






简述
sell = a*x + b*y + c*z + d*zz + e上面我们的sell是一个具体的实数值,然而很多情况下,我们需要回归产生一个类似概率值的0~1之间的数值(比如某一双鞋子今天能否卖出去?或者某一个广告能否被用户点击? 我们希望得到这个数值来帮助决策鞋子上不上架,以及广告展不展示)。这个数值必须是0~1之间,但sell显然不满足这个区间要求。于是引入了Logistic方程,来做归一化。这里再次说明,该数值并不是数学中定义的概率值。那么既然得到的并不是概率值,为什么我们还要费这个劲把数值归一化为0~1之间呢?归一化的好处在于数值具备可比性和收敛的边界,这样当你在其上继续运算时(比如你不仅仅是关心鞋子的销量,而是要对鞋子卖出的可能、当地治安情况、当地运输成本 等多个要素之间加权求和,用综合的加和结果决策是否在此地开鞋店时),归一化能够保证此次得到的结果不会因为边界 太大/太小 导致 覆盖其他feature 或 被其他feature覆盖。(举个极端的例子,如果鞋子销量最低为100,但最好时能卖无限多个,而当地治安状况是用0~1之间的数值表述的,如果两者直接求和治安状况就完全被忽略了)这是用logistic回归而非直接线性回归的主要原因。到了这里,也许你已经开始意识到,没错,Logistic Regression 就是一个被logistic方程归一化后的线性回归,仅此而已。
至于所以用logistic而不用其它,是因为这种归一化的方法往往比较合理(人家都说自己叫logistic了嘛),能够打压过大和过小的结果(往往是噪音),以保证主流的结果不至于被忽视。其中f(X)就是我们上面例子中的sell的实数值了,而y就是得到的0~1之间的可能性数值了。
数学公式
逻辑回归一般是用来预测二元分类的,它的线性方法可以用公式(1)进行描述,它的损失函数用公式(2)进行描术:
f(w):=λR(w)+1n∑i=1nL(w;xi,yi) (1)
这里,xi∈Rd 代表训练数据, 1≤i≤n , yi∈R对应的是labels.
目标函数f有两部分:正则化和损失函数,前者的作用是为了去躁,后者是用来评估训练数据模型的误差。在w中损失函数L(w;.)是一个典型的凸函数。固定的正则化参数λ≥0(代码中用regParam 表示),用来权衡两目标间的最小损失。
下面是sparkmllib当中的损失函数和它对应的梯度下降方法数学表达式:

接下来的正则化函数公式:
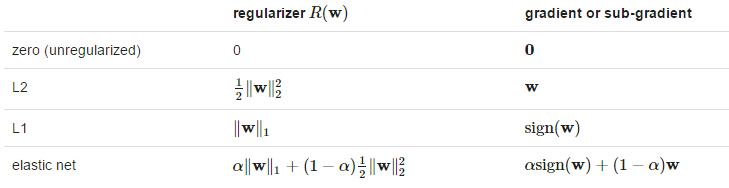
sign(w) 是由 (±1)组成的向量。
L(w;x,y):=log(1+exp(−ywTx)) (2)对于二元分类问题,训练输出一个预测模型,给定一组向量X,能过通过公式(3)进行预测。
f(z)=1/(1+e−z) (3)其中 z=wTx,(数学公式不好弄,T代表转置),默认情况下,f(wTx)>0.5代表正面,其他就是反面。
在sparkmllib当中,我们使用 mini-batch gradient descent 和 L-BFGS 来解决逻辑回归,推荐使用L-BFGS算法,因为它收敛更快。
sparkmllib实例:
import org.apache.spark.mllib.classification.{LogisticRegressionModel, LogisticRegressionWithLBFGS}
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
// Load training data in LIBSVM format.
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Split data into training (60%) and test (40%).
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
// Run training algorithm to build the model
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(10)
.run(training)
// Compute raw scores on the test set.
val predictionAndLabels = test.map { case LabeledPoint(label, features) =>
val prediction = model.predict(features)
(prediction, label)
}
// Get evaluation metrics.
val metrics = new MulticlassMetrics(predictionAndLabels)
val accuracy = metrics.accuracy
println(s"Accuracy = $accuracy")
// Save and load model
model.save(sc, "target/tmp/scalaLogisticRegressionWithLBFGSModel")
val sameModel = LogisticRegressionModel.load(sc,
"target/tmp/scalaLogisticRegressionWithLBFGSModel")线性回归与逻辑回归对比
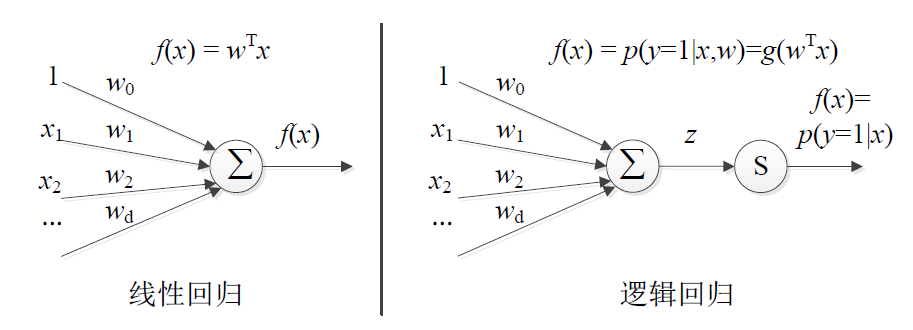
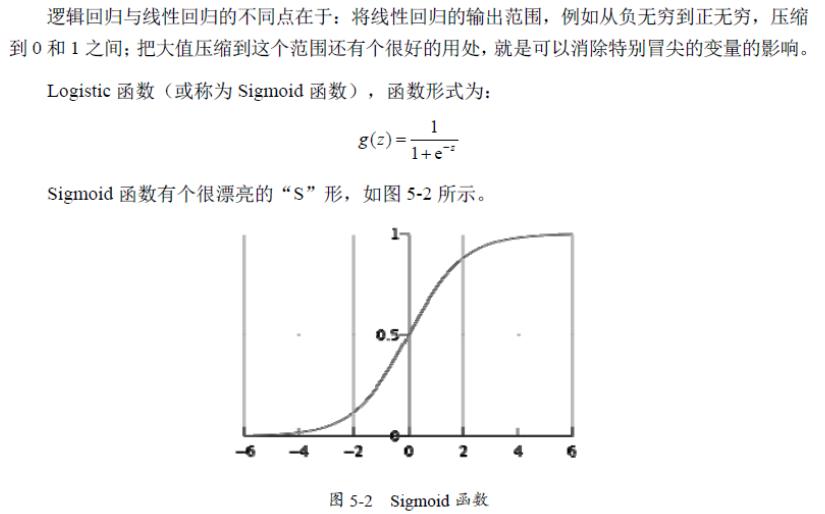




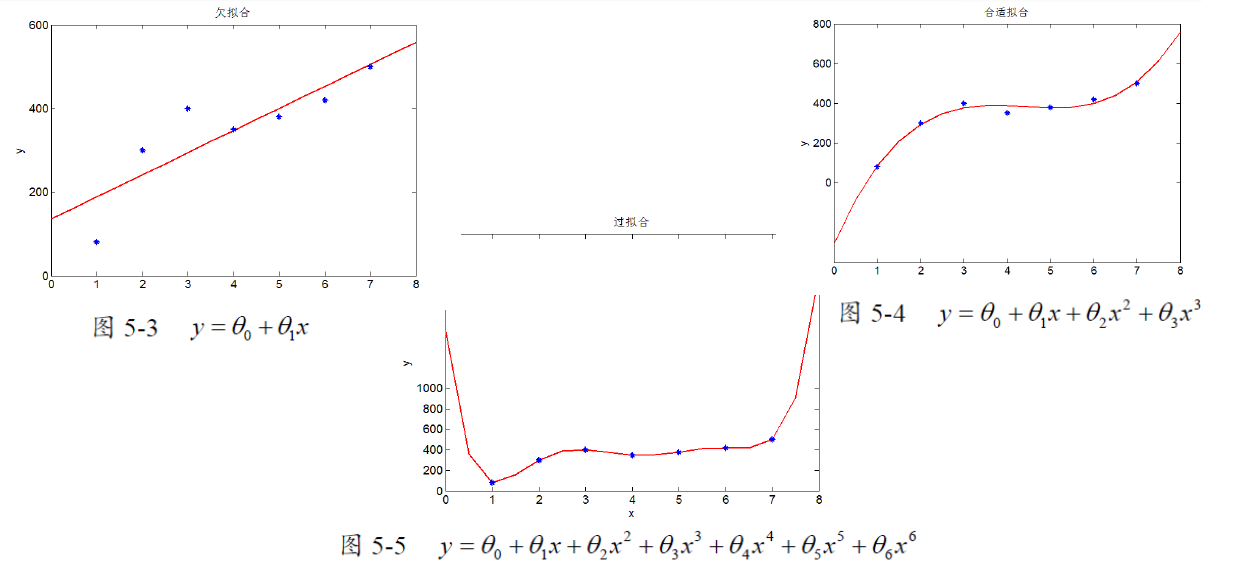


源码分析


LogisticRegressionWithSGD //LogisticRegressionWithSGD是基于随机梯度下降的逻辑回归的伴生对象
train //train是LogisticRegressionWithSGD对象的静态方法,该方法是根据设置逻辑回归参数新建逻辑回归类,并执行run方法进行训练
LogisticRegressionWithSGD //LogisticRegressionWithSGD类
run //run方法是继承于GeneralizedLinearAlgorithm类,该方法主要用optimizer.optimize方法进行权重的优化计算。
runMiniBatchSGD //GradientDescent类继承了optimizer,GradientDescent类的optimizer方法其实是调用了GradientDescent伴生对象的runMiniBatchSGD方法,runMiniBatchSGD方法是根据训练样本迭代运行随机梯度计算,得到最优权重;每次迭代主要计算样本的梯度及更新梯度。
gradient.compute //调用LogisticGradient.compute方法,该方法是计算样本的梯度值
updater.compute //调用SquaredL2Updater.compute方法,该方法是梯度的更新方法
LogisticRegressionModel //LogisticRegressionModel类
predict //继承GeneralizedLinearModel类predict方法,该方法计算样本的预测值与线性回归类似,LogisticRegressionWithSGD类:
class LogisticRegressionWithSGD private[mllib] (
private var stepSize: Double,
private var numIterations: Int,
private var regParam: Double,
private var miniBatchFraction: Double)
extends GeneralizedLinearAlgorithm[LogisticRegressionModel] with Serializable {
private val gradient = new LogisticGradient()
private val updater = new SquaredL2Updater()
@Since("0.8.0")
override val optimizer = new GradientDescent(gradient, updater)
.setStepSize(stepSize)
.setNumIterations(numIterations)
.setRegParam(regParam)
.setMiniBatchFraction(miniBatchFraction)class LogisticGradient(numClasses: Int) extends Gradient {
def this() = this(2)
override def compute(
data: Vector,
label: Double,
weights: Vector,
cumGradient: Vector): Double = {
val dataSize = data.size
// (weights.size / dataSize + 1) is number of classes
require(weights.size % dataSize == 0 && numClasses == weights.size / dataSize + 1)
numClasses match {
case 2 =>
/**
* For Binary Logistic Regression.
*二元逻辑回归梯度计算
*/
val margin = -1.0 * dot(data, weights)
val multiplier = (1.0 / (1.0 + math.exp(margin))) - label
axpy(multiplier, data, cumGradient)
if (label > 0) {
// The following is equivalent to log(1 + exp(margin)) but more numerically stable.
MLUtils.log1pExp(margin)
} else {
MLUtils.log1pExp(margin) - margin
}
case _ => //多元逻辑回归梯度计算
。。。。。使用正则L2进行更新梯度。
class SquaredL2Updater extends Updater {
override def compute(
weightsOld: Vector,
gradient: Vector,
stepSize: Double,
iter: Int,
regParam: Double): (Vector, Double) = {
// add up both updates from the gradient of the loss (= step) as well as
// the gradient of the regularizer (= regParam * weightsOld)
// w' = w - thisIterStepSize * (gradient + regParam * w)
// w' = (1 - thisIterStepSize * regParam) * w - thisIterStepSize * gradient
val thisIterStepSize = stepSize / math.sqrt(iter)
val brzWeights: BV[Double] = weightsOld.asBreeze.toDenseVector
brzWeights :*= (1.0 - thisIterStepSize * regParam)
brzAxpy(-thisIterStepSize, gradient.asBreeze, brzWeights)
val norm = brzNorm(brzWeights, 2.0) //计算L2范数
(Vectors.fromBreeze(brzWeights), 0.5 * regParam * norm * norm)
}
}梯度下降
def runMiniBatchSGD(
data: RDD[(Double, Vector)],
gradient: Gradient,
updater: Updater,
stepSize: Double,
numIterations: Int,
regParam: Double,
miniBatchFraction: Double,
initialWeights: Vector,
convergenceTol: Double): (Vector, Array[Double]) = {
。。。。。
var regVal = updater.compute(
weights, Vectors.zeros(weights.size), 0, 1, regParam)._2
var converged = false // indicates whether converged based on convergenceTol
var i = 1
while (!converged && i <= numIterations) {
val bcWeights = data.context.broadcast(weights)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + l, c._3 + 1)
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
val update = updater.compute(
weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble),
stepSize, i, regParam)
weights = update._1
regVal = update._2
previousWeights = currentWeights
currentWeights = Some(weights)
if (previousWeights != None && currentWeights != None) {
converged = isConverged(previousWeights.get,
currentWeights.get, convergenceTol)
}
} else {
logWarning(s"Iteration ($i/$numIterations). The size of sampled batch is zero")
}
i += 1
}
logInfo("GradientDescent.runMiniBatchSGD finished. Last 10 stochastic losses %s".format(
stochasticLossHistory.takeRight(10).mkString(", ")))
(weights, stochasticLossHistory.toArray)
。。。。。。。。
}预测:
def predict(testData: RDD[Vector]): RDD[Double] = {
// A small optimization to avoid serializing the entire model. Only the weightsMatrix
// and intercept is needed.
val localWeights = weights
val bcWeights = testData.context.broadcast(localWeights)
val localIntercept = intercept
testData.mapPartitions { iter =>
val w = bcWeights.value
iter.map(v => predictPoint(v, w, localIntercept))
}
} override protected def predictPoint(
dataMatrix: Vector,
weightMatrix: Vector,
intercept: Double) = {
require(dataMatrix.size == numFeatures)
// If dataMatrix and weightMatrix have the same dimension, it's binary logistic regression.
if (numClasses == 2) {
val margin = dot(weightMatrix, dataMatrix) + intercept
val score = 1.0 / (1.0 + math.exp(-margin))
threshold match {
case Some(t) => if (score > t) 1.0 else 0.0
case None => score
}
} else {
/**
* Compute and find the one with maximum margins. If the maxMargin is negative, then the
* prediction result will be the first class.
*
* PS, if you want to compute the probabilities for each outcome instead of the outcome
* with maximum probability, remember to subtract the maxMargin from margins if maxMargin
* is positive to prevent overflow.
*/
var bestClass = 0
var maxMargin = 0.0
val withBias = dataMatrix.size + 1 == dataWithBiasSize
(0 until numClasses - 1).foreach { i =>
var margin = 0.0
dataMatrix.foreachActive { (index, value) =>
if (value != 0.0) margin += value * weightsArray((i * dataWithBiasSize) + index)
}
// Intercept is required to be added into margin.
if (withBias) {
margin += weightsArray((i * dataWithBiasSize) + dataMatrix.size)
}
if (margin > maxMargin) {
maxMargin = margin
bestClass = i + 1
}
}
bestClass.toDouble
}
}实例:
test("logistic regression with SGD") {
val nPoints = 10000
val A = 2.0
val B = -1.5
val testData = LogisticRegressionSuite.generateLogisticInput(A, B, nPoints, 42)
val testRDD = sc.parallelize(testData, 2)
testRDD.cache()
val lr = new LogisticRegressionWithSGD().setIntercept(true)
lr.optimizer
.setStepSize(10.0)
.setRegParam(0.0)
.setNumIterations(20)
.setConvergenceTol(0.0005)
val model = lr.run(testRDD)
// Test the weights
assert(model.weights(0) ~== B relTol 0.02)
assert(model.intercept ~== A relTol 0.02)
val validationData = LogisticRegressionSuite.generateLogisticInput(A, B, nPoints, 17)
val validationRDD = sc.parallelize(validationData, 2)
// Test prediction on RDD.
validatePrediction(model.predict(validationRDD.map(_.features)).collect(), validationData)
// Test prediction on Array.
validatePrediction(validationData.map(row => model.predict(row.features)), validationData)
}














 3837
3837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









