







当今社会各种应用系统诸如商业、社交、搜索、浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战:
- 如何收集这些巨大的信息
- 如何分析它
- 如何及时做到如上两点
以上几个挑战形成了一个业务需求模型,即生产者生产(produce)各种信息,消费者消费(consume)(处理分析)这些信息,而在生产者与消费者之间,需要一个沟通两者的桥梁-消息系统。所从一个微观层面来说,这种需求也可理解为不同的系统之间如何传递消息。Kafka就是可以解决此类问题的一个消息系统,它实现了生产者和消费者之间的无缝连接。
一、简介
Kafka是由LinkedIn开发的一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。这种动作(如网页浏览、搜索和其他的用户行动)是在现代网络上许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。Kafkade的主要特性如下所示:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
二、原理
1.kafka的架构
Kafka是显式分布式架构,整体架构非常简单,含有三大组件分别为:Producer、Consumer、broker ,producer、broker(kafka)和consumer都可以有多个。Producer,consumer实现Kafka注册的接口,数据从producer发送到broker,broker承担一个中间缓存和分发的作用。broker分发注册到系统中的consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单、高性能、且与编程语言无关的TCP协议。Kafka架构图如下所示:
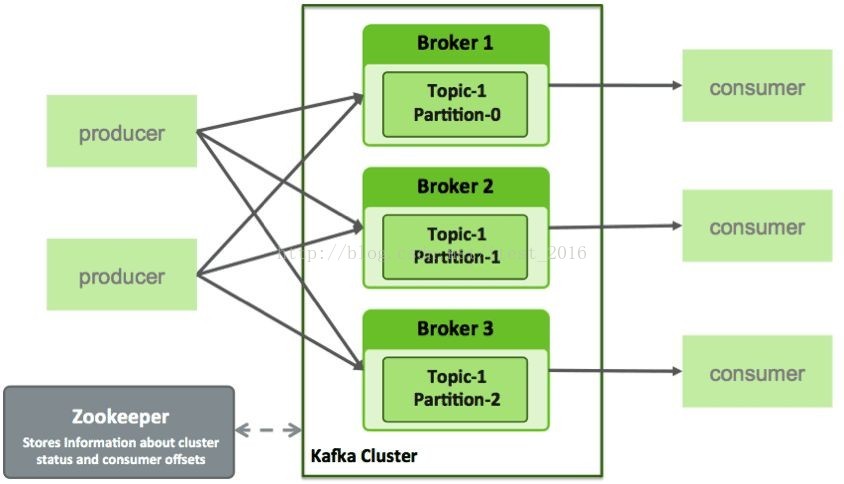
上图提供了一个最基本的kafka架构,生产者(producers)发布一个消息(message)到Kafka的一个主题(topic),这个主题(topic)即是由扮演Kafka Server角色的broker提供,消费者(consumers)订阅这个主题(topic),然后从broker把消息提取(pull)出来消费(consume)。
- Broker:Kafka集群包含一个或多个服务器,这种服务器称为broker;
- Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition;
- Producer:负责发布消息到Kafka broker;
- Consumer:消费者,向Kafka broker读取消息的客户端;
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定groupname,若不指定groupname则属于默认的 group)。
- Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户不必关心数据存于何处,只需指定消息的Topic即可生产或消费数据)。Topic的结构图如下:
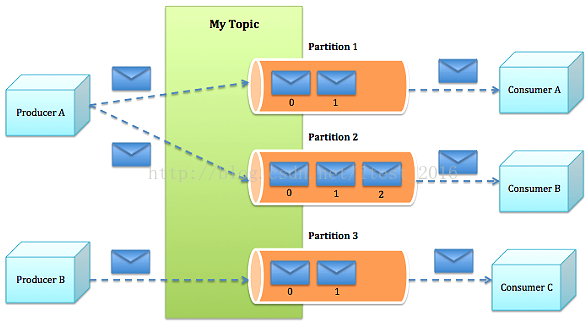
Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费,Consumer从kafka集群pull数据,并控制获取消息的offset。
2.性能特点
Kafka使用文件存储消息,这就直接决定kafka在性能上严重依赖文件系统的本身特性。且无论任何OS下,对文件系统本身的优化几乎没有可能。文件缓存/直接内存映射等是常用的手段。因为kafka是对日志文件进行append操作,因此磁盘检索的开支是较小的;同时为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。
需要考虑影响到kafka性能点的因素很多,除磁盘IO之外,我们还需要考虑网络IO,这直接关系到kafka的吞吐量问题。kafka并没有提供太多高超的技巧;对于producer端,可以将消息buffer起来,当消息的条数达到一定阀值时,批量发送给broker;对于consumer端也是一样,批量fetch多条消息。
不过消息量的大小可以通过配置文件来指定。对于kafkabroker端,似乎有个sendfile系统调用可以潜在的提升网络IO的性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次copy和交换。 其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略;压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。可以将任何在网络上传输的消息都经过压缩。kafka支持gzip/snappy等多种压缩方式。
三、使用场景
下面介绍以下kafka的使用场景,主要从7方面介绍。
1.消息队列
比起大多数的消息系统来说,Kafka有更好的吞吐量、内置的分区、冗余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统一般吞吐量相对较低,但是需要更小的端到端延时,并常常依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如ActiveMR或RabbitMQ。
2.行为跟踪
Kafka的另一个应用场景是跟踪用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控,或放到hadoop/离线数据仓库里处理。
3.元信息监控
作为操作记录的监控模块来使用,即汇集记录一些操作信息,可以理解为运维性质的数据监控吧。
4.日志收集
日志收集方面,其实开源产品有很多,包括Scribe、ApacheFlume。很多人使用Kafka代替日志聚合(logaggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟。
5.流处理
这个场景可能比较多,也很好理解。保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始topic来的数据进行阶段性处理,汇总,扩充或者以其他的方式转换到新的topic下再继续后面的处理。例如一个文章推荐的处理流程,可能是先从RSS数据源中抓取文章的内容,然后将其丢入一个叫做“文章”的topic中;后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返还给用户。这就在一个独立的topic之外,产生了一系列的实时数据处理的流程。Strom和Samza是非常著名的实现这种类型数据转换的框架。
6.事件源
事件源是一种应用程序设计的方式,该方式的状态转移被记录为按时间顺序排序的记录序列。Kafka可以存储大量的日志数据,这使得它成为一个对这种方式的应用来说绝佳的后台。比如动态汇总(Newsfeed)。
7.持久性日志
Kafka可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka类似于ApacheBookKeeper项目。
Kafka主要是用来解决百万级别的数据中生产者和消费者之间数据传输的问题,同时可以将一条数据提供给多个接收者做不同的处理。Kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力。目前,Kafka以其可水平扩展和高吞吐率的特性而被广泛使用。















 7258
7258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









