









获取网络数据
在上一节,我们已经通过模拟数据,并将UI展示出来。这节我们将获取网络数据。数据来源于网络,仅用于学习使用。
fetch介绍
fetch是react native的一个网络请求库,使用该库不用引入模块,可以直接使用。一个简单的请求如下:
fetch('http://facebook.github.io/react-native/movies.json')发起请求之后,我们还需要对它的响应进行处理,只要这样
fetch('http://facebook.github.io/react-native/movies.json')
.then((response)=>{
console.log(response)
}
)
.catch((e)=>{
console.log(e)
}
)在浏览器中打开调试工具,在Console下输入以上代码:
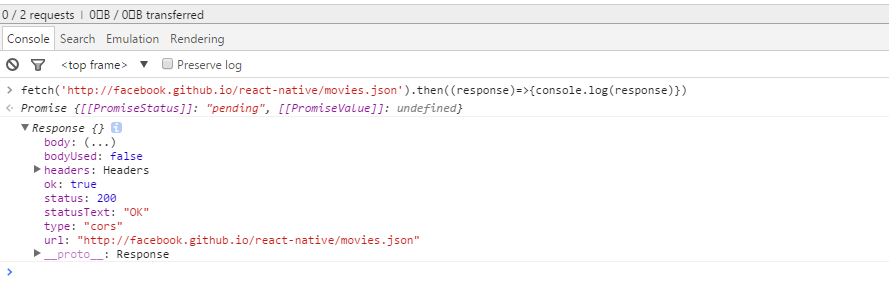
从上图可以看出fetch返回的数据对象Response包含body、headers、status等。
Response常用的两个函数是
json() - 返回一个JSON格式.
text() - 返回一个文本.
fetch还可以构造复杂一点的
fetch('https://mywebsite.com/endpoint/', {
method: 'POST',
headers: {
'Accept': 'application/json',
'Content-Type': 'application/json',
},
body: JSON.stringify({
firstParam: 'yourValue',
secondParam: 'yourOtherValue',
})
})可以配置请求的方法method,头部headers和body。
上面的请求都是异步的,也可以使用同步操作,如下
async getMoviesFromApi() {
try {
let response = await fetch('http://facebook.github.io/react-native/movies.json');
let responseJson = await response.json();
return responseJson.movies;
} catch(error) {
console.error(error);
}
}整个方法是异步的,但是内部的fetch请求是同步的,使用await 会等待fetch返回结果response再执行下一步。记得try catch任何异常。
更多fetch相关,可以查看官方文档
使用fetch获取数据
打开DramaComponent.js文件,定义一个方法fetchData
fetchData(){
var url = 'http://www.y3600.com/hanju/new';
fetch(url)
.then((res)=> res.text())
.then((html)=>{
console.log(html);
})
.catch((e)=>{
console.log(e);
}).done();
}
//在最初的render方法调用之后立即调用。
//网络请求、事件订阅等操作可以在这个方法中调用。
//作用相同与Fragment生命周期中的onViewCreate方法。
componentDidMount(){
this.fetchData();
}这样我们就获取到网页html数据,接下来我们要解析html获取想要的数据。使用到的解析库是cheerio。
使用cheerio解析html获取影视信息
cheerio属于第三方模块,我们要使用它首先要先把它安装到我们的项目中来。
cheerio依赖events模块,所以events也要安装进来。不知道依赖关系也没事,在你运行程序的时候,它就会提示你缺少了哪个module,再安装下就可以了。
使用命令行cd到我们的跟目录下,然后执行命令
npm install cheerio --savenpm install events --save等待安装完毕之后,在DramaComponent.js中引入该模块
import Cheerio from 'cheerio';然后将html加载到cheerio解析器里,利用cheerio API进行数据提取,通读cheerio API。
var $ = Cheerio.load(html);我们要分析提取的网站地址是http://www.y3600.com/hanju/new。打开该网站,右击查看网页源代码,先自己静态分析下,该如何通过html标签获取筛选到数据。
通过分析,我们发现影片列表信息存放在class为m-ddone的div标签下,并且ul的每一li标签代表一部影片,然后继续分析下去获取每一部的详细信息即可,这里就不再详细分析了。我们声明一个方法来解析这一个过程,代码如下:
//解析html
resolveHtml(html){
var $ = Cheerio.load(html);
var body = $('div.m-ddone').find('ul');//ui
var datas = [];//影视列表数据集合
body.each((index,item)=>{//li
var dramaItem ={
name:'',//影片名称
title:'',//标题
actor:'',//演员
pic:'',//图片地址
url:'',//详情链接
};
var link = $(item).find('a');
link.each((i,a)=>{//获取影片名称
var aTag = $(a);
if(i===0){
dramaItem.pic = aTag.find('img').attr('src');
dramaItem.url = aTag.attr('href');
dramaItem.title = aTag.find('label.tit').text();
}else if(i===1){
dramaItem.name = aTag.text();
}
});
var actor = $(item).find('li.zyy').text();
dramaItem.actor = actor;
//
datas.push(dramaItem);
});
//最后记得刷新一下数据
this.setState({
movies:this.state.movies.cloneWithRows(datas),
});
}然后在刚才fetchData那里获取到的html传递和调用resolveHtml就可以了。
fetchData(){
var url = 'http://www.y3600.com/hanju/new';
fetch(url)
.then((res)=> res.text())
.then((html)=>{
//console.log(html);
this.resolveHtml(html);
})
.catch((e)=>{
console.log(e);
}).done();
}ok,刷新一下界面,现在已经获取到数据并显示了,如下
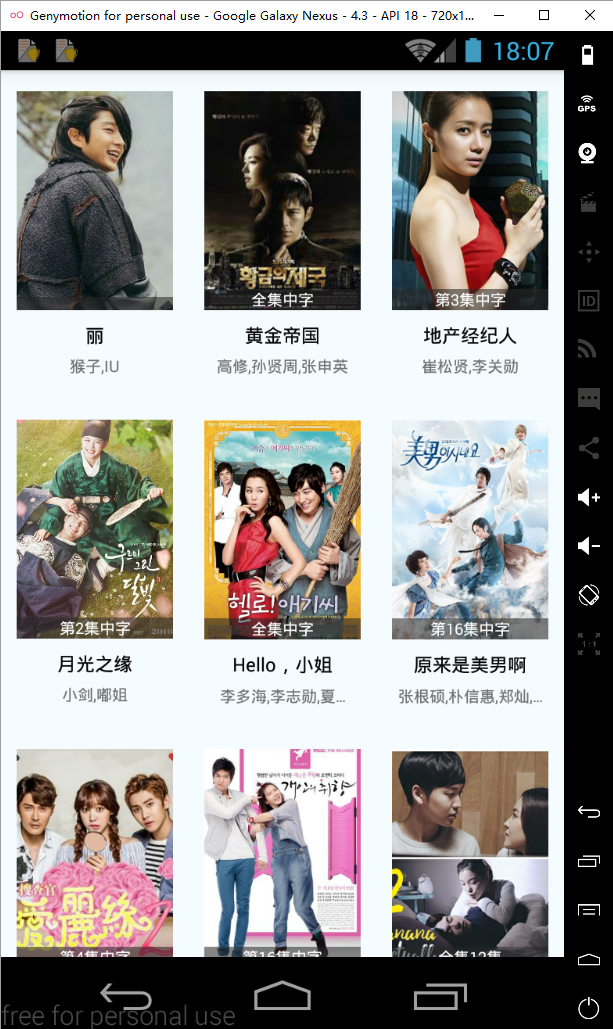
上拉加载更多
然后,你会发现,怎么好像只有一页的数据。嗯,没错,我们还要优化一下,让数据和ListView支持分页功能。
我们在多分析下网站的源代码,需要的信息有:总页数、当前页、下一页的链接地址,因此,我们的数据结构修改定义为,如下:
dramaList:{
totalPage:1,//总页数
currPage:0,//当前页
pages:[],//页码信息
datas:[],//影片信息列表数据
}此时,constructor方法内
constructor(props) {
super(props);
this.state = {
movies:new ListView.DataSource({
rowHasChanged:(r1,r2) => r1!=r2,
}),
dramaList:{
totalPage:1,//总页数
currPage:0,//当前页
pages:[{index:1,url:'http://www.y3600.com/hanju/new'}],//页码信息
datas:[],//影片信息列表数据
},
}
}由于我们初始访问的是http://www.y3600.com/hanju/new 这个地址,因此初始化时页码信息也给初始化第一页数据。
解析页码信息的关键代码如下:
//解析页码信息
var page = $('div.pages').find('a');
page.each((i,item)=>{
if(!$(item).hasClass('next')){
dramaList.totalPage++;
dramaList.pages.push({
index:$(item).text(),
url:$(item).attr('href'),
});
}
});dramaList就是this.state.dramaList,因此数据结构改变了,我们也要把之前的datas字段改为dramaList.datas。所以此时resolveHtml方法的完整代码如下:
//解析html
resolveHtml(html){
var $ = Cheerio.load(html);
var dramaList = this.state.dramaList;
//解析剧集列表
var body = $('div.m-ddone').find('ul');//ui
body.each((index,item)=>{//li
var dramaItem ={
name:'',//影片名称
title:'',//标题
actor:'',//演员
pic:'',//图片地址
url:'',//详情链接
};
var link = $(item).find('a');
link.each((i,a)=>{//获取影片名称
var aTag = $(a);
if(i===0){
dramaItem.pic = aTag.find('img').attr('src');
dramaItem.url = aTag.attr('href');
dramaItem.title = aTag.find('label.tit').text();
}else if(i===1){
dramaItem.name = aTag.text();
}
});
var actor = $(item).find('li.zyy').text();
dramaItem.actor = actor;
//
dramaList.datas.push(dramaItem);
});
//解析页码信息
dramaList.currPage++;
var page = $('div.pages').find('a');
page.each((i,item)=>{
if(!$(item).hasClass('next')){
dramaList.totalPage++;
dramaList.pages.push({
index:$(item).text(),
url:$(item).attr('href'),
});
}
});
//刷新一下数据
this.setState({
movies:this.state.movies.cloneWithRows(dramaList.datas),
dramaList:dramaList,
});
}由于每一页的html解析过程都一样,所以我们改造一下fetchData方法,让它传入一个url地址
,url参数化。
fetchData(url){
url = HOST_URL+url;
....//省略其它代码
}HOST_URL是一个const,是该网站的根地址http://www.y3600.com
然后还记得在介绍ListView的时候,有个方法_onEndReached是在它拉到底部会调用,是的,我们就在这个方法下去,加载下一页,实现如下:
_onEndReached(){
var dramaList = this.state.dramaList;
var totalPage = dramaList.totalPage;
var currPage = dramaList.currPage;
var nextPage = currPage+1;
if(nextPage <= totalPage){
this.fetchData(dramaList.pages[currPage].url);
}
}记得ListView的onEndReached要调用bind(this),否则_onEndReached的this.state.dramaList会报undefined异常
最后,在componentDidMount改下调用方法
componentDidMount(){
var url = '/hanju/new';
this.fetchData(url);
}重新执行下代码,就可以看到分页效果了,如果/hanju/new地址的数据没有分页,你可以把url改为其他,比如‘人气’页/hanju/renqi/,它们的解析过程都一样的。
写完加载更多,还有下拉刷新呢!下面我们就来讲讲下拉刷新。
下拉刷新
ListView有个refreshControl来设置刷新的状态,效果和android的SwipeRefreshLayout一样。需要额外在’react-native’ import RefreshControl组件,代码如下:
import{
.....//省略其它代码
RefreshControl,
}from 'react-native';
//刷新
_onRefresh(){
}
<ListView
dataSource = {this.state.movies}
renderRow = {this._renderMovieView.bind(this)}
style = {styles.listview}
initialListSize = {10}
pageSize = {10}
onEndReachedThreshold = {5}
onEndReached = {this._onEndReached.bind(this)}
enableEmptySections = {true}
contentContainerStyle = {styles.grid}
refreshControl = {
<RefreshControl
refreshing = {this.state.isRefreshing}
onRefresh = {this._onRefresh.bind(this)}
colors = {['#f74c31', '#f74c31', '#f74c31','#f74c31']}
progressBackgroundColor = '#ffffff'
/>
}
/>RefreshControl内有个refreshing布尔值属性,我们需要通过state来设置这个是否正在刷新的状态。
constructor(props) {
super(props);
this.state = {
movies:new ListView.DataSource({
rowHasChanged:(r1,r2) => r1!=r2,
}),
dramaList:{
totalPage:1,//总页数
currPage:0,//当前页
pages:[{index:1,url:'http://www.y3600.com/hanju/new'}],//页码信息
datas:[],//影片信息列表数据
},
isRefreshing:false,//RefreshControl是否正在刷新
}
}接着,我们要处理刷新逻辑。当下拉刷新时,要将列表数据清空,初始化到最初的状态。在resolveHtml里添加如下代码:
resolveHtml(html){
var $ = Cheerio.load(html);
var dramaList = this.state.dramaList;
if(this.state.isRefreshing){
dramaList.currPage = 0;
dramaList.datas = [];
}
//解析剧集列表
....//省略其它代码
//刷新一下数据
this.setState({
movies:this.state.movies.cloneWithRows(dramaList.datas),
dramaList:dramaList,
isRefreshing:false,
});
}解析完数据之后,将isRefreshing状态置为false,在刷新回调的方法里fetch初始的地址
//刷新
_onRefresh(){
this.setState({
isRefreshing: true
});
this.fetchData('/hanju/new');
}组件参数化
上面我们已经将DramaComponent组件的数据获取解析全部实现了,但是我们解析的这个地址是固定写死的,这样一来这个组件就不能提供给别的组件重复使用了,所以我们要将这个地址参数化,由外部调用该组件的时候传入,具体实现如下。
组件的参数是通过props设置的,我们通过propTypes定义一个string类型的url,还可以通过defaultProps设置默认初始值。
static propTypes = {
url:React.PropTypes.string.isRequired,
}static defaultProps = {
url: '/hanju/new',
}PropType有入下图这些类型
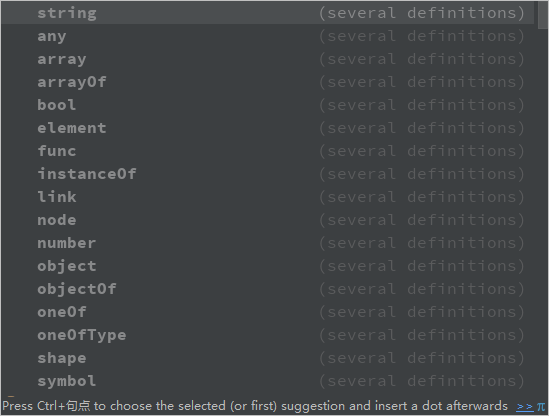
其中常用到的string\any\array\bool\func\number 关于PropType介绍
接着,将初始的url都替换成this.props.url。两个地方要修改,一个是constructor里的state初始数据,和componentDidMount调用的fetchData
constructor(props) {
super(props);
this.state = {
movies:new ListView.DataSource({
rowHasChanged:(r1,r2) => r1!=r2,
}),
dramaList:{
totalPage:1,//总页数
currPage:0,//当前页
pages:[{index:1,url:this.props.url}],//页码信息
datas:[],//影片信息列表数据
},
isRefreshing:false,//RefreshControl是否正在刷新
}
}
componentDidMount(){
this.fetchData(this.props.url);
}最后,我们打开程序入口index.android.js,给组件DramaComponent设置一个url值
class XiFan extends Component {
render(){
return(
<DramaComponent url='/hanju/new'/>
);
}
}
AppRegistry.registerComponent('XiFan', () => XiFan);如果你组件没有设置url参数,并且组件内没有defaultProps,那么由于DramaComponent组件把url设置成了isRequired(必填参数),因此你运行之后会收到一个黄色警告。

最后再给这个组件优化一下(养成编写代码边思考边优化的习惯!),两点:
- 在组件请求网络并解析数据时,给它一个loading界面,加载完成后再显示结果页面。
- 由于fetchData方法是内部重复循环调用,但是并不是每次都需要去解析页码信息的,只有第一次没有数据的时候要去解析获取页码数据。
state增加loaded和hasPage参数
constructor(props) {
super(props);
this.state = {
movies:new ListView.DataSource({
rowHasChanged:(r1,r2) => r1!=r2,
}),
dramaList:{
totalPage:1,//总页数
currPage:0,//当前页
pages:[{index:1,url:this.props.url}],//页码信息
datas:[],//影片信息列表数据
hasPage:false,//是否有分页
},
isRefreshing:false,//RefreshControl是否正在刷新
loaded:false,//是否初始加载完成
}
}增加加载中页面和逻辑
//加载中页面
_renderLoadingView(){
return(
<View style = {{flex:1,justifyContent:'center',alignItems:'center'}}>
<Text>加载中,请稍后...</Text>
</View>
);
}
render(){
if(!this.state.loaded){
return this._renderLoadingView();
}
return(
<ListView
...//省略其它代码
/>
);
}修改解析页码逻辑,并设置loaded状态
//解析html
resolveHtml(html){
...//省略其它代码
//解析页码信息
dramaList.currPage++;
if(!dramaList.hasPage) {
dramaList.hasPage = true;
var page = $('div.pages').find('a');
page.each((i, item)=> {
if (!$(item).hasClass('next')) {
dramaList.totalPage++;
dramaList.pages.push({
index: $(item).text(),
url: $(item).attr('href'),
});
}
});
}
//刷新一下数据
this.setState({
movies:this.state.movies.cloneWithRows(dramaList.datas),
dramaList:dramaList,
isRefreshing:false,
loaded:true,
});
}OK!本节的内容就讲完了。如果要完整的代码,可以查看 我的github
总结
本节,完成了一个自定义组件的构建过程,并抽象成一个公共组件。下一节,我们将利用该组件完成首页的功能,涉及到的内容是TitleBar、选项卡、ViewPagerAndroid等。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









