






随着互联网技术和社会化网络的发展,每天有大量包括博客,图片,视频,微博等等的信息发布到网上。传统的搜索技术已经不能满足用户对信息发现的需求,原因有多种,可能是用户很难用合适的关键词来描述自己的需求,也可能用户需要更加符合他们兴趣和喜好的结果,又或是用户无法对自己未知而又可能感兴趣的信息做出描述。推荐引擎的出现,可以帮用户获取更丰富,更符合个人口味和更加有意义的信息。
个性化推荐根据用户兴趣和行为特点,向用户推荐所需的信息或商品,帮助用户在海量信息中快速发现真正所需的商品,提高用户黏性,促进信息点击和商品销售。推荐系统是基于海量数据挖掘分析的商业智能平台,推荐主要基于以下信息:
l热点信息或商品
l用户信息,如性别、年龄、职业、收入以及所在城市等等
l用户历史浏览或行为记录
l社会化关系
基于人口统计学的推荐机制(Demographic-based Recommendation)是一种最易于实现的推荐方法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
首先,系统对每个用户都有一个用户 Profile 的建模,其中包括用户的基本信息,例如用户的年龄,性别等等;然后,系统会根据用户的 Profile 计算用户的相似度,可以看到用户 A 的 Profile 和用户 C 一样,那么系统会认为用户 A 和 C 是相似用户,在推荐引擎中,可以称他们是“邻居”;最后,基于“邻居”用户群的喜好推荐给当前用户一些物品。
这种基于人口统计学的推荐机制的好处在于:
l因为不使用当前用户对物品的喜好历史数据,所以对于新用户来讲没有“冷启动(Cold Start)”的问题。
l这个方法不依赖于物品本身的数据,所以这个方法在不同物品的领域都可以使用,它是领域独立的(domain-independent)。
然后,这个方法的缺点和问题就在于,这种基于用户的基本信息对用户进行分类的方法过于粗糙,尤其是对品味要求较高的领域,比如图书,电影和音乐等领域,无法得到很好的推荐效果。另外一个局限是,这个方法可能涉及到一些与信息发现问题本身无关却比较敏感的信息,比如用户的年龄等,这些用户信息不是很好获取。
基于内容的推荐是在推荐引擎出现之初应用最为广泛的推荐机制,它的核心思想是根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。这种推荐系统多用于一些资讯类的应用上,针对文章本身抽取一些tag作为该文章的关键词,继而可以通过这些tag来评价两篇文章的相似度。
这种推荐系统的优点在于:
l易于实现,不需要用户数据因此不存在稀疏性和冷启动问题。
l基于物品本身特征推荐,因此不存在过度推荐热门的问题。
然而,缺点在于抽取的特征既要保证准确性又要具有一定的实际意义,否则很难保证推荐结果的相关性。豆瓣网采用人工维护tag的策略,依靠用户去维护内容的tag的准确性。
基于关联规则的推荐更常见于电子商务系统中,并且也被证明行之有效。其实际的意义为购买了一些物品的用户更倾向于购买另一些物品。基于关联规则的推荐系统的首要目标是挖掘出关联规则,也就是那些同时被很多用户购买的物品集合,这些集合内的物品可以相互进行推荐。目前关联规则挖掘算法主要从Apriori和FP-Growth两个算法发展演变而来。
基于关联规则的推荐系统一般转化率较高,因为当用户已经购买了频繁集合中的若干项目后,购买该频繁集合中其他项目的可能性更高。该机制的缺点在于:
l计算量较大,但是可以离线计算,因此影响不大。
l由于采用用户数据,不可避免的存在冷启动和稀疏性问题。
l存在热门项目容易被过度推荐的问题。
协同过滤是一种在推荐系统中广泛采用的推荐方法。这种算法基于一个“物以类聚,人以群分”的假设,喜欢相同物品的用户更有可能具有相同的兴趣。基于协同过滤的推荐系统一般应用于有用户评分的系统之中,通过分数去刻画用户对于物品的喜好。协同过滤被视为利用集体智慧的典范,不需要对项目进行特殊处理,而是通过用户建立物品与物品之间的联系。
目前,协同过滤推荐系统被分化为两种类型:基于用户(User-based)的推荐和基于物品(Item-based)的推荐。
基于用户的协同过滤推荐的基本原理是,根据所有用户对物品或者信息的偏好(评分),发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K-Nearest Neighboor”的算法;然后,基于这 K 个邻居的历史偏好信息,为当前用户进行推荐。
这种推荐系统的优点在于推荐物品之间在内容上可能完全不相关,因此可以发现用户的潜在兴趣,并且针对每个用户生成其个性化的推荐结果。缺点在于一般的Web系统中,用户的增长速度都远远大于物品的增长速度,因此其计算量的增长巨大,系统性能容易成为瓶颈。因此在业界中单纯的使用基于用户的协同过滤系统较少。
基于物品的协同过滤和基于用户的协同过滤相似,它使用所有用户对物品或者信息的偏好(评分),发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。基于物品的协同过滤可以看作是关联规则推荐的一种退化,但由于协同过滤更多考虑了用户的实际评分,并且只是计算相似度而非寻找频繁集,因此可以认为基于物品的协同过滤准确率较高并且覆盖率更高。
同基于用户的推荐相比,基于物品的推荐应用更为广泛,扩展性和算法性能更好。由于项目的增长速度一般较为平缓,因此性能变化不大。缺点就是无法提供个性化的推荐结果。
两种协同过滤,在基于用户和基于物品两个策略中应该如何选择呢?其实基于物品的协同过滤推荐机制是 Amazon 在基于用户的机制上改良的一种策略,因为在大部分的 Web 站点中,物品的个数是远远小于用户的数量的,而且物品的个数和相似度相对比较稳定;同时基于物品的机制比基于用户的实时性更好。但也不是所有的场景都是这样的情况,在一些新闻推荐系统中,也许物品,也就是新闻的个数可能大于用户的个数,而且新闻的更新程度也有很快,所以它的相似度依然不稳定。所以,推荐策略的选择其实也和具体的应用场景有很大的关系。
基于协同过滤的推荐机制是现今应用最为广泛的推荐机制,它有以下几个显著的优点:
l它不需要对物品或者用户进行严格的建模,而且不要求物品的描述是机器可理解的,所以这种方法也是领域无关的。
l这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好。
然后而它也存在以下几个问题:
l方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题。
l推荐的效果依赖于用户历史偏好数据的多少和准确性。
l在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等。
l对于一些特殊品味的用户不能给予很好的推荐。
l由于以历史数据为基础,抓取和建模用户的偏好后,很难修改或者根据用户的使用演变,从而导致这个方法不够灵活。
互联网上的主题广告推广(例如,百度推广,google adsense)的目标在于实现一个面向用户的个性化广告投放系统。通过把个性化推荐算法在广告投放中的应用,就实现了我们个性化广告投放的目标。那么,这种演变是如何实现的呢?
在互联网中,例如,百度,拥有大量的网页信息,而主题广告推广的对象不是用户而是某一类型的页面。通过类比,每种网页类型对应于推荐系统中的一个用户,而每一个广告就对应于推荐系统中的一个物品,网页类型(用户)对广告(物品)的评分则可以用该网页类型中投放广告时的点击情况来计算,这样就构成了一个user-item-rating的矩阵。也就是,通过协同过滤算法可以实现对不同类型的网页进行广告推荐。
此外,实际应用协同过滤算法来进行广告投放也存在一个些问题。例如,协同过滤中的“冷启动”问题,也就是新增广告条目的推荐需要额外考虑;同时,也需要考虑用户对广告的接受程度,广告库存率等问题。
4. 业界个性化推荐系统
4.1. Yahoo!Resarch - Web-ScaleRecommendation Systems 2011推荐系统论坛中,来自Yahoo!的Yehuda Koren分享了他对于互联网中推荐系统的经验。在》
中,简单介绍了目前广泛流行的协同过滤推荐机制;另外分析了一些推荐系统中值得注意的一些问题:
lBias Matters
在实际的应用中,用户并不是随机地选择物品去打分,而是只选择那些和他们兴趣相关的物品打分,绝大多数用户往往忽略了去给那些没有兴趣的物品打分。Koren通过分析Netflix Prize数据,Koren发现用户对视频的评分变化中,Bias可以解释其中的33%,而个性化只能解释其中的10%,剩下的57%暂时还得不到解释。
lEliciting user feedback
Koren的目标是解决推荐系统的cold-start问题,例如,Yahoo! Movie中,对于新用户,很难预测他们的喜好(对视频的评分)。那么,可以选一些视频让新用户打分,从而获取他们的兴趣数据。在此过程中,使用了决策树模型来引导用户评分,可以用尽量少的视频,最大程度地了解用户兴趣。
lEstimating confidence in recommendations
在推荐系统中,我们需要对被推荐物品的可信度进行估计,从而得出更为可信的物品来进行推荐。Koren在这里提出了基于概率的可信度计算方法,也就是根据对评分(用户对物品)的概率预测,然后利用熵,标准方差,或是Gini不纯度等概率分布来对物品可信度进行评估。
4.2. 淘宝推荐系统淘宝推荐系统的目标就是要为各个产品提供商品,店铺,人,类目属性各种维度的推荐。它的核心就是以类目属性和社会属性为纽带,将人,商品和店铺建立起联系。

淘宝的宝贝推荐原则:
l基于内容的和关联规则
l全网优质宝贝算分
l根据推荐属性筛选TOP
l基于推荐属性的关联关系
l采用搜索引擎存储和检索优质宝贝
l加入个性化用户信息
根据用户的购买和收藏记录产生可推荐的关联规则。对优质宝贝的算分需要考虑商品的相关属性,包括描述,评价,名称,违规,收藏人气,累计销量,UV,以及PV等等。此外,推荐系统根据用户的浏览,收藏,购买行为以及反馈信息,在Hadoop上来计算用户带权重的标签,用于进行个性化推荐。
那么,淘宝是如何利用个性化推荐的结果呢?下图展示了淘宝基于个性化推荐的5W营销系统:
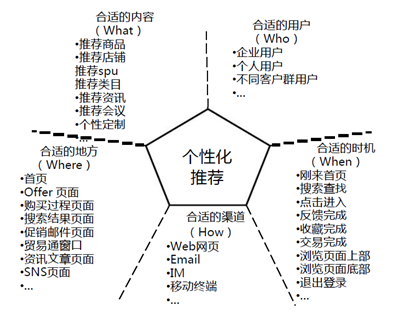
在个性化推荐之上,淘宝还实现了基于内容的广告投放。由于个性化推荐出来的物品是用户所感兴趣的,可以想象,基于此之上的广告投放也应该会行之有效。
众所周知,淘宝具有海量的数据和商品问题,这里列举了淘宝数据的一些参数:超过8亿种在线商品,100万产品,4万属性,等等。在淘宝实现推荐系统可能遇到的各种各样的难题,其中有:
l商品种类繁多,生命周期短,很难及时收集到足够多的点击或购买数据,这使得基于用户行为的推荐方法,比如基于物品的推荐方法,发挥空间有限。
l因为商品是由卖家而非网站登记的,数据的规范性差,这又给基于内容的推荐带来了很大的困难。
l8亿种商品中,重复的商品种类应该非常多,需要尽量避免推荐重复种类的商品给用户,但在数据规范性差、区分度差的情况下,如何归并重复商品种类,这本身也是个很大的难题。
l大多数推荐系统只需要考虑如何满足买家的需求,在淘宝,还要考虑卖家的需求。
4.3. 豆瓣的推荐引擎 - 豆瓣猜
豆瓣网在国内互联网行业美誉度很高,这是一家以帮助用户发现未知事物为己任的公司。它的“豆瓣猜”是一种个性化的推荐,其背后采用了基于用户的协同过滤技术。那么,豆瓣猜是如何向我们推荐产品的呢?
首先,确定什么样的产品适合推荐?豆瓣猜提出选择”具有媒体性的产品 (Media Product)“来进行推荐,即选择多样、口味很重要、单位成本不重要,同时能够广泛传播 (InformationCascade)的产品;接着在对真实的数据集进行定量分析后,进一步得出,应该是条目增长相对稳定、能够快速获得用户反馈,数据稀疏性与条目多样性、时效性比较平衡的产品,才是适合推荐的产品。
其次,豆瓣网的推荐引擎面对高成长性的挑战,通过降低存储空间,近似算法与分布式计算的设计,来实现对基于用户的协同过滤推荐系统的线性扩展。
最后,针对当前推荐系统面临的问题,包括倾向于给出平庸的推荐,有信息无结构,以及缺乏对用户的持续关注等黑盒推荐问题。豆瓣提出了分为 Prediction,Forecasting,Recommendation 三个阶段的下一代推荐系统,并探讨了一种下一代推荐引擎的构想——基于用户行为模型的、有记忆的、可进化的系统。
4.4. Hulu的个性化推荐Hulu是一家美国的视频网站,它是由美国国家广播环球公司(NBC Universal)和福克斯广播公司(Fox)在2007年3月共同投资建立的。在美国,Hulu已是最受欢迎的视频网站之一。它拥有超过250个渠道合作伙伴,超过600个顶级广告客户,3千万的用户,3亿的视频,以及11亿的视频广告。广告是衡量视频网站成功与否的一个重要标准。事实证明,Hulu的广告效果非常好,若以每千人为单位对广告计费,Hulu的所得比电视台在黄金时段所得还高。那么,是什么让Hulu取得了这样的成功呢?
通过对视频和用户特点的分析,Hulu根据用户的个人信息,行为模型和反馈,设计出一个混合的个性化推荐系统。它包含了基于物品的协同过滤机制,基于内容的推荐,基于人口统计的推荐,从用户行为中提炼出来的主题模型,以及根据用户反馈信息对推荐系统的优化,等等。此个性化推荐系统也进而成为了一个产品,用于给用户推荐视频。这个产品通过问答的形式,与用户进行交互,获取用户的个人喜欢,进一步提高推荐的个性化。
Hulu把这种个性化推荐视频的思想放到了广告投放中,设计出了一套个性化广告推荐系统。那么,这种广告系统是如何实现个性化的呢?
lHulu的用户对广告拥有一定控制权,在某些视频中你可以根据自己的喜好选择相应的广告,或者选择在开头看一段电影预告片来抵消广告。
lHulu收集用户对广告的反馈意见(评分),例如,某个广告是否对收看用户有用?
l根据人口统计的信息,来投放广告。例如,分析Hulu用户的年龄,性别特征来同方不同的视频及广告。
l根据用户的行为模式,进一步增加广告投放的准确性。














 2146
2146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









