









最近一段时间在研究 linux 的内核,linux 内核中的代码十分的精炼,无论出于什么目的来学习它,都会有很多的收获。
但是,看代码与写代码虽说都需要大量的脑力参与其中,但是,二者的等级绝对不同。怎么各不同?就相当于我们在
学习的时候,知道一个函数应该如何的使用 与 这个函数的内部结构是什么样的,在不参照其他人代码的情况下自己
编写相同功能的函数应该如何实现一样。
所以,对于学习内核的方法是这样的:
首先,将内核中实现的方法/函数进行封装,写到自己的程序中,然后通过不同参数的
传递来慢慢熟悉这个函数的功能是什么样的。(知其然)
然后,在仔细的阅读所熟悉功能的函数内部实现中是怎样处理
如此之多的功能的。(知其所以然)
但是,这两个过程确实等同重要的,也就是说不能够从第一个阶段直接跨越到第二个阶段,也不能够将认知仅仅停留在第一个阶段。
========================================================
本篇文章主要是为今后进行第一个阶段进行一些铺垫,主要介绍的就是,
如何在自己的程序中使用内核中实现的库函数,在这里仅仅举一个简单的小例子来说明。
实验目的:
在自己编写的程序中引用内核中的库函数
实验环境:
gcc 4.4.7,
linux -centos
实验思想:
通过 Makefile 和 导出符号表的方式来将内核模块动态的加载到用户自行编译的程序中,
实质上是使用类似于驱动模块的形式加载内核的方法。
也就是根据用户编写的程序需要来动态的将内核中的实现代码抽取出来进行编译成目标文件。
实验代码:
实验代码主要分为3个部分: hello.c myFunc.h myFunc.c
和一个 Makefile
其中 hello.c 中会调用 myFunc.c 中所实现的函数 void sayHello ( void )
并且为了表明,在执行上述操作之后真的可以在当前用户自行编写的程序中使用kernel 中的变量,
我们在程序中定义了一个位于 include/linux/list.h 中所定义的 struct list_head 变量,它也将会是
后续文章中主要介绍的对象,所以在这里先做一下铺垫与测试。
在 myFunc.h myFunc.c 中分别是 sayHello 方法的定义与实现,在这里之所以写上子函数调用
是为了学习在后续编写复杂调用的时候,主方法是如何对位于其他文件中的子函数的编译等处理问题。
//hello.c
#include <linux/module.h>
#include <linux/init.h>
#include <linux/list.h>
#include "myFunc.h"
static int __init hello_init ( void )
{
printk(KERN_EMERG"hello linux internal world \n") ;
sayHello( ) ;
struct list_head myList ;//no error ,when compiling
return 0 ;
}
static void __exit hello_exit ( void )
{
printk(KERN_EMERG"bye ,see you \n") ;
}
module_init (hello_init) ;
module_exit (hello_exit) ;
MODULE_LICENSE("GPL") ;
MODULE_AUTHOR("inuyasha1027") ;
MODULE_VERSION("1.0") ;
//myFunc.h
#ifndef __MYFUNC_H__
#define __MYFUNC_H__
void sayHello(void) ;
#endif
//myFunc.c
#include <linux/module.h>
void sayHello ( void )
{
printk(KERN_EMERG"emm hi , i am inuyasha \n nice to meet you !" ) ;
}
EXPORT_SYMBOL(sayHello) ;
MODULE_LICENSE("GPL") ;~
//Makefile
obj-m := hello.o myFunc.o
all:
$(MAKE) -C /lib/modules/$(shell uname -r)/build M=$(shell pwd) modules
clean:
$(MAKE) -C /lib/modules/$(shell uname -r)/build M=$(shell pwd) clean下面介绍的是在代码编写之后,如何对其进行编译与运行
首先,makefile 已经编写好了,那么我们来输入 make 来进行编译
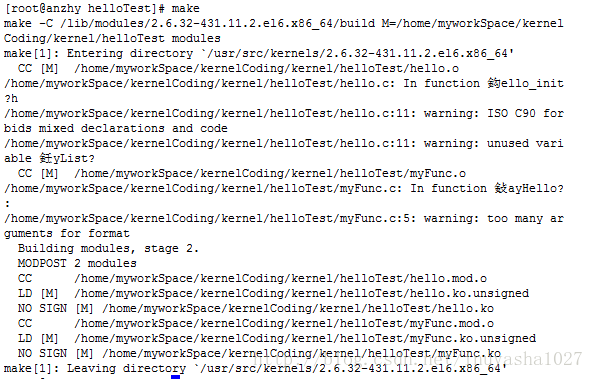
编译好了之后,我们将会在当前目录下面看到有许多的目标文件,其中我们所需要的就是 1. hello.ko 2.myFunc.ko
我们所熟知的有 .so ----》shared object ,是linux 中的共享库,同样也被称作动态库。
所以对于 .ko 文件来说,从其英文名称上来入手,ko ===> kernel object ,也就是内核模块的意思,
它可以动态地加载到系统中运行的内核中,也可以动态地从其中(运行的内核)进行卸载。
那么我们就来对其进行加载以下吧,对于将 .ko 文件加载到内核的命令是 insmod ,
而将 .ko 文件从内核中卸载的命令是 rmmod ,不过加载和卸载的顺序是有一定要求的。 由前面的代码实现可知,
hello.c 中调用了 myFunc.c 中实现的函数,那么在编译之后所生成的 hello.ko 文件中一定会依赖 myFunc.ko 。
所以,应该首先加载 myFunc.ko , 然后在加载 hello.ko 才可以得到正确的输出。
同样,如何知道某一个内核模块 *.ko 已经被内核所加载了呢? 查询的命令有很多种,其中比较常用的有
1. ps -ef | grep myFunc
2. cat /proc/kallsyms | grep myFunc
3. lsmod | grep myFunc
任何一种方法都可以, 因为我们并没有在 myFunc 中写入在运行的时候输出的提示信息,所以需要通过
系统命令来查看它是否在运行,以及运行状态相关的信息。
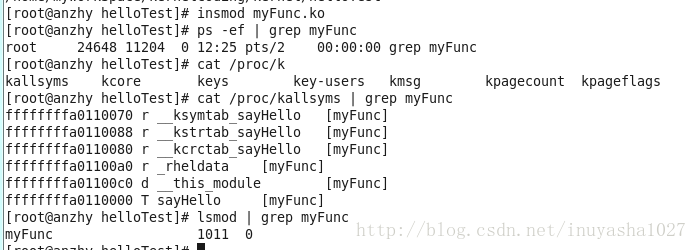
接下来,我们使用同样的方法,在 myFunc 被加载到内核中的基础之上,将 hello.ko 加载到内核中
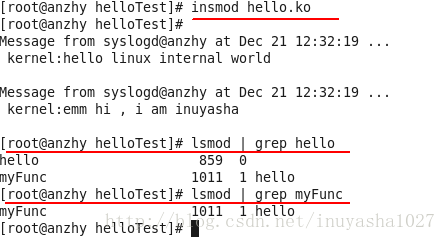
通过再次输入命令 lsmod | grep myFunc 可以看到 hello 这个模块已经类似于挂载的关系依附于其之上,这也是为什么
在将 myFunc hello 内核模块从内核中卸载下来的时候,需要首先将 hello 模块卸载下来,然后在卸载 myFunc 的原因。
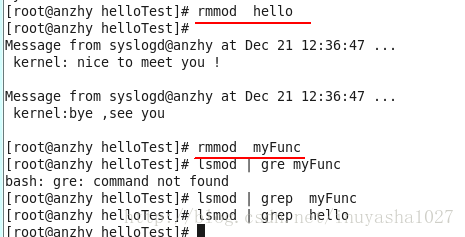
实验不足与改进:
这个实验中有一个地方和我预先想到的输出有所不同,在 hello 中打印信息的时候多加了一个换行符号
\n 没有想到信息竟然没有一次性全部输出,这个可能与 printk 函数的属性有关,也就是说 作为 printf
的兄弟的printk 在每次向屏幕输出的时候,是需要向内核请求一个缓冲区来存放将要输出的内容的,
这样长长的一句话可能由于分配的缓冲区的不同而被多次输出,而内核或许将 \n 这一换行符号,默许是
分配缓冲区结束的一个标志,这样后半句话就会在前一句输出之后,清空缓冲区,然后装载后一句话,
然后将后一句话输出,这才导致了,换行符号的后半句话在将 hello 模块从内核中卸载下来之后才显示
到屏幕上面的原因吧。(经过后续的实验证实,这个想法是错误的)
不过具体的原因还不是很清楚,但是之所以知道它是错的是因为:在执行 insmod *.ko
模块加载的时候,所加载的仅仅是零零散散的 目标文件,而非最终我们想要实现全局功能的hello.o
真正最终起到全局功能的就是 hello.o , 也就是通过 ismod hello.o 可以将全部的信息(无论是否有 \n 等等)
不过它的运行之前,是必须要通过 ismod myFunc.ko ismod hello.ko 这些内核加载命令的基础之上才能够正确运行的。
printk 中还需要知道一点就是,在输出的字符串信息前面中是需要加上各种内核中定义的宏变量所代表输出信息的不同等级的,
如果等级过低则不会输出,那么在控制台上看不到写入方法中本应显示的信息的。 这里我们使用的是最高等级,
紧急状态 : KERN_EMERG 就可以在屏幕上看到写入程序中的字符了。
后续实验主要是围绕 list hlist















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









