








kafka是一个分布式的,高吞吐量的、信息分片存储,消息同步复制的开源消息服务,它提供了消息系统的功能,但是采用了独特的设计。
kafka最初由LinkedIn设计开发,使用Scala语言编写,用作LinkedIn网站的活动流数据和运营数据处理工具,这其中活动流数据是指页面访问量、被查看内容方面的信息以及搜索情况等内容,运营数据是指服务器的性能数据(CPU、IO使用率、请求时间、服务日志等数据)。
现在kafka已被多家不同类型的公司采用,作为其内部各种数据的处理工具或消息队列服务。如今kafka捐献给了apache软件基金组织,成为apache下的一个开源项目。
下面我们来温习一下消息系统的基本要素:
1、topic:kafka维护的一个叫topic的消息主题;
2、producer:我们将消息发布到kafka的topic上,发布消息的进程也叫生产者producer;
3、consumer:我们从kafka的topic上订阅消息,订阅消息的进程叫消费者consumer;
4、broker:kafka运行在由一个或多个服务器构成的集群上,集群中的每一台服务器被称为broker。(broker的意思为:经纪人、居间人、代理人)
所以从宏观上来看,生产者(producer)通过网络发布消息到kafka集群(cluster),kafka集群再为消费者(consumer)提供消息服务,他们的处理流程如下图所示:
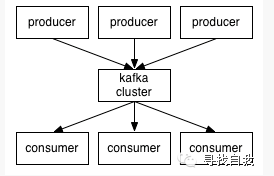
生产者、消费者与kafka的broker服务器之间通过TCP协议通信。kafka提供了多种语言客户端Java、C/C++、python、php、ruby、.net、scala、erlang等,用于与kafka交互。
我们将消息的发布(publish)叫做生产者producer,将消息的订阅(subscribe)叫做消费者consumer,将中间的存储服务叫做broker,这个broker就是我们的kafka服务器,生产者通过推模式将数据推到kafka服务器broker,消费者通过拉模式从kafka服务器broker拉取数据,它们如下图所示:
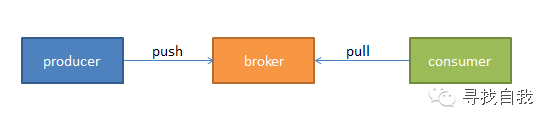
需要注意的是,消费者是自己主动从broker拉取数据,而broker不会主动把数据发送到消费者。
对于在实际应用中,生产者、消费者和kafka的broker一般集群部署,多个producer、consumer和broker之间协同合作,通过zookeeper协调管理,构成了一个高性能的分布式消息发布与订阅系统,在一个集群中,它们的结构如下图所示:
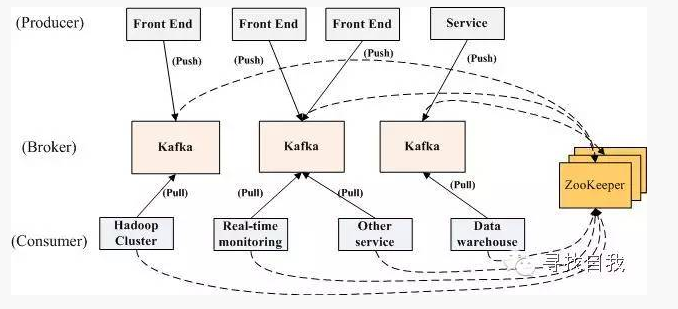
构成的整个分布式消息系统将按照如下的流程运行:
1、启动zookeeper
2、启动kafka的broker
3、编写客户端Producer生产数据,通过zookeeper找到broker,然后将数据存入broker
4、编写客户端Consumer消费数据,通过zookeeper找对应的broker,然后从broker消费消息。
以上我们对kafka有了一个概括性的描述,让我们从宏观上认识了kafka是什么以及其基本工作原理,接下来我们再详细看看kafka涉及到的几个主要要素都有些什么特点:
Topic,高级别抽象的kafka提供者,一个topic是一个目录或消息名,消息将被发送到topic,对于每个topic,kafka维持一个分片日志(partitioned log),如下图所示为一个topic的解剖图:
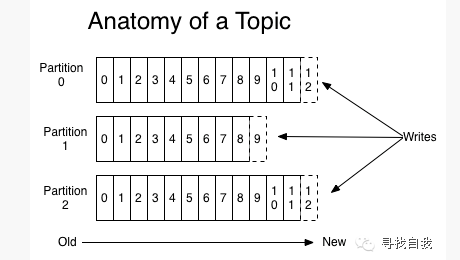
每一个分片日志都是有序的、不可变的消息系列,新的消息不断地添加到分片日志的末尾,在这个分片日志中,每个消息被分配一个连续的id号叫offset,它唯一地定义了一个消息。
在一个配置的时间内,kafka集群一直保留着所有发布的消息,不管这些消息有没有被消费。比如被设置保留两天,那么一个消息被发布后的两天时间内,消息都是可以被消费的,两天之后消息将被丢弃以释放空间。
kafka中进行partitions设计有多个原因,首先,通过partition可以使log文件的大小不会超过单台机器的文件容量限制,一个topic可以有多个partitions,因此可以存储任意数量的数据。其次,可以提升并发消费的能力,一个topic的partitions可以被分布在kafka集群中的多台机器上,每台机器上的kafka实例负责该机器上分片数据的请求和操作,每个分片可以配置被复制的份数,从而复制到集群中的其他机器上,以提升高可用性。
每个partition有一个server作为leader,0个或者多个server作为followers,leader处理所有的读写请求,followers复制leader进行消息同步,如果一个leader发生故障,followers中会自动有一个follower变成新的leader。
生产者把消息发送到他们选择的topics中,producers还能指定发送到topic的哪个partition中,你可以通过round-robin或者其他算法来决定把消息发送到哪个partition中。
传统的消息系统有两种模式:
一种是基于队列Queue的点对点消息。
一种是基于主题Topic的发布与订阅消息。
基于队列的点对点消息只能被一个消费者消费,而基于主题的发布与订阅消息能被多个消费者消费。kafka抽象了这两种模式,它采用consumer group名称来处理这两种模式,可以将消费者分成多个group,每个consumer属于一个单独的consumer group,也可以多个consumer属于同一个group。
如果采用基于队列的点对点消息,则每个消费者都需要位于同一个group中,如果采用基于主题的发布订阅消息,则每个消费者都要位于不同的group中。
在更多的情况下,我们的主题topic中会包含几个consumer group,每个consumer group都是一个logical subscribe,每个group包含了多个consumer实例,这样更具扩展性和容错性。kafka有比传统消息系统更强健的订阅机制。
kafka在较高的层次上提供了如下保证:
1、生产者producer发送到topic partition中的消息会被顺序的追加到日志中;
2、消费者consumer消费消息的顺序和消息在日志中的顺序一致;
3、如果一个topic有N份复制,则我们可以允许N-1台服务故障而不会丢失任何消息。
kafka的一些常用应用场景:
1、消息系统:替换传统的消息系统,解耦系统或缓存待处理的数据,kafka有更好的吞吐量,内置了分片、复制、容错机制,是大规模数据消息处理的更好的解决方案。
2、网站活动跟踪:网站的访问量,搜索量,或者其他用户的活动行为如注册,充值,支付,购买等行为可以发布到中心的topic,每种类型可以作为一个topic,这些信息流可以被消费者订阅实时处理、实时监控或者将数据流加载到Hadoop中进行离线处理等。
3、度量统计:可以用于度量统计一些运维监控数据,将分布式的一些监控数据聚集到一起。
4、日志聚合:可以作为一个日志聚合的替换方案,如Scribe、Flume。
5、数据流处理:可以对数据进行分级处理,将从kafka获取的原始数据进行加工润色后再发布至kafka。
6、事件溯源:可以以时间为顺序记录应用事件的状态变化,从而为事件溯源。
7、提交日志:可以作为分布式系统的外部日志存储介质。














 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









