







场景
1.经常在Windows, MacOSX 开发C多线程程序的时候, 经常需要和线程打交道, 如果开发人员的数量不多时, 同时掌握Win32和pthread线程
并不是容易的事情, 而且使用Win32线程并不能写出跨平台的实现. 所以在成本的制约下选用pthread作为跨平台线程库的首选. 有足够人力的公司可以再封装一层对Win32和本地pthread的调用. 比如 chrome.
2.线程在做高可用, 高性能的程序时必不可少, 比如Socket, 并发任务, 顺序任务,文件下载等需要充分利用CPU资源节省执行时间的编码上起着至关重要的作用. 没有多线程的话, 再处理后台任务,多任务上会更麻烦一些, 当然可以使用协程, 但那个并不灵活和常见.
3.学习一门线程模型, 最让人关心的就是到底在什么场景下需要用到线程, 这种POSIX 线程模型还能怎么用?
介绍
1.POSIX 线程, 通常称作pthreads, 是独立于语言的执行模型, 也是一个并行执行模型. 它允许程序在重叠的时间控制不同的工作流. 每一个工作流被称作线程, 同时创建和控制这些流程的工作是通过POSIX Threads API来实现的. POSIX Threads 的API定义是通过标准的
POSIX.1c, Threads extensions (IEEE Std 1003.1c-1995).
2.API的实现在所有的Unix-like系统里都有,比如 FreeBSD, NetBSD, OpenBSD, Linux, Mac OS X and Solaris, 对于Windows系统, 在 SFU/SUA 子系统里提供了一组POSIX APIs的实现, 并且有第3方库 pthread-w32, 它是基于存在的Windows API 实现的.
说明
1.《Programming with Posix Threads》 这本书介绍了3种模型(Pipeline,Work Crew,Client/Server). 我们有必要分析下, 虽然现实场景比这些更复杂, 但是他们组成了基础, 掌握了更多的基础才能组成复杂的房屋设计, 可以说是一种设计模式.
2.新学习这个pipeline模型, 还没在实际项目中使用, 所以没有很好的例子, 暂时用官方例子说明, 当然这个例子实在过于简单. 但是简单也正好记住它的原理.
管道(Pipeline)
说明
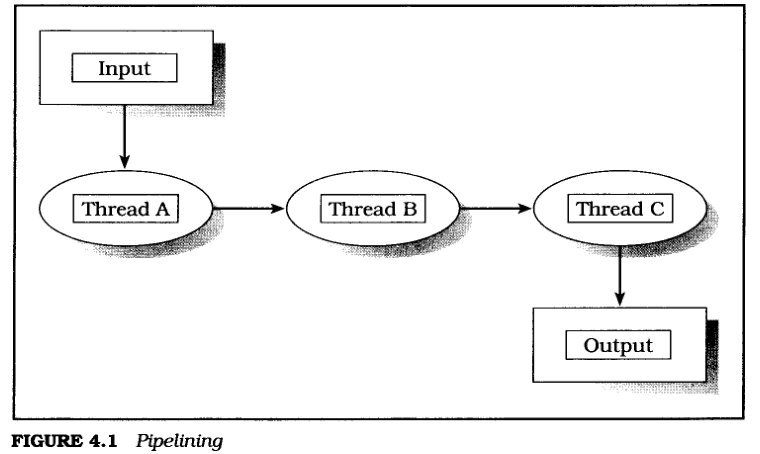
每个线程重复执行在序列集合里的相同的操作, 并传递每个线程的输出到另一个线程执行下一个步骤, 可以称作为流水线.
特点
- 每个线程就像一个生产特定部件的机器, 它只生产某个部件, 不做其他事情.
- 这个线程一直在做这个事情, 不会停止, 有材料时会一直生产完, 生产一个部件就会传递到下一个线程.
- 它属于一个流水线中一部分, 每个步骤都是有顺的, 适合处理有序的数据流.
例子:
一个图片文件, 线程A 负责读取这个图片到数组, 线程B 负责搜索图片数组里的某些特定数据, 线程C 负责搜集线程B搜索到的流式数据到报表里.
或者 线程A,B,C 在一个有序序列里分别对数据进行处理.
注: 看到这里有人会问, 没必要3个线程啊, 用1个线程处理也行阿. 我们想想线程的作用, 节省时间, 充分利用CPU资源实现并发.假如数据分析总共需要9分钟时间, 有10个这样的任务, 单线程就需要90 分钟. 如果是3个线程, 每个线程处理一部分3分钟的数据. 总共需要
3*10+2 = 32 分钟. 性价比很高吧.
代码例子
pipe.c :
1.每个在管道里的线程对它的输入值+1, 并传递到下一个线程. 主程序从stdin读入一系列命令行. 1个命令行或者是一个数字, 这个数字注入到管道的开始. 或者字符 “=.” 它会让程序从管道末尾读入下一个结果并把它输出到stdout. 主函数创建管道, 并且循环从stdin里读入行数据. 如果行数据是一个单一 “=” 字符. 它会从管道拉取一个值并且打印他们, 否则它会转换行为一个整数值
/*
* The main program to "drive" the pipeline...
*/
int main (int argc, char *argv[])
{
pipe_t my_pipe;
long value, result;
int status;
char line[128];
pipe_create (&my_pipe, 10);
printf ("Enter integer values, or \"=\" for next result\n");
while (1) {
printf ("Data> ");
if (fgets (line, sizeof (line), stdin) == NULL) exit (0);
if (strlen (line) <= 1) continue;
if (strlen (line) <= 2 && line[0] == '=') {
if (pipe_result (&my_pipe, &result))
printf ("Result is %ld\n", result);
else
printf ("Pipe is empty\n");
} else {
if (sscanf (line, "%ld", &value) < 1)
fprintf (stderr, "Enter an integer value\n");
else
pipe_start (&my_pipe, value);
}
}
}2.管道里的每个stage使用一个stage_t类型变量表示. stage_t包含一个mutex来同步访问这个stage. avail条件变量用来发送给stage表明数据已经准备好可以处理了, 同时每个阶段拥有一个条件变量ready来表明它准备接收新的数据了. data 成员变量是前一个stage传递来的, thread是操作这个stage的线程, next 是指向下一个stage的指针.
3.pipe_t 结构体描述了一个管道. 它提供指针指向管道阶段的第一和最后一个stage. 第一个stage, head代表了管道里的第一个线程. 最后一个stage, tail是一个特别的stage_t, 它没有线程– 因为它只是用来存储管道的最后数据.
/*
* Internal structure describing a "stage" in the
* pipeline. One for each thread, plus a "result
* stage" where the final thread can stash the value.
*/
typedef struct stage_tag {
pthread_mutex_t mutex; /* Protect data */
pthread_cond_t avail; /* Data available */
pthread_cond_t ready; /* Ready for data */
int data_ready; /* Data present */
long data; /* Data to process */
pthread_t thread; /* Thread for stage */
struct stage_tag *next; /* Next stage */
} stage_t;
/*
* External structure representing the entire
* pipeline.
*/
typedef struct pipe_tag {
pthread_mutex_t mutex; /* Mutex to protect pipe */
stage_t *head; /* First stage */
stage_t *tail; /* Final stage */
int stages; /* Number of stages */
int active; /* Active data elements */
} pipe_t;4.pipe_send, 这个函数用来开始管道传输, 并且也是被每个stage调用来传递data到下一个stage里. 它首先开始等待指定的stage的ready 条件变量直到它能接收新的数据(之前的数据没处理完). 存储新的数据值, 同时告诉stage数据已经准备好.
/*
* Internal function to send a "message" to the
* specified pipe stage. Threads use this to pass
* along the modified data item.
*/
int pipe_send (stage_t *stage, long data)
{
int status;
status = pthread_mutex_lock (&stage->mutex);
if (status != 0)
return status;
/*
* If there's data in the pipe stage, wait for it
* to be consumed.
*/
while (stage->data_ready) {
status = pthread_cond_wait (&stage->ready, &stage->mutex);
if (status != 0) {
pthread_mutex_unlock (&stage->mutex);
return status;
}
}
/*
* Send the new data
*/
stage->data = data;
stage->data_ready = 1;
status = pthread_cond_signal (&stage->avail);
if (status != 0) {
pthread_mutex_unlock (&stage->mutex);
return status;
}
status = pthread_mutex_unlock (&stage->mutex);
return status;
}5.pipe_stage是管道里每个stage的开始函数, 这个函数的参数就是指向stage_t结构体的指针. 这个线程永远循环执行处理数据. 因为 mutex在循环外被locked, 线程看起来好像一直锁定stage的 mutex对象, 然而, 它是花费大多数时间来等待新的数据, 通过avail条件变量. 注意这个线程自动解锁关联到条件变量的mutex. 当data获取到数据, 线程自增数据值, 同时传递结果到下一个stage. 接着线程清除data_ready变量值来表明不再有数据, 同时发信号给ready条件变量来唤醒那些正在等待这个管道stage就绪的线程.
注意: 这个stage在处理数据时并没有解锁stage的mutex,也就是如果在处理耗时的操作时一直是锁住的. 只要data_ready不设置为0之前,可以在处理耗工作前解锁, 处理完耗时的工作之后再加锁设置 data_ready = 0.
/*
* The thread start routine for pipe stage threads.
* Each will wait for a data item passed from the
* caller or the previous stage, modify the data
* and pass it along to the next (or final) stage.
*/
void *pipe_stage (void *arg)
{
stage_t *stage = (stage_t*)arg;
stage_t *next_stage = stage->next;
int status;
status = pthread_mutex_lock (&stage->mutex);
if (status != 0)
err_abort (status, "Lock pipe stage");
while (1) {
while (stage->data_ready != 1) {
status = pthread_cond_wait (&stage->avail, &stage->mutex);
if (status != 0)
err_abort (status, "Wait for previous stage");
}
pipe_send (next_stage, stage->data + 1);
stage->data_ready = 0;
status = pthread_cond_signal (&stage->ready);
if (status != 0)
err_abort (status, "Wake next stage");
}
/*
* Notice that the routine never unlocks the stage->mutex.
* The call to pthread_cond_wait implicitly unlocks the
* mutex while the thread is waiting, allowing other threads
* to make progress. Because the loop never terminates, this
* function has no need to unlock the mutex explicitly.
*/
}6.pipe_create函数创建一个管道, 它能创建任意个stage, 并连接他们成为一个链表. 对于每个stage, 它分配内存给stage_t 结构体并且初始化成员. 注意最后一个stage是被分配和初始化来保存管道最后的结果. 注意最后一个stage并不创建线程.
注意: 这里的链表操作方法,不需要额外的判断.
/*
* External interface to create a pipeline. All the
* data is initialized and the threads created. They'll
* wait for data.
*/
int pipe_create (pipe_t *pipe, int stages)
{
int pipe_index;
stage_t **link = &pipe->head, *new_stage, *stage;
int status;
status = pthread_mutex_init (&pipe->mutex, NULL);
if (status != 0)
err_abort (status, "Init pipe mutex");
pipe->stages = stages;
pipe->active = 0;
for (pipe_index = 0; pipe_index <= stages; pipe_index++) {
new_stage = (stage_t*)malloc (sizeof (stage_t));
if (new_stage == NULL)
errno_abort ("Allocate stage");
status = pthread_mutex_init (&new_stage->mutex, NULL);
if (status != 0)
err_abort (status, "Init stage mutex");
status = pthread_cond_init (&new_stage->avail, NULL);
if (status != 0)
err_abort (status, "Init avail condition");
status = pthread_cond_init (&new_stage->ready, NULL);
if (status != 0)
err_abort (status, "Init ready condition");
new_stage->data_ready = 0;
*link = new_stage;
link = &new_stage->next;
}
*link = (stage_t*)NULL; /* Terminate list */
pipe->tail = new_stage; /* Record the tail */
/*
* Create the threads for the pipe stages only after all
* the data is initialized (including all links). Note
* that the last stage doesn't get a thread, it's just
* a receptacle for the final pipeline value.
*
* At this point, proper cleanup on an error would take up
* more space than worthwhile in a "simple example", so
* instead of cancelling and detaching all the threads
* already created, plus the synchronization object and
* memory cleanup done for earlier errors, it will simply
* abort.
*/
for ( stage = pipe->head;
stage->next != NULL;
stage = stage->next) {
status = pthread_create (
&stage->thread, NULL, pipe_stage, (void*)stage);
if (status != 0)
err_abort (status, "Create pipe stage");
}
return 0;
}7.pipe_start和pipe_result函数. pipe_start函数入栈一个data数据到管道的开始stage并且迅速返回,不等待结果. pipe_result函数允许请求者等待最终的结果. pipe_start 函数递增pipeline里的active计数, 这个active允许pipe_result探测没有更多的active项需要收集, 同时迅速返回不阻塞. pipe_result 首先检查是否有一个active项在管道里. 如果没有, 它返回status为0, 之后解锁pipeline的mutex. 如果有另一个item在管道里, pipe_result锁定tail stage,并且等待它接收数据. 它复制数据并且重置tail stage以便能接收下一个数据项.
/*
* External interface to start a pipeline by passing
* data to the first stage. The routine returns while
* the pipeline processes in parallel. Call the
* pipe_result return to collect the final stage values
* (note that the pipe will stall when each stage fills,
* until the result is collected).
*/
int pipe_start (pipe_t *pipe, long value)
{
int status;
status = pthread_mutex_lock (&pipe->mutex);
if (status != 0)
err_abort (status, "Lock pipe mutex");
pipe->active++;
status = pthread_mutex_unlock (&pipe->mutex);
if (status != 0)
err_abort (status, "Unlock pipe mutex");
pipe_send (pipe->head, value);
return 0;
}
/*
* Collect the result of the pipeline. Wait for a
* result if the pipeline hasn't produced one.
*/
int pipe_result (pipe_t *pipe, long *result)
{
stage_t *tail = pipe->tail;
long value;
int empty = 0;
int status;
status = pthread_mutex_lock (&pipe->mutex);
if (status != 0)
err_abort (status, "Lock pipe mutex");
if (pipe->active <= 0)
empty = 1;
else
pipe->active--;
status = pthread_mutex_unlock (&pipe->mutex);
if (status != 0)
err_abort (status, "Unlock pipe mutex");
if (empty)
return 0;
pthread_mutex_lock (&tail->mutex);
while (!tail->data_ready)
pthread_cond_wait (&tail->avail, &tail->mutex);
*result = tail->data;
tail->data_ready = 0;
pthread_cond_signal (&tail->ready);
pthread_mutex_unlock (&tail->mutex);
return 1;
}术语
SFU (Windows Services for UNIX)
SUA (Interix subsystem component Subsystem for UNIX-based Applications)
参考
https://en.wikipedia.org/wiki/POSIX_Threads
https://en.wikipedia.org/wiki/Windows_Services_for_UNIX
Programming with POSIX Threads
















 3827
3827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











