







平时没事干的时候,会看看优酷lol视频,每期节目开始,解说都会用一个软件,从评论该视频的观众中抽奖,看了之后,想自己试试,只有代码,没有界面
实现步骤:
1,给评论翻页时,发现网址没有变,可以知道是该页面通过ajax获取数据,直接爬是行不通的
2,用httpWatch分析,得到http://comments.youku.com/comments/~ajax/vpcommentContent.html?__ap={%22videoid%22:%22XNjk5Mzc2NzE2%22,%22sid%22:663062266,%22page%22:41,%22last_modify%22:1397742780,%22showid%22:0}&__ai=&__callback=displayComments,利用工具分析得到http://comments.youku.com/comments/~ajax/vpcommentContent.html?__ap={"videoid":"XNjk5Mzc2NzE2","sid":663062266,"page":41,"last_modify":1397742780,"showid":0}&__ai=&__callback=displayComments,
3.到这里,改变page,就能获取某一页评论
import time
import urllib
import re
import random
#获取网页源码
def getHtml(x,url):
#url='http://comments.youku.com/comments/~ajax/vpcommentContent.html?__ap={"videoid":"XNjk5Mzc2NzE2","sid":663062266,"page":%d,"last_modify":1397742780,"showid":0}&__ai=&__callback=displayComments' % x
html=urllib.urlopen(url).read()
print url
#print html
return html
#获取评论
def getComment(y,html):
#匹配评论
reg=re.compile(r'<p.*?>(.*?)<br')
results=re.findall(reg,html)
print len(results)
#去掉里面的链接
result=re.sub('<a.*?>','',results[y])
result=re.sub('<.*?>','',result)
'''
for result in results:
print re.sub("<a.*?a>",'',result)
print '------------------'
'''
print result
return result
if __name__=='__main__':
num=raw_input('输入总页数:')
start=time.clock()
x=random.randint(0,int(num))
#第几条
y=random.randint(0,30)
print '第%d页' % x
print '第%d条' % y
url='http://comments.youku.com/comments/~ajax/vpcommentContent.html?__ap={"videoid":"XNjk5Mzc2NzE2","sid":663062266,"page":%d,"last_modify":1397742780,"showid":0}&__ai=&__callback=displayComments' % x
html=getHtml(x,url)
comment=getComment(y,html)
print comment
print 'done %.2f seconds' % (time.clock()-start)
结果:
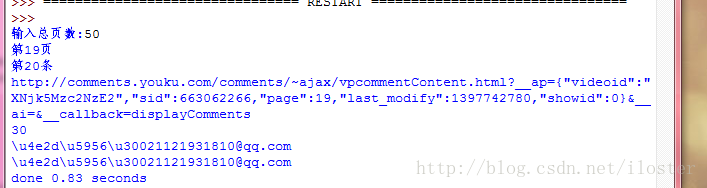
不管我怎么改变编码方式,都没有变化,不知道怎么让这中文输出















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









