







在上节课中已经可以对有限个hypothesis的假设集列出霍夫丁不等式如下:
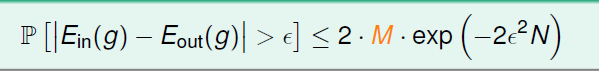
在进行机器学习的过程中,我们一方面要保证Ein与Eout是比较接近的,另一方面为了获取一个比较好的结果,也希望Ein能比较好。于是有了以下的一个基本trade-off:
当假设集大小M比较小的时候:能够很容易保证Ein与Eout比较接近,但是这个时候由于M比较小,不那么容易选取到一个Ein比较小的结果。
v.s.
当假设集大小M比较大的时候:由于备选假设多,所以能够较容易地选取到一个Ein比较小的结果,但是不容易保证Ein与Eout比较接近,需要更大的样本集大小N。
那么问题来了。在很多模型中,我们可以选择的hypothesis实际上有无数个。以PLA为例子,我们可以选择的直线有无数条。那么这个时候考虑到右边的M,是否就无法确保Ein与Eout的接近呢?
答案是否定的。由于在
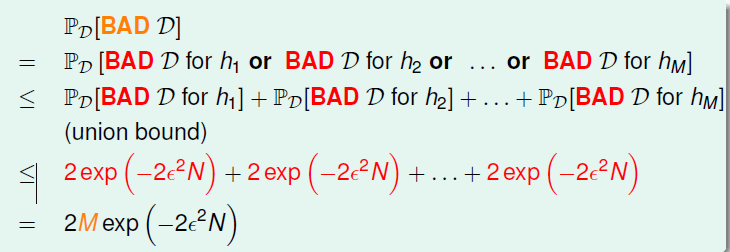
这一推导过程中,我们使用了union bound作为上界,假设各个hypothesis的bad data之间是相互独立的,这比实际上界要大很多。在实际应用中,各个hypothesis的bad data的交集是很大的。依然以PLA作为例子,两条斜率差0.01的直线,虽然是两个不同的hypothesis,但是它们的Eout(h)和Ein(h)实际上都是非常接近的,因此对一条直线来说是bad data的直线对另一条而言也有很大的可能新是bad data。在这个时候两者均为bad data的概率是小于union bound的。而考虑到这样的hypothesis还有很多,原式中的M在趋于无穷时可能可以使用另外的表达式进行代替。
接下来开始推导可能的M的替代表达式mH
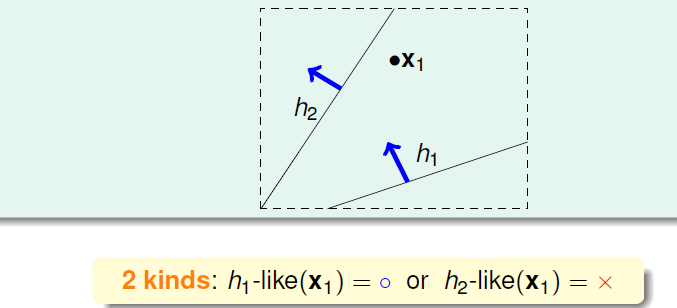
为了考虑将无穷的M以有限量代替,我们考虑对hypothesis按其结果进行分组。依然以PLA为例子。当数据集大小为1时,hypothesis仅可分成两类,如下:
当数据集大小为2时,hypothesis可以分成4类
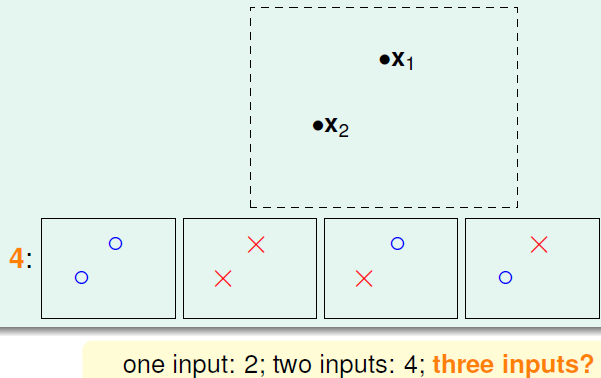
是否依此类推,接下来均可以分成2N类呢?当使用的假设集是直线的时候,答案是否定的:
因此,似乎与数据集大小相关的量2N可以作为我们替代无限的M的一个有限量
在这里,我们将一系列刚好将所有假设类型包含在内的假设集称为dichotomy,它是我们能够用于等效无限假设数量的假设集的最小假设集
虽然其大小上界为2N,但是由直线分割的例子,其上界可能比2N还小,因此定义某个假设集的growth function为’

其大小与假设集类型与数据集的大小有关
接下来是一些简单的growth function例子


再考虑到数据集至多只有2N可能的结果,显然对于growth function总有mH(N)<=2N
然而如以下式子所示,在实际应用中当mH(N)的上界为polynomial多项式时,可以很明确右边是收敛的,因此bad data的概率有一个收敛的上界。仅使用2N 作为其上界是不够的

为了将上界继续向下压缩,我们定义一个概念break point,其含义为对于某个H,如果在N=k上,对所有可能的N大小的数据集均有
mH(k)<2k
称k为假设集H的break point,显然对于k+1,k+2,....它们也是H的break point,因此最主要的是要找到最小break point
对于Perceptron,由之前的知识可知,其break point 为k=4
L6
接下来以最小break point 为2的H作为例子,显然当N=2时,应该有
mH(2)<22,即有mH(2)<=3
当N进一步增加的时候,由于要满足数据集的每个子集也符合mH(2)<22的条件(即每两个组合最多有三种不同的情形),mH(3)的最大值为4(由枚举法易得)
由此,似乎使用break point的概念是有可能找到一个polynomial的mH(N)的一般表达式的
在此引入bounding function的概念,其定义为在N=k处mH(N)的上界,即我们现在所寻求的东西。其表达形式在这里为B(N,k)。到此,需要证明B(N,k)的上界为某个多项式。
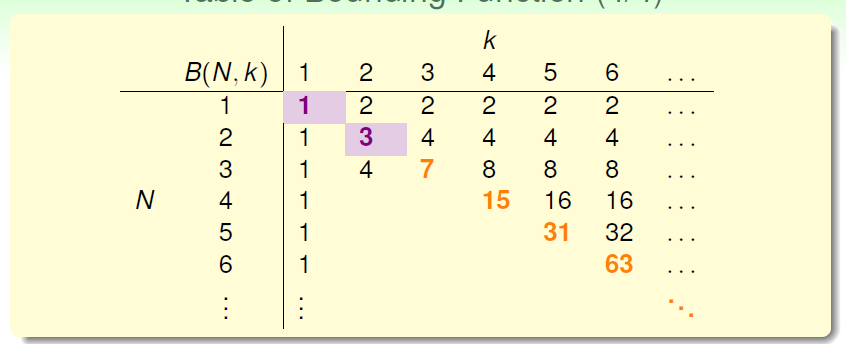
如图,由break point的定义我们很容易得到N-k和B(N,k)表格中对角线上的值和右上三角形部分的值。
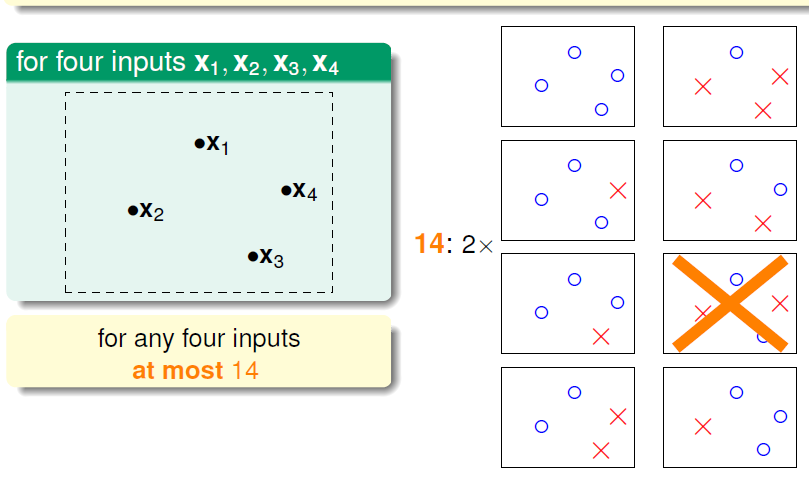
接下来以例子推导下三角部分的值,以B(4,3)(N=4,k=3)为例子
显然有B(3,3)=7。在考虑到其N=3的子集不能有7种以上不同结果的情况下,最终得出的所有组合如右下:

将这些结果分组可以分为两组,其中一组新加入的数据点可以有两种可能结果,另一种只能有一种可能结果(这里排除的N=3的情况为全x,beta类中的第一个的x4应该更正为o)。
显然在这里有以下关系式:
B(4,3)=11=2alpha+beta
而考虑到alpha类型需要x4能产生两种结果,那么在alpha类型中就不能有一个以上的x。也就是说,alpha的左边子集中的,在N=2时其最多有三种不同的可能性。因此,k=2算是其break point,我们有
alpah<=B(3,2)
而显然,alpha类型和beta类型在一起为N=3的所有子集类型,其大小有
alpha+beta<=B(3,3)=7
最后将以上式子代入B(4,3)的表达式,我们有
B(4,3)<=B(3,3)+B(3,2)
容易将其推广到所有N,k,最后我们得到
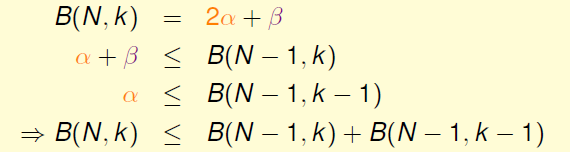
从而有
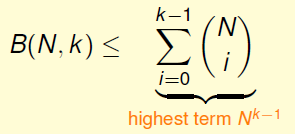
这就是一个N的多项式,最高项为k-1次
在以上过程中我们的前提假设集能进行分类,而分类的前提是数据集有限。而对于我们要推广的Eout ,如果对它进行计算,数据集实际上是无限的,因此需要以下步骤进行推导。这里和课程都仅展示推导的大致步骤:

首先使用另外一个同样大小的集合的E'in和Ein的距离来代替原先Ein和Eout的距离,从而可以使用bound function
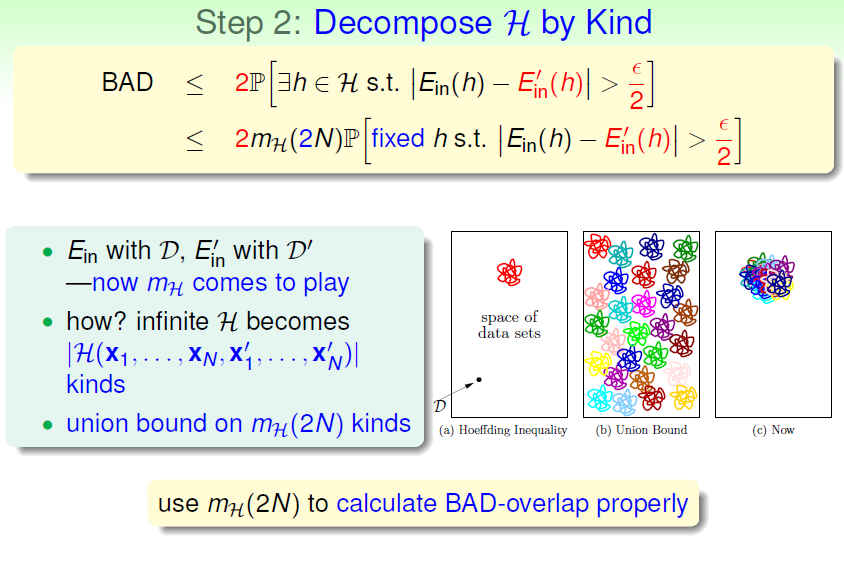
然后类似之前的推导,将无限大小的H替换为最小的可替代H,从而使用growth function

最后再将两个值使用霍夫丁不等式替换,从而得到最后的概率上界表达式
最后的结果如下:
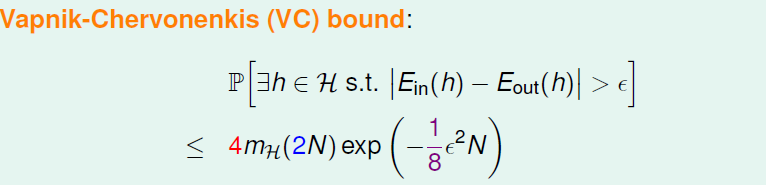
以上就是数据集大小与训练集结果v.s.泛化结果的一个表达式
总结:
在假设集大小M->无穷时,如果训练集N数量有限,我们可以使用一个最小假设集H来替代原先M->无穷的假设集。
这个最小假设集的大小我们称为growth function mH(N)。显然对大小为N的训练数据集,我们有mH(N)<=2N 。
通过观察,可以看到,在大多数假设集中,growth function在某个训练集大小N=k时开始有,对所有这个大小的训练集均mH(N)<2N 。其中mH(k)<2k 的点定义为break point,而最小的那个点则为最小的break point(此后仅将这个点称为break point 进行讨论)。由于mH(N)的大小显然与break point有关系,因此引入bounding function B(N,k)作为growth function的上界。
通过一系列观测和讨论我们最终可以得出growth function的上界bounding fucntion B(N,k)有
而该上界即为growth function的上界。通过这一个上界我们可以将原本无限的假设集数量等效为一个有上界的关系式,并且显然这是一个多项式,能使之前的不等式收敛。
然而该上界的使用要求是样本集是有限的。因此在实际的上界VC-bound推导中使用Ein与另外一个大小相同的数据集得出的E'in的差距来代替Ein和Eout的差距。通过这两次替换最终得出对于任意假设集的关于Ein与Eout的差距的边界的不等式
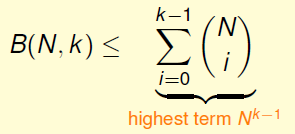














 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









