









此文是斯坦福大学,机器学习界 superstar — Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记。力求简洁,仅代表本人观点,不足之处希望大家探讨。
课程网址:https://www.coursera.org/learn/machine-learning/home/welcome
Week 10:
Big Data
海量的数据作为训练样本,“low bias algo + big data”基本都能让算法精确度更高。但是随之而来的就是极大的计算量。正如《专题【Machine Learning Advice】》(http://blog.csdn.net/ironyoung/article/details/48491237)中所提到的,如果算法是 high bias,那么1000个样本与100,000,000个样本效果都不会有变化
那如何避免一开始就陷入了 high bias 或者因为自己的选择的方法、编程的细节错误所浪费大量时间呢?我们应该在海量数据中选取一部分尝试。例如,随机选择 100,000,000个样本中的1000个,使用各种学习方法选择在这1000个采样学习中表现最好的一个或几个方法,进行海量数据的学习
尝试之后,我们即将进行真正的海量数据学习。学习过程中,我们经常会用到梯度下降法。我们以线性回归为例(任何使用到梯度下降法的算法:逻辑回归、神经网络等,都可以举一反三适用),参数 θ 的update函数为:
θj:=θj−α1m∑i=1m((hθ(x(i))−y(i))∗x(i)j)
公式推导内容见《专题【Linear Regression】》(http://blog.csdn.net/ironyoung/article/details/47129523)上式中有一处求和 ∑i=1m ,面对海量数据时会消耗大量时间,而且对每一个样本都会计算一次。这种计算模式称为“批处理”(batch),面对海量数据,显然批处理模式并不适合。以下介绍两种海量数据模型中经常使用的方法
随机梯度下降(Stochastic Gradient Descent)
介绍随机梯度下降方法之前,我们引入一个新的表达式: cost(θ,(x(i),y(i)))=12(hθ(x(i))−y(i))2 这代替了原本的 J(θ) 成为新的代价函数
根据新的代价函数,我们会得到新的参数 θ 的update函数:
θj:=θj−α(hθ(x(i))−y(i))∗x(i)j
仔细观察这个update函数,是不是发现求和过程没有了?
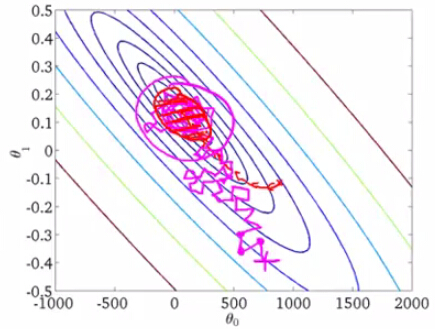
批处理中,参数的改变需要当前所有样本共同作用,达到整体最优。但是随机方法中,每次仅关注当前单个样本的最优作用。这种做法会导致最优值的反复,但是却极大提高了效率随机梯度下降的具体流程为:
因为随机梯度下降会导致最优值的反复,所以有时上图中的 Repeat 会进行1~10次。而且随机梯度下降方法的收敛是随机的,只能保证逐渐向最优值徘徊,而不会真正到达最优值。例如下图:
如果我们希望达到最优值,应该怎么办呢?可以通过逐渐缩小学习步长 α ,以求最终的收敛范围逐渐减小到最优值。可以使用:
α=const#iterations+const 来逐渐缩小学习步长
小规模批处理(Mini-batch)
有没有方法兼顾批处理方法,与随机梯度下降方法的优势?就是Mini-batch Gradient Descent。基本思想是:不是批处理的每次处理所有样本,也不是随机方法每次单个样本,而是每次处理b个样本( 1<b≪m )
假设有1000个样本,b=10。算法的具体执行过程为:
实际计算中,小规模批处理方法,可能会比随机梯度下降方法更快!因为不同组的b个样本可以进行并行计算(一次并行m个样本计算量太大)。但这种方法多引入了一个参数b,需要更多的调试,算是个缺点
Big Data 判断收敛
批处理方法中,如何判断算法是否收敛?绘制 “ Jtrain(θ)−#iterations ” 的走势图(见《专题【Linear Regression】》http://blog.csdn.net/ironyoung/article/details/47129523), Jtrain(θ) 是基于所有样本的和。走势逐渐降低即为收敛
随机梯度下降方法中,再去计算所有样本的 Jtrain(θ) 显然不合适,我们转而记录 cost(θ,(x(i),y(i))) 。例如,每1000个样本各自的 cost(θ,(x(i),y(i))) 求和后平均,记录这个平均误差后再更新 θ 。最后,绘制“平均误差”与迭代次数的关系图。因为收敛是随机的,可能出现噪声,只要保证整体趋势是逐渐下降的即为收敛
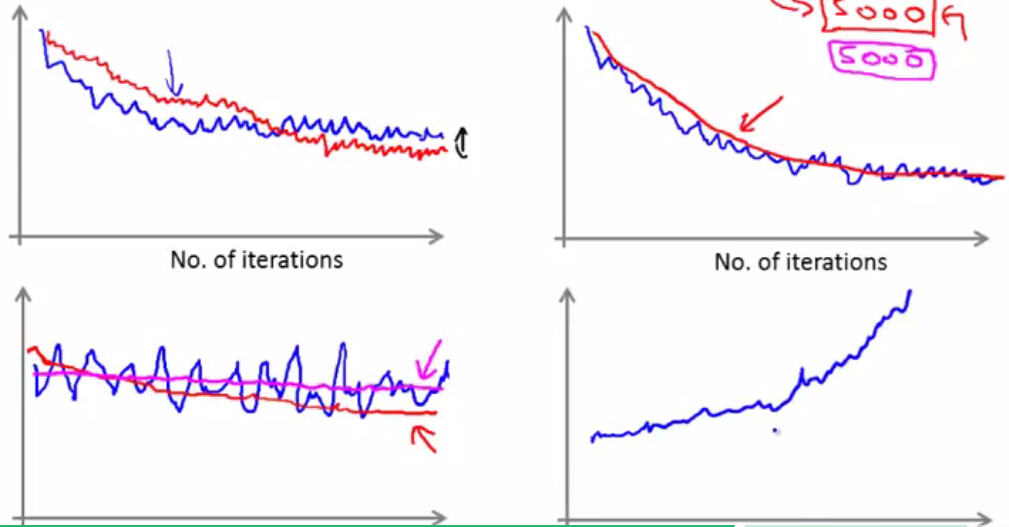
接下来我们看一下以下几种“平均误差”与迭代次数的关系图,看看有什么问题:
- 左上角的图是一种收敛的情况,但是红色曲线的 α 更小,虽然学习速度较慢,但是却收敛到更接近最优值的区域(更小误差)
- 右上角的图是一种收敛的情况,其中红色曲线的取“平均误差”的范围更大,是5000个样本取一次,所以噪声更少更平滑
- 左下角的图,因为蓝色曲线噪声过大,看不出是否收敛,建议增大取“平均误差”的范围
- 右下角的图,抱歉,完全不收敛。建议使用更小的 α 再尝试,如果还是不收敛就可能需要选择其他的算法或者增加特征?
Online Learning
试想一种场景:一家新闻网站不断根据不断涌入的新用户的喜好以及老用户的兴趣改变,来定义头条新闻的内容,是不是还要保存这种海量数据呢?这需要极大的空间,并且每次都基于所有样本进行学习,那么学习的时间还赶不上产生新样本的时间
如果使用随机梯度下降方法,每次仅仅关注当前样本的梯度下降,并且同一个样本仅学习一次(上文“随机梯度下降”流程图中 Repeat 次数为1),是不是就能解决这个问题。这就是online learning
online learning 思想可以适用于无限的数据流,尤其适用于不断更新中的互联网大数据上的机器学习算法。并且,这种方法对于新事物有着极强的适应性,因为每次更新都是基于当前样本,历史样本的作用随着迭代的进行会逐渐失去。因此非常适用于互联网大数据的实时更新
Data Parallelism
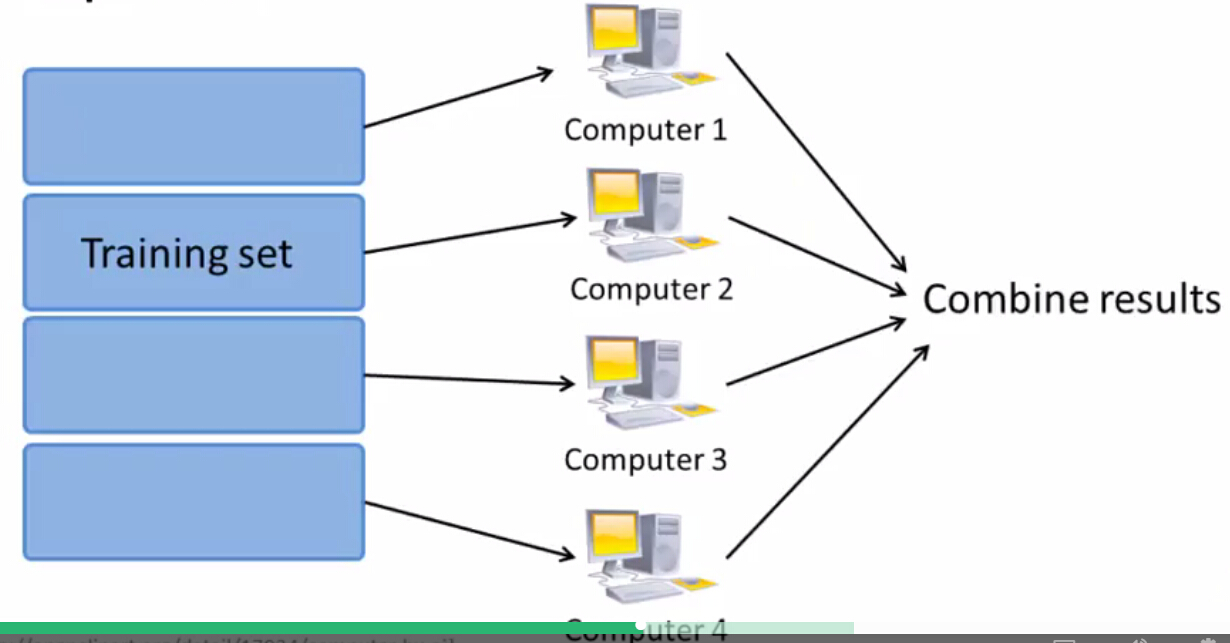
最后一部分是对于并行计算的简介。试想一下,如果我要求4亿个样本某个特征的和,仅在一台机器上求是很慢的。但是,如果我将它分散在四台机器上求解,最后使用一台机器汇总这四台机器的求解结果,是不是快了很多?除去数据传输耗费的时间,是不是快了接近4倍?其中,分散的过程我们称为Map,而汇总的过程我们称为Reduce
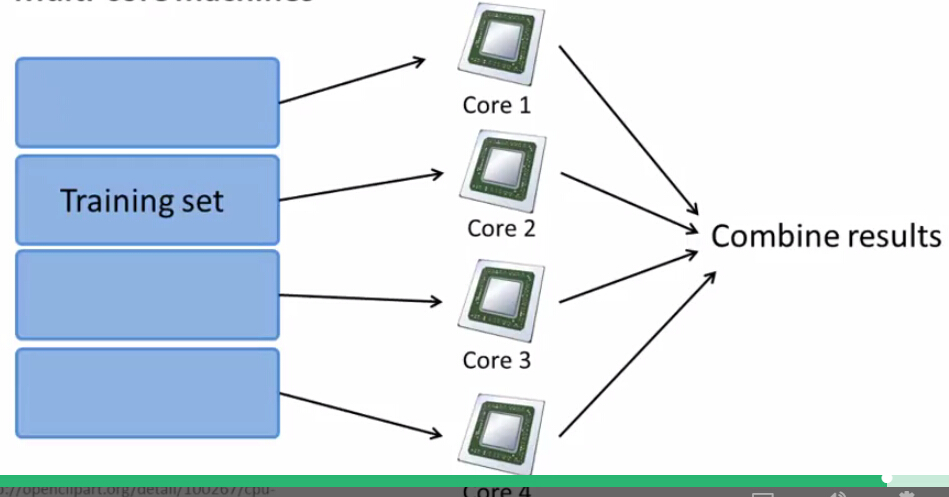
不仅对于多台机器,同一台机器如果有着多个计算核(CPU),同样可以适用。形象化的示意图如下:
本节仅仅举了加法求和的例子。但实际情况中,只要是无数据相关性的计算,也就是前一部分的计算结果不作为后一部分的计算输入,两个部分的计算是彼此独立的,都可以并行计算
















 3016
3016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









