







本篇在前一篇《Hadoop单机模式和伪分布式搭建教程》的基础上完成完全分布式的搭建,所以本篇的前提是已经按照之前的教程完成了伪分布式的安装。注意截图中的slaver应该是slave,哈哈,搭建的时候多打了r,没弄清slaver和slave的区别。
1. 说明
本教程中电脑为8G内存,故而将使用四个节点作为集群环境,其中一个为master,3个为slave(分别是slave1、slave2和slave3、master节点将仅为namenode存在,而slave节点是datanode),这样也算是比较标准的一个集群了。集群最后启动运行的时候8G内存不够了,崩溃了(原因可能是我设置虚拟机的内存是1.5G,可以考虑改成1G试试),所以建议大家学习弄个1个slave或者2个就可以了...视自己的情况而定....
2. 克隆虚拟机
右键虚拟机-->管理-->克隆,打开克隆向导,然后一路next,直至选择克隆类型为完整克隆:

输入虚拟机的名称为slave1,并且选择一个合适的虚拟机位置,点击完成即可。
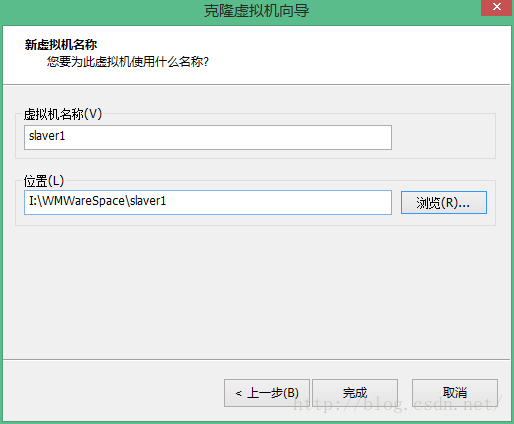
同理:再克隆一个slave2
结果图:
通过上面的步骤,每台虚拟机中都已经搭建了一个伪分布式的Hadoop,但是除了master外,其他的节点上的/usr/local/hadoop目录我们在后面会将其删除,然后将/usr/local/hadoop目录拷贝到每台slave节点上。如果是在实体机上面,那么需要给每个机器按照《Hadoop单机模式和伪分布式搭建教程CentOS》中1所做的准备工作做一遍。
Hadoop 集群的安装配置大致为如下流程:
1. 选定一台机器作为 Master
2. 在 Master 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
3. 在 Master 节点上安装 Hadoop,并完成配置
4. 在其他 Slave 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
5. 将 Master 节点上的 /usr/local/hadoop 目录复制到其他 Slave 节点上
6. 在 Master 节点上开启 Hadoop
3. 系统配置调整
因为我们是复制过来的虚拟机,需要对每个虚拟机的主机名以及Hosts文件进行编辑和修改,然后建立它们之间的互通。
1) 首先通过XShell建立与虚拟机之间的联系,通过远程来控制每台虚拟机。

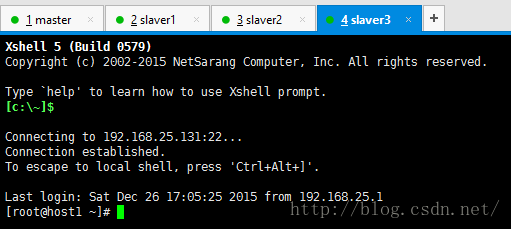
2) 然后分别修改它们的主机名和/etc/hosts文件,hosts文件是用来进行域名解析,这里我们只配置主机名和IP地址之间的映射。
对应上面的角色,分别将主机名修改为master,slave1,slave2,slave3。为了可以立刻生效同时永久修改主机名,我们需要执行以下两个步骤:
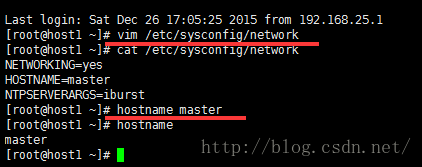
修改集群中每台机器的/etc/hosts,其中参数是ip地址和主机名,集群有几个Host就几个,我们只有四个节点,故4个,这个配置文件集群中每台机器都一样。
检查配置,步骤如下:
1、确认主机名
uname -n
2、确认IP地址
hostname --ip-address
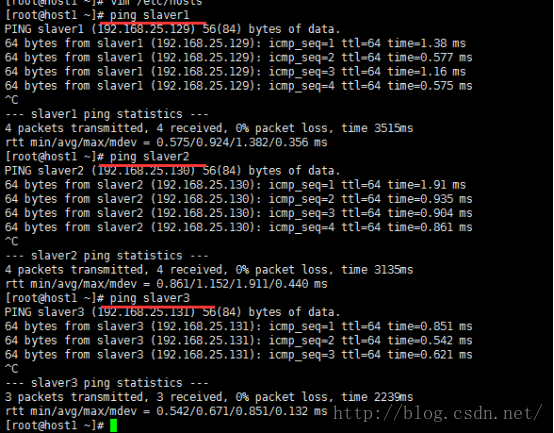
3、确保集群中的节点互相连通,
ping master
4. 建立集群之间的SSH 无密码登录
这一步呢,切换到Hadoop用户下,删除掉~/.ssh文件夹内的所有内容,然后重新生成dsa密钥。每台机器步骤如下:
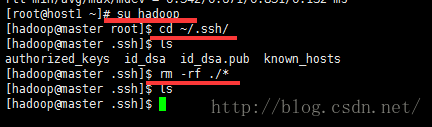
再在~/.ssh目录下执行下面的命令,完了之后通过ssh localhost检验一下:
当所有机器都重新配置好了之后,下面将建立它们之间的SSH无密码登录:
具体步骤(以master无密码登录slaver为例):
首先将master生成的公匙用scp命令传到所有的slaver上(以下命令是在master上执行)
然后再用hadoop登入slave1/2/3,将公匙加入到授权中,此时再从master上访问slvaer1/2/3即可无需密码了。(以下命令是在slave上执行)
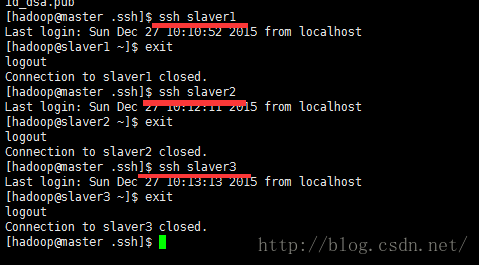
同理,
Ø 对于s1来说,必须可以ssh master,ssh slave2,ssh slave3
Ø 对于s2来说,必须可以ssh master,ssh slave1,ssh slave3
Ø 对于s3来说,必须可以ssh master,ssh slave1,ssh slave2
配置完了之后,检查确保集群中的所有节点都可以互相SSH无密码登录。
5. 配置集群/完全分布式环境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1. 文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
本教程让 Master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost ,加入三行内容,分别是slave1,slave2,slave3。

2. 修改core-site.xml文件
3. 修改hdfs-site.xml
4. 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
5. 修改yarn-site.xml
配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上(首先要将slave上的/usr/local/hadoop文件夹删除,分别在slave1/2/3上执行rm -rf /usr/local/hadoop)。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行:

首先在slave1上执行(需要root用户):
同理,slave2/3。
首次启动需要在Master节点执行NameNode格式化:

在启动集群之前需要关闭centos 的防火墙:

接着可以启动 hadoop 了,启动需要在 Master 节点上进行:

可以看到master上有namenode和secondaryNameNode的进程

Slave上有datanode的进程
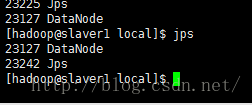
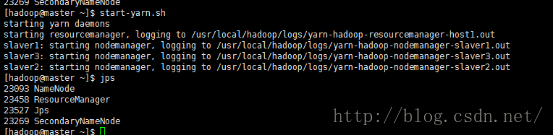
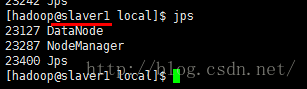
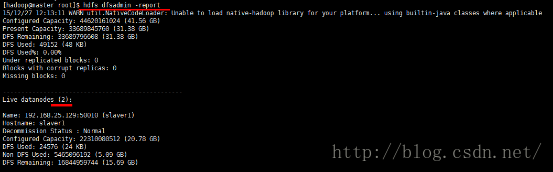
缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 3个 Datanodes:
很不幸......由于8G内存不够,VMWare崩溃了,截图也丢了,但是通过上面的可以看到,集群已经配置成功了,下面我重新设置一下,取消一个datanode,然后再次启动一下集群,hadoop就是有这种特性,那我只启动slave1和slave2来看看。可以看到虽然我配置了3个datanode,但是此时活动的只有2个datanode。
也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://192.168.25.128:50070/,IP是master的IP地址。如果不成功,可以通过启动日志排查原因。


执行以下命令将Hadoop的安装包发送到Hdfs上,查看HDFS的状态:

6. 执行分布式实例
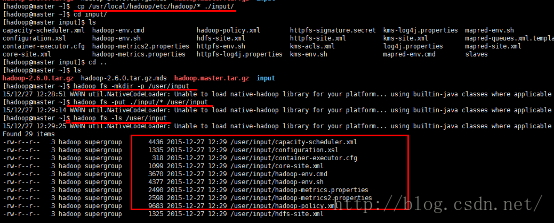
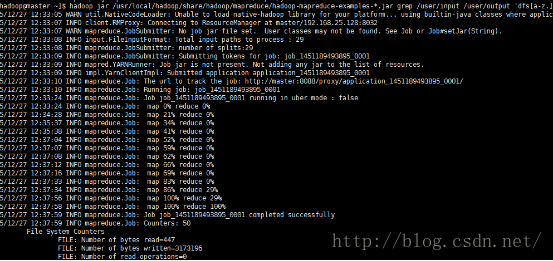
显示mapreduce job的进度

MR作业的输出结果
关闭 Hadoop 集群也是在 Master 节点上执行的:
此外,同伪分布式一样,也可以不启动 YARN,但要记得改掉 mapred-site.xml 的文件名。
OK,到这里一个完全分布式的Hadoop集群就搭建完成了!!!接下来你就可以在这个上面玩耍了,虚拟机上面需要注意自己的内存,学习一下完全分布式的搭建,根据自己的电脑配置,可以选择在实验的时候运行伪分布式还是完全分布式,伪分布式利于程序的调试,并且对资源消耗小。本教程只是是满足基本运行需求的配置,并没有对集群进任何优化,所以如果对优化比较有兴趣的童鞋,欢迎你们分享,我也想学学。















 2211
2211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









