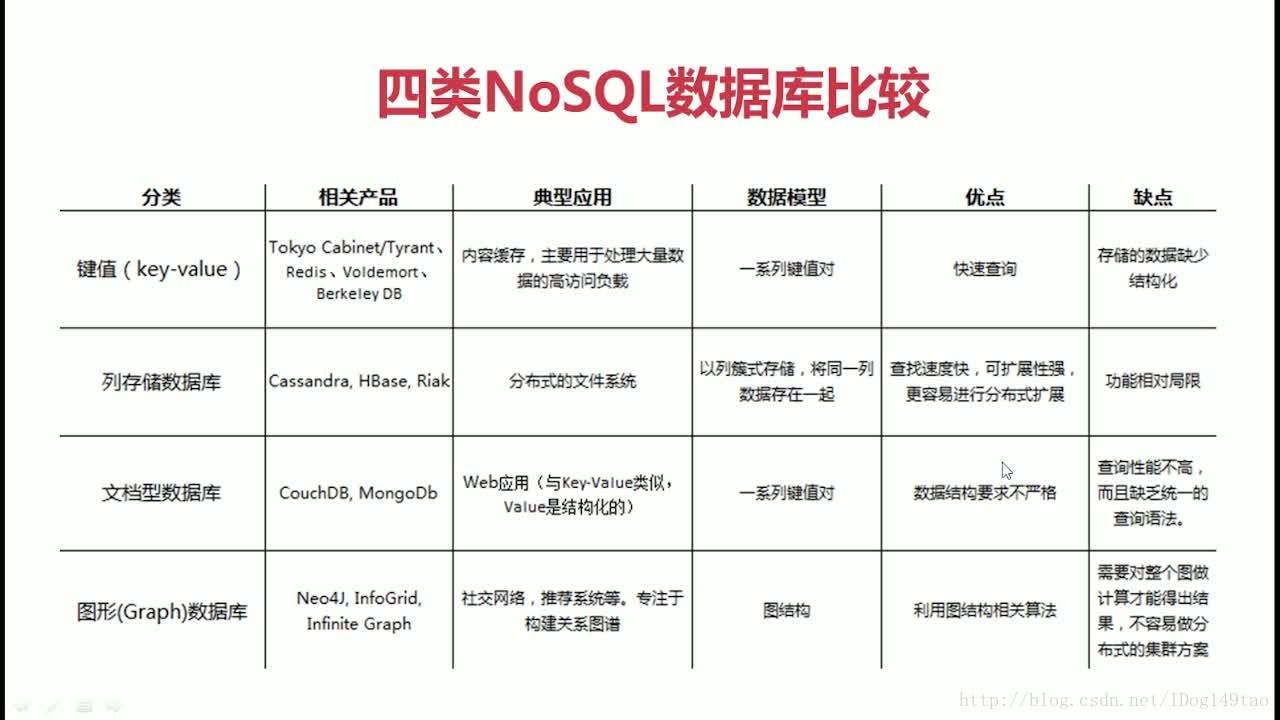
(一)NoSQL概述
NoSQL=Not Only SQL
非关系型数据库
NoSQL主要是为了解决高并发读写操作(High Performance)、海量数据的高效率存储和访问(Huge Storage)、高可扩展性和高可用性(High Scalability & High Availability)
- NoSQL数据库的四大分类
- 键值(Key-Value)存储
- 列存储
- 文档数据库
- 图形数据库

(二)Redis概述
高性能键值对数据库,支持的键值数据类型:字符串类型、散列类型、列表类型、集合类型、有序集合类型。
Redis的应用场景:
缓存(数据查询、新闻或商品内容、聊天室在线好友列表)、任务队列、网站访问统计、数据过期处理、应用排行榜、分布式集群架构中的session分离
(三)Redis的安装
- 搭建环境
- 虚拟机:VMware 10.0.2
- Linux系统:CentOS-6.5
- SSH客户端:SecureCRT 7.3, SecureFX 7.3
(四)Jedis入门(重点)
Jedis是Redis官方首选的Java客户端开发包
http://github.com/xetorthio/jedis
2种方式进行连接:(1)单实例;(2)连接池。
单实例步骤:(1)设置IP地址和端口。Jedis jedis=new Jedis(“192.168.32.130”,6379);(2)保存数据。jedis.set(“name”,”imooc”);(3)获取数据。String value=jedis.get(“name”); System.out.println(value);(4)关闭连接。jedis.close();
连接池步骤:(1)获得连接池的配置对象。JedisPoolConfig config=new JedisPoolConfig();(2)设置最大连接数、设置最大空闲连接数。config.setMaxTotal(100);config.setMaxIdle(10);(3)获得连接池。JedisPool jedisPool=new JedisPool(config,”192.168.32.130”,6379);(4)获得核心对象。Jedis jedis=null;(5)try…catch…操作。try{jedis=jedisPool.getResourse();jedis.set(“name”,”imooc”);…}
(五)Redis的数据结构
5种数据类型:字符串(String)、哈希(hash)、字符串列表(list)、字符串集合(set)、有序字符串集合(sorted set)
存储String:
二进制安全的,存入和获取的数据相同;Value最多可以容纳的数据长度是512M。
set(查询)/get(获取)/getset(先获取后更改)/incr(自增1)/decr(自减1)/incrby(自增)
/decrby(自减)/append(串接)
存储Hash
String Key 和String Value的map容器
每一个Hash可以存储4294967295个键值对(2^32?)(了解即可)
- 常用命令:
- hdel(用于删除某张表的特定属性,例:hdel myhash username)
- del(直接删除某张表,例:del myhash)
- hgetall
- hmset(设置同一张表格中的多个属性)
- hget
- hincrby
- hexists
- hlen
- hkeys
- hvals
- 存储list常用命令:
- 两端添加(rpush,右端添加;lpush,左端添加;lpushx )
- 两端弹出(lpop,rpop)
- 扩展命令 (linsert)
- 查看列表(lrange,负数表示从尾端查看)
- 获取列表元素个数(llen)
- rpoplpush,把一张表的末尾元素弹出,并放到另一张表的头部
- 存储Set常用命令:
- 增加:sadd;删除:srem;查看元素:smembers;元素是否存在:sismember;成员数量:scard;随机返回set中的成员:srandmember
- 差集运算:sdiff
- 交集运算:sinter
- 并集运算:sunion
- 差集存放到SetC中:sdiffstore SetC SetA SetB
- 存储Sorted-Set常用命令:
- 增加元素和相应的分数:zadd key score1 value1 score2 value2;删除:zrem;查看元素:zcard;
- 范围查找:zrange key 0 -1;范围查找并显示分数:zrange key 0 -1 withscores;
- 按照排名倒序:zrevrange
- 按照排名范围删除:zremrangebyrank
- 按照分数范围删除:zremrangebyscore
- keys * —查看所有keys
- keys my? —查看my开头的keys
- del key1 —删除key
- exists key1 —key是否存在
- rename key1 key2 — 重命名
- expire key 1000 — 设置过期时间(/秒)
- ttl key — 所剩的超时时间(/秒)
- type key —key的类型
(七)Redis的事务及持久化
- **多数据库**
- select db1—选择数据库,标记从0开始,最大到15
- move key1 db1—把key1移动db1数据库
- **支持事务**
- multi—开始事务(相当于关系型数据库的start)
- exec—执行事务(相当于关系型数据库的commit)
- discard—回滚事务(相当于关系型数据库的rollback)
Redis持久化使用的方式有4种:(1)RDB持久化;(2)AOF持久化;(3)同时使用RDB和AOF;(4)无持久化
RDB
RDB方式的持久化是通过快照(SnapShot)完成的,当符合一定条件时redis会自动将内存中的所有数据执行快照操作并存储到硬盘上。默认存储在redis根目录的dump.rdb文件中。(文件名在配置文件中dbfilename)
- redis进行快照的时机(在配置文件redis.conf中)
- save 900 1—表示900秒内至少1个键被更改则进行持久化1次(快照)。
- save 300 10—表示300秒内至少10个键被更改则进行快照。
- save 60 10000—表示600秒内至少10000个键被更改则进行快照。
优势:(1)方便文件备份;(2)方便灾难恢复;(3)性能最大化。fork分叉的方式,子进程完成数据持久化操作。
劣势:(1)可用性差;(2)系统可能延迟。
AOF
AOF方式的持久化是通过日志文件的方式。默认情况下redis没有开启aof,可以通过参数appendonly参数开启。
AOF优势:(1)数据安全性高;(2)即使出现宕机现象,也不会丢失已有数据;(3)自动启动重写机制。(4)日志格式清晰,易于理解;
劣势:(1)数据容量大;(2)效率低。














 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









