






介绍
k-means算法原理比较简单,与上之前提到的C4.5算法不同,C4.5属性分类算法(有监督的),而k-means算法属于聚类算法(无监督的),两者有着本质的区别。
具体的算法描述如下:
1、随机选取 k个聚类质心点
2、重复下面过程直到收敛 {
对于每一个样例 i,计算其应该属于的类: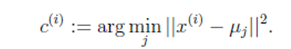
对于每一个类 j,重新计算该类的质心: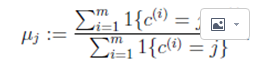
比较好理解。
k-means算法有个缺点就是对k的取值依赖很大,另外对k个初始质心的选择比较敏感,容易陷入局部最小值。
针对这上述这些缺点,有人提出了二分k-means算法。
它的思想是这样的:先将所有点作为一个簇,然后将该簇一分为二。之后选择能最大程度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。以此进行下去,直到簇的数目等于用户给定的数目k为止。
上述思想潜藏着一个这样的原则:因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点月接近于它们的质心,聚类效果就越好。所以我们就需要对误差平方和最大的簇进行再一次的划分,因为误差平方和越大,表示该簇聚类越不好,越有可能是多个簇被当成一个簇了,所以我们首先需要对这个簇进行划分。
它的伪代码如下:
将所有数据点看成一个簇
当簇数目小于k时
对每一个簇
计算总误差
在给定的簇上面进行k-均值聚类(k=2)
计算将该簇一分为二后的总误差
选择使得误差最大的那个簇进行划分操作初始化聚类中心点
k-means++算法选择初始中心点的基本思想就是:初始的聚类中心之间的相互距离要尽可能远。初始化过程如下。
1)从输入的数据点集合中随机选择一个点作为第一个聚类中心;
2)对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x);
3)选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大;
4)重复2)和3),直到k 个聚类中心被选出来;
5)利用这k 个初始的聚类中心来运行标准的KMeans 算法。
从上面的算法描述可以看到,算法的关键是第3 步,如何将D(x)反映到点被选择的概率上。一种算法如下。
1)随机从点集D 中选择一个点作为初始的中心点。
2)计算每一个点到最近中心点的距离Si ,对所有Si 求和得到sum。
3)然后再取一个随机值,用权重的方式计算下一个“种子点”。取随机值random
(0<random<sum),对点集D 循环,做random - = Si 运算,直到random < 0,那么点i 就是下一个中心点。
4)重复2)和3),直到k 个聚类中心被选出来。
5)利用这k 个初始的聚类中心来运行标准的KMeans 算法。源码分析
MLlib 实现KMeans 聚类算法:首先随机生成聚类中心点,支持随机选择样本点当作初始中心点,还支持k-means++方法选择最优的聚类中心点。然后迭代计算样本的中心点,迭代计算中心点的分布式实现是:首先计算每个样本属于哪个中心点,之后采用聚合函数统计属于每个中心点的样本值之和以及样本数量,最后求得最新中心点,并且判断中心点是否发生改变。
MLlib 的KMeans 聚类模型的runs 参数可以设置并行计算聚类中心的数量,runs 代表同时计算多组聚类中心点,最后取计算结果最好的那一组中心点作为聚类中心点。
train //train是KMeans对象的静态方法,该方法是根据设置Kmeans聚类参数,新建Kmeans聚类,并执行run方法进行训练
run //run是KMeans类方法,该方法主要用runAlgorithm方法进行聚类中心点的计算。
runAlgorithm //聚类中心点计算
initRandom //初始化中心点方法支持支持随机选择中心点和k-means++方法生成中心点
iteration //迭代计算样本属于哪个计算中心点,并更新最新中心点
predict //def train(
data: RDD[Vector],
k: Int,
maxIterations: Int,
initializationMode: String,
seed: Long): KMeansModel = {
new KMeans().setK(k)
.setMaxIterations(maxIterations)
.setInitializationMode(initializationMode)
.setSeed(seed)
.run(data)
}class KMeans private (
private var k: Int,
private var maxIterations: Int,
private var initializationMode: String,
private var initializationSteps: Int,
private var epsilon: Double, //域值
private var seed: Long) extends Serializable with Logging {
private[spark] def run(
data: RDD[Vector],
instr: Option[Instrumentation[NewKMeans]]): KMeansModel = {
if (data.getStorageLevel == StorageLevel.NONE) {
logWarning("The input data is not directly cached, which may hurt performance if its"
+ " parent RDDs are also uncached.")
}
//计算L2范数并缓存.zippedData格式为(向量、向量的L2范数)
// Compute squared norms and cache them.
val norms = data.map(Vectors.norm(_, 2.0))
norms.persist()
val zippedData = data.zip(norms).map { case (v, norm) =>
new VectorWithNorm(v, norm)
}
val model = runAlgorithm(zippedData, instr)
norms.unpersist()
// Warn at the end of the run as well, for increased visibility.
if (data.getStorageLevel == StorageLevel.NONE) {
logWarning("The input data was not directly cached, which may hurt performance if its"
+ " parent RDDs are also uncached.")
}
model
}private def runAlgorithm(
data: RDD[VectorWithNorm],
instr: Option[Instrumentation[NewKMeans]]): KMeansModel = {
val sc = data.sparkContext
val initStartTime = System.nanoTime()
val centers = initialModel match {
case Some(kMeansCenters) =>
kMeansCenters.clusterCenters.map(new VectorWithNorm(_))
case None =>
if (initializationMode == KMeans.RANDOM) {
initRandom(data)
} else {
initKMeansParallel(data)
}
}
val initTimeInSeconds = (System.nanoTime() - initStartTime) / 1e9
logInfo(f"Initialization with $initializationMode took $initTimeInSeconds%.3f seconds.")
var converged = false
var cost = 0.0
var iteration = 0
val iterationStartTime = System.nanoTime()
instr.foreach(_.logNumFeatures(centers.head.vector.size))
// Execute iterations of Lloyd's algorithm until converged
while (iteration < maxIterations && !converged) {
val costAccum = sc.doubleAccumulator
val bcCenters = sc.broadcast(centers)
// Find the sum and count of points mapping to each center
val totalContribs = data.mapPartitions { points =>
val thisCenters = bcCenters.value
val dims = thisCenters.head.vector.size
val sums = Array.fill(thisCenters.length)(Vectors.zeros(dims))
val counts = Array.fill(thisCenters.length)(0L)
points.foreach { point =>
val (bestCenter, cost) = KMeans.findClosest(thisCenters, point)
costAccum.add(cost)
val sum = sums(bestCenter)
axpy(1.0, point.vector, sum)
counts(bestCenter) += 1
}
counts.indices.filter(counts(_) > 0).map(j => (j, (sums(j), counts(j)))).iterator
}.reduceByKey { case ((sum1, count1), (sum2, count2)) =>
axpy(1.0, sum2, sum1)
(sum1, count1 + count2)
}.collectAsMap()
bcCenters.destroy(blocking = false)
// Update the cluster centers and costs
converged = true
totalContribs.foreach { case (j, (sum, count)) =>
scal(1.0 / count, sum)
val newCenter = new VectorWithNorm(sum)
if (converged && KMeans.fastSquaredDistance(newCenter, centers(j)) > epsilon * epsilon) {
converged = false
}
centers(j) = newCenter
}
cost = costAccum.value
iteration += 1
}
val iterationTimeInSeconds = (System.nanoTime() - iterationStartTime) / 1e9
logInfo(f"Iterations took $iterationTimeInSeconds%.3f seconds.")
if (iteration == maxIterations) {
logInfo(s"KMeans reached the max number of iterations: $maxIterations.")
} else {
logInfo(s"KMeans converged in $iteration iterations.")
}
logInfo(s"The cost is $cost.")
new KMeansModel(centers.map(_.vector))
}private[mllib] def findClosest(
centers: TraversableOnce[VectorWithNorm],
point: VectorWithNorm): (Int, Double) = {
var bestDistance = Double.PositiveInfinity
var bestIndex = 0
var i = 0
centers.foreach { center =>
// Since `\|a - b\| \geq |\|a\| - \|b\||`, we can use this lower bound to avoid unnecessary
// distance computation.
var lowerBoundOfSqDist = center.norm - point.norm
lowerBoundOfSqDist = lowerBoundOfSqDist * lowerBoundOfSqDist
if (lowerBoundOfSqDist < bestDistance) {
val distance: Double = fastSquaredDistance(center, point)
if (distance < bestDistance) {
bestDistance = distance
bestIndex = i
}
}
i += 1
}
(bestIndex, bestDistance)
}实例
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import org.apache.spark.mllib.linalg.Vectors
// Load and parse the data
val data = sc.textFile("data/mllib/kmeans_data.txt")
val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
// Cluster the data into two classes using KMeans
val numClusters = 2
val numIterations = 20
val clusters = KMeans.train(parsedData, numClusters, numIterations)
// Evaluate clustering by computing Within Set Sum of Squared Errors
val WSSSE = clusters.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + WSSSE)
// Save and load model
clusters.save(sc, "target/org/apache/spark/KMeansExample/KMeansModel")
val sameModel = KMeansModel.load(sc, "target/org/apache/spark/KMeansExample/KMeansModel")













 90
90











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









