










注意:
本文中的所有代码你可以在这里
https://github.com/qeesung/algorithm/tree/master/chapter11/11-2/hashTable(这里会及时更新)
或者这里
http://download.csdn.net/detail/ii1245712564/8804203
找到
散列表之链接法
在之前的文章《散列表之直接寻址表》中介绍了散列表中一种最基本的类型,直接寻址表。直接寻址表是通过键值直接来寻找在在数组里面的映射位置,但是直接寻址表存在一个缺陷,在键值范围较大且元素个数不多的时候,空间利用率不高,比如现在我们只需要映射两个元素 (key:1,data1) 和 (key:10000,data2) ,此时我们需要分配一个大小为 10001 的数组,将第一个元素放到数组的 1 位置,第二个元素放到数组的最后一个位置,剩下的所有数组位置都没有被用到,造成空间的浪费。
于是,针对上面的情况,我们想到了下面的解决方案
通过散列函数 hash ,来将 key 映射到合适的位置上,即通过 hash(key) 来找到在数组上的位置,最后我们只需要一个大小为2的数组就可以了。
散列表的定义
在直接寻址的方式下,具有关键字
k
的元素被放到数组位置hash(hash function)传入键值
k
来计算元素在数组中合适的位置。
假设我们有一集合
这里的散列表大小
m
一般要比集合的大小
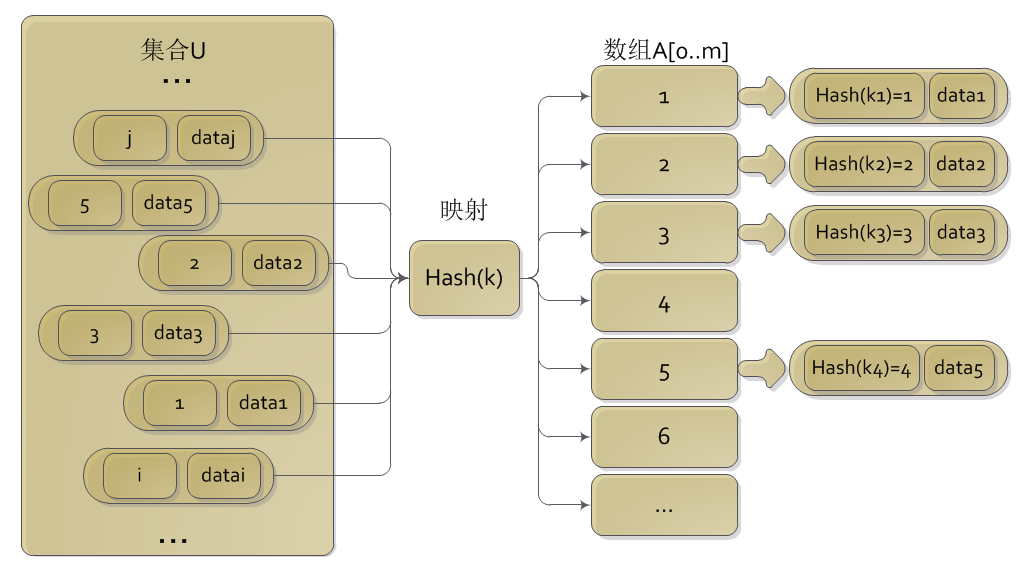
散列表的基本操作
散列表的基本操作有:
- INSERT:插入一个元素
- DELETE:删除一个元素
- SEARCH:搜索一个元素
在我们进行编码实现之前,先来考虑一下下面几个问题
问题1:散列函数
hash 该怎么设计?
回答1:散列函数的设计关乎到整个散列表的运行效率,所以不可等闲待之,需要针对输入的元素集合来设计合适的散列函数,这也是散列表中最大的难点,比如在之前的例子中,我们设计的散列函数很简单,如果输入的key是1,就返回0,如果输入的key是1000,那么就返回1.如果把这个集合运用到其他集合上,那么就是一个很差劲的散列函数
问题2:因为集合 U 的大小
|U| 远大于散列表的大小 m ,所以经常会发生不同键值却有相同散列值的情况,于是散列表的同一个位置就会发生冲突,这时应该怎么办?
回答2:我们可以采用链表的形式,将散列值相同的元素放入同一链表里面,再将列表挂在散列表的对应位置上。

散列表的编码实现
下面是用到的文件,我们只列出部分的文件的内容,你可以在这里获得全部内容:
https://github.com/qeesung/algorithm/tree/master/chapter11/11-2/hashTable
.
├── hash_table.cc 散列表源文件
├── hash_table.h 散列表头文件
├── hash_table_test.cc 散列表测试源文件
├── hash_table_test.h 散列表测试头文件
├── link_list.cc 链式链表源文件
├── link_list.h 链式链表头文件
├── list.h 链表接口文件
├── main.cc 主测试文件
├── Makefile
└── README.md
0 directories, 10 files散列表的设计
hash_table.h
#ifndef HASHTABLE_INC
#define HASHTABLE_INC
#include "link_list.h"
#include <vector>
/**
* Class: LinkHashTable
* Description: 链接法散列表
*/
template < class T >
class LinkHashTable
{
public:
/** ==================== LIFECYCLE ======================================= */
LinkHashTable (int table_size=0 , int(*_HASH)(const T &)=0); /** constructor */
/** ==================== MUTATORS ======================================= */
bool hash_insert(const T &); /*插入操作*/
bool hash_delete(const T &); /*删除操作*/
std::vector<T> hash_search(int) const; /*查找操作*/
void clear();
void printToVec(std::vector<std::vector<T> > & );
private:
/** ==================== DATA MEMBERS ======================================= */
int (*HASH)(const T &);// 定义一个散列函数指针
LinkList<T> * array; //链表的数组
const size_t table_size;// 散列表的大小
}; /** ---------- end of template class LinkHashTable ---------- */
#include "hash_table.cc"
#endif /* ----- #ifndef HASHTABLE_INC ----- */散列表的成员中有一个散列函数的指针
HASH,用户在构造散列表的时候需要制定对应的散列函数,还有一个array指针,是用来指向散列表的起始地址的。
hash_table.cc
#include "link_list.h"
/**
* Class: LinkHashTable
* Method: LinkHashTable
* Description:
*/
template < class T >
LinkHashTable < T >::LinkHashTable (int _table_size , int(*_HASH)(const T &)) :\
table_size(_table_size),HASH(_HASH)
{
array = new LinkList<T>[table_size]();
} /** ---------- end of constructor of template class LinkHashTable ---------- */
template < class T >
bool LinkHashTable<T>::hash_insert (const T & ele)
{
int index = HASH(ele);
if(index >= table_size || index <0)
return false;
return array[index].insert(ele);
} /** ----- end of method LinkHashTable<T>::hash_insert ----- */
template < class T >
bool LinkHashTable<T>::hash_delete (const T & ele)
{
int index = HASH(ele);
if(index >= table_size || index <0)
return false;
return array[index].remove(ele);
} /** ----- end of method LinkHashTable<T>::hash_delete ----- */
template < class T >
std::vector<T> LinkHashTable<T>::hash_search (int k) const
{
if(k < 0 || k >= table_size)
return std::vector<T>();
std::vector<int> vec;
array[k].printToVec(vec);
return vec;
} /** ----- end of method LinkHashTable<T>::hash_search ----- */
template < class T >
void LinkHashTable<T>::clear ()
{
for(int i =0 ; i < table_size ; ++i)
{
array[i].clear();
}
return ;
} /** ----- end of method LinkHashTable<T>::clear ----- */
template < class T >
void LinkHashTable<T>::printToVec (std::vector<std::vector<T> > & vec)
{
for(int i =0 ; i < table_size ; ++i)
{
std::vector<int> tempVec;
array[i].printToVec(tempVec);
vec.push_back(tempVec);
}
return ;
} /** ----- end of method LinkHashTable<T>::printToVec ----- */主测试文件
main.cc
#include <stdlib.h>
#include "hash_table_test.h"
#include <cppunit/ui/text/TestRunner.h>
#include <cppunit/TestCaller.h>
#include <cppunit/TestSuite.h>
/**
* +++ FUNCTION +++
* Name: main
* Description: 测试的主函数
*/
int main ( int argc, char *argv[] )
{
CppUnit::TextUi::TestRunner runner;
CppUnit::TestSuite * suite = new CppUnit::TestSuite();
suite->addTest(new CppUnit::TestCaller<HashTableTest>("Test insert by qeesung", &HashTableTest::test_insert));
suite->addTest(new CppUnit::TestCaller<HashTableTest>("Test delete by qeesung", &HashTableTest::test_delete));
suite->addTest(new CppUnit::TestCaller<HashTableTest>("Test search by qeesung", &HashTableTest::test_search));
runner.addTest(suite);
runner.run("",true);
return EXIT_SUCCESS;
return EXIT_SUCCESS;
} /** ---------- end of function main ---------- */编译运行
编译方法
- 如果你安装了
cppunit
make- 如果没有安装
cppunit,你需要这样编译
g++ hash_table_test.cc youSourceFile.cc -o target运行方法
./hashTest(or your target)结论
散列表最重要的是设计一个性能良好的散列函数(hash function),这也是散列表的难点,如果散列函数设计差劲的话,有可能造成数据分布的不平衡,删除和查找操作性能变差。我们考虑最差劲的散列函数,就是将所有的键值都映射为同一个散列值,那么对散列表的查找和删除操作的运行时间将和操作一个链式链表一样,都为














 1139
1139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









